Headroom: The Open-Source Compression Tool That Cuts AI Agent Token Costs by 10x

Open-source tool Headroom compresses AI agent inputs to cut token costs by up to 95%.
Headroom, open-sourced by Netflix engineer Tejas Chopra, is a proxy-based compression tool that sits between AI coding tools and LLM APIs. It uses intelligent content-type detection — AST parsing for code, statistical compression for logs, semantic compression for text — to achieve 60%-95% token savings. Its reversible breadcrumb mechanism ensures no information is permanently lost, and it complements output-compression tools like Caveman for maximum cost reduction.
When you use AI coding tools like Claude Code or Codex, have you ever noticed how every tool call burns through tokens at an alarming rate? A simple log file read can consume tens of thousands of tokens, most of which is noise. Tejas Chopra, a Senior Engineer at Netflix, open-sourced a tool called Headroom that intelligently compresses content before the LLM reads it, achieving 60%-95% token savings while maintaining output quality.
What Problem Does Headroom Solve?
If you've used AI coding assistants like Claude Code, you know how expensive they can be. Every tool call can return massive amounts of JSON logs, the vast majority of which is noise — the truly valuable information may only be a tiny fraction. Yet all of this content gets stuffed into the context window — and that's exactly what you're paying for.
To understand the severity of this problem, you need to grasp the basic logic of token economics. Tokens are the fundamental billing unit for large language models. Take Claude 3.5 Sonnet as an example: input tokens cost $3 per million and output tokens cost $15 per million; the Opus model is even pricier at $15 and $75 respectively. A typical JSON log file might contain thousands of lines of repetitive structures, each broken down into multiple tokens by the tokenizer. When an AI coding tool makes dozens of tool calls in a single session, the cumulative token consumption can easily reach hundreds of thousands or even millions, with a single session potentially costing over $10.
This is especially true when you use the UltraCode mode with the Opus model, which dynamically creates parallel sub-agents with no token cap — costs can spiral out of control quickly. UltraCode is an advanced execution mode in Claude Code that allows the main agent to dynamically spawn multiple parallel sub-agents to handle different subtasks simultaneously. For example, when refactoring a large project, the main agent might dispatch one sub-agent to analyze dependencies, another to modify test files, and a third to update documentation. Each sub-agent has its own independent context window and tool-calling permissions, meaning token consumption grows multiplicatively. While the uncapped design improves task completion quality, it also makes costs unpredictable.
Headroom's core idea is simple: compress the content before it reaches the LLM.
How Headroom Works
Intelligent Content Detection and Category-Based Compression
Headroom doesn't simply truncate text — it applies different compression strategies based on content type:
- JSON arrays: Retains outliers and edge cases, discards repetitive normal data
- Code files: Performs code-aware compression by parsing the actual syntax tree (AST)
- Build logs: Keeps only failure information, discards passing test results
- Plain text: Uses a self-trained local model called CompressBase for semantic compression
This category-based compression design is remarkably clever — it understands the "information density distribution" of different content types and precisely retains high-value information.
The AST compression for code files deserves a deeper look. AST (Abstract Syntax Tree) is an intermediate representation where the compiler frontend converts source code into a tree-like data structure. By parsing the AST, Headroom can understand the syntactic structure of code — distinguishing function signatures, comments, implementation details, and import statements. This means it can intelligently preserve function signatures and key logic while omitting verbose implementation bodies or repetitive boilerplate code. Compared to simple line-count truncation, AST-aware compression ensures semantic integrity — it won't break in the middle of a function or lose critical type information.
Reversible Compression: The Breadcrumb Mechanism for Lossless Fallback
Headroom's most ingenious design is its reversibility. After each compression, it leaves a "breadcrumb" in the compressed text — a marker containing a hash value. When the model determines the compressed information isn't sufficient, it can request the full original data using this hash.
This breadcrumb mechanism draws from the content-addressable storage concept in distributed systems. During each compression, Headroom computes a hash of the original content (similar to Git's SHA mechanism), stores the complete data in a local cache, and embeds a marker like [HEADROOM:abc123] in the compressed output. When the LLM determines during inference that it needs more detail, it can reference this marker in its output, and the proxy server intercepts the request and returns the full original data. This design transforms compression from an irreversible operation into an on-demand reversible one, achieving a dynamic balance between information preservation and token savings.

Architecture: Proxy Server Mode Requires No Code Changes
Headroom runs as a Python proxy server, sitting between your application (e.g., Claude Code) and the API server (e.g., Anthropic). When tool call results come back, the proxy uses an underlying Rust engine for compression, then sends the compressed version to the API. This means you don't need to modify your existing code's core logic — just point your requests to the Headroom proxy.
