How Powerful Is Gemini Omni's Native Multimodal Video Editing? A Hands-On Demo Breakdown
Gemini Omni's native multimodal architecture enables direct video editing, not just generation.