A proxy server is a classic middleware architectural pattern that intercepts and processes communication traffic between client and server. In Headroom's case, it works as a transparent proxy: the client (e.g., Claude Code) sends API requests to the local proxy port, the proxy forwards requests to the Anthropic API, compresses tool call results from the response, and returns them to the client. The advantage of this architecture is zero intrusiveness — no need to modify the AI tool's source code or API call logic; you only need to change the API endpoint address in your environment variables. The choice of a Rust engine is to achieve near-zero latency in the compression processing step, ensuring the proxy layer doesn't become a bottleneck for response speed.
Real-World Results: Token Savings Data
Log Analysis Scenario: 98% Token Savings
In a test involving reading server logs and analyzing root causes of errors, Headroom demonstrated impressive compression results. The original logs contained massive amounts of repetitive info-level entries. Headroom used statistical compression to condense 419 similar info logs into a single summary line, saving over 17,000 tokens with a 98% compression rate.
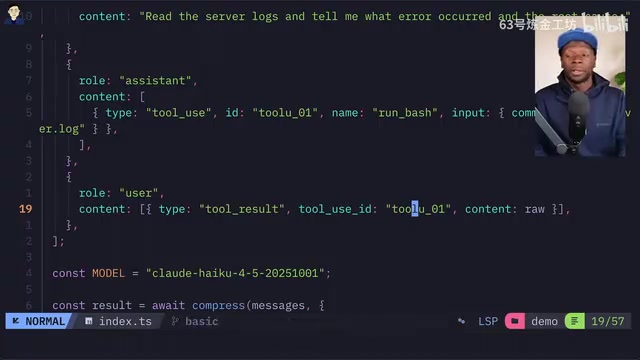
The compressed tool response retained only critical error messages and anomaly patterns, along with hash markers for retrieving the full data. Interestingly, on the first run the model determined the information was insufficient to complete the task, but on the second run it was able to provide a complete analysis.
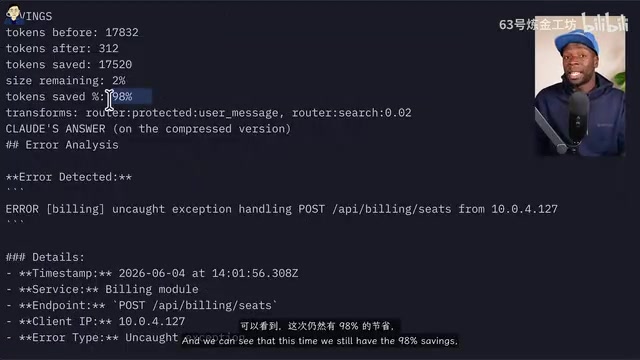
Code Project Analysis Scenario: Code-Aware Compression
In another test, Claude was asked to read all TypeScript files in a project and provide an in-depth overview. With Headroom's code-aware compressor enabled, approximately 89.1k tokens were used, while the control group without Headroom consumed significantly more. Through Headroom's statistics endpoint, you can clearly see how many tokens and how much money each compression saved.
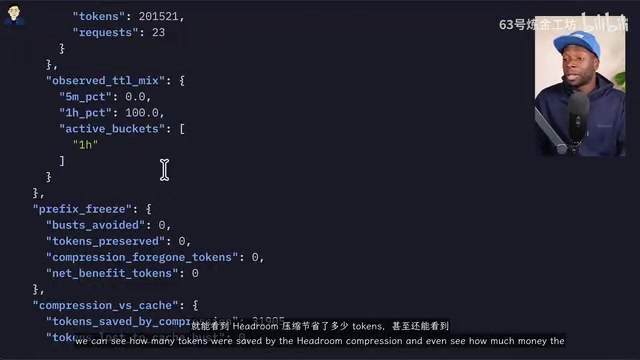
An interesting finding: in low-effort mode, Headroom produced almost no token savings; only at medium and higher effort levels did the savings become significant. This indicates that Headroom delivers the most value in high token consumption scenarios.
Advanced Features: More Than Just a Compression Tool
Headroom also offers several noteworthy advanced capabilities:
Cross-Agent Memory
This allows different AI coding tools like Claude Code and Codex to share the same compressed context. Content that's already been compressed in one tool doesn't need to be reprocessed in another.
In modern AI development workflows, developers may use multiple AI tools simultaneously: Claude Code for writing code, Codex for code review, and Cursor for debugging. Each tool has its own independent context window, meaning the same code file might be read and processed multiple times. Cross-Agent Memory solves this through a shared compression cache layer — when one tool has already compressed and cached a file's content, other tools can directly reuse that compressed result, avoiding redundant token consumption. This essentially establishes a shared knowledge layer across multiple AI agents, similar to how multiple processes in an operating system share the same memory-mapped file.
Headroom Learn (Adaptive Learning Optimization)
This is the key feature for solving the "over-compression" problem. It mines your failed session logs, identifies cases where content was compressed too aggressively for the model to answer correctly, and then learns to avoid making the same mistakes in the future. It's a continuous optimization feedback loop.
From a technical perspective, Headroom Learn implements an offline reinforcement learning approach: it treats each session's compression decisions as "actions" and whether the model ultimately completed the task successfully as the "reward signal." When a compression causes the model to require a second round-trip to fetch original data, or leads to an incorrect answer, the system records this negative feedback and adjusts the compression threshold for the corresponding content type. Over time, Headroom becomes increasingly aware of which information constitutes non-compressible "critical signals" in your specific work scenarios.
Limitations and Trade-offs
Extra Cost from Round-Trips
Headroom's biggest potential issue is this: when the model finds the compressed information insufficient and needs to request full data via the hash value, it incurs an additional round-trip. In some cases, this can actually consume more tokens than not using Headroom at all. The Headroom Learn feature is specifically designed to mitigate this problem.
Specifically, one extra round-trip means: the model needs to generate an output requesting the full data (consuming output tokens), the system returns the complete original data (consuming input tokens), and then the model needs to reprocess the context containing the full data (consuming input tokens again). In the worst case, total token consumption could reach 1.5-2x what it would be without Headroom. Therefore, Headroom's net benefit is highly dependent on the accuracy of its compression decisions — which is exactly why Headroom Learn's adaptive optimization is so important.
Complementary Use of Headroom and Caveman
It's worth noting that Headroom and another tool called Caveman take completely opposite approaches:
- Headroom: Compresses the model's input (tool call results, code files, etc.)
- Caveman: Compresses the model's output (instructs the model to reply with brief snippets, removing filler words)
One reduces input, the other reduces output — in theory, they can be used simultaneously for maximum token savings.
Understanding this complementary relationship from a token billing perspective: input and output token prices typically differ by 3-5x (output is more expensive), so Caveman's compression of output tokens actually has higher per-unit economic value. Headroom's advantage in compressing input tokens lies in the fact that input volume is typically far larger than output — a single tool call might return tens of thousands of tokens of content, while the model's response is usually only hundreds to thousands of tokens. Combining both tools reduces costs from both the input and output sides simultaneously.
Conclusion: A Worthwhile AI Cost Optimization Solution
Headroom represents a pragmatic approach to AI cost optimization: rather than waiting for model prices to drop or context windows to expand infinitely, it tackles information redundancy at the engineering level. According to official data, Headroom has saved users approximately $700,000 in token costs to date.
For developers and teams who are heavy users of AI coding tools, Headroom deserves serious consideration. Its value becomes even more pronounced in workflows involving multi-agent parallelism and high effort levels. Of course, any compression carries the risk of information loss — the key is finding the optimal balance between compression rate and accuracy, which is precisely the problem Headroom Learn aims to solve automatically.
From a broader perspective, the "Context Engineering" that Headroom represents is becoming an important discipline in AI application development. As AI agents grow increasingly complex, efficiently managing limited context window resources — deciding what information enters the window, at what granularity, and when to retrieve more details — will become a critical engineering decision affecting AI application performance and cost. Headroom provides an elegant automated solution that frees developers from having to make these trade-offs manually.
Related articles

Codex VS Claude Code: The Token Economics Behind a 10x Price Gap
Same coding task: Codex costs $15, Claude Code costs $155. Deep dive into the real reasons behind the 10x gap — it's not pricing, it's token volume, output style, and context strategy.
Gemma 4 Open-Source Model Local Deployment Guide: Ollama Installation & Mobile Setup
Step-by-step guide to deploying Google's Gemma 4 open-source model locally with Ollama and running the lightweight version on mobile with tool calling support.
The Decline of Tokenmaxxing: Why Selling Outcomes Matters More Than Selling Tokens
The Tokenmaxxing craze is fading as enterprise AI procurement shifts from chasing Token counts to focusing on actual business outcomes. Learn why outcome-based AI evaluation is the right approach.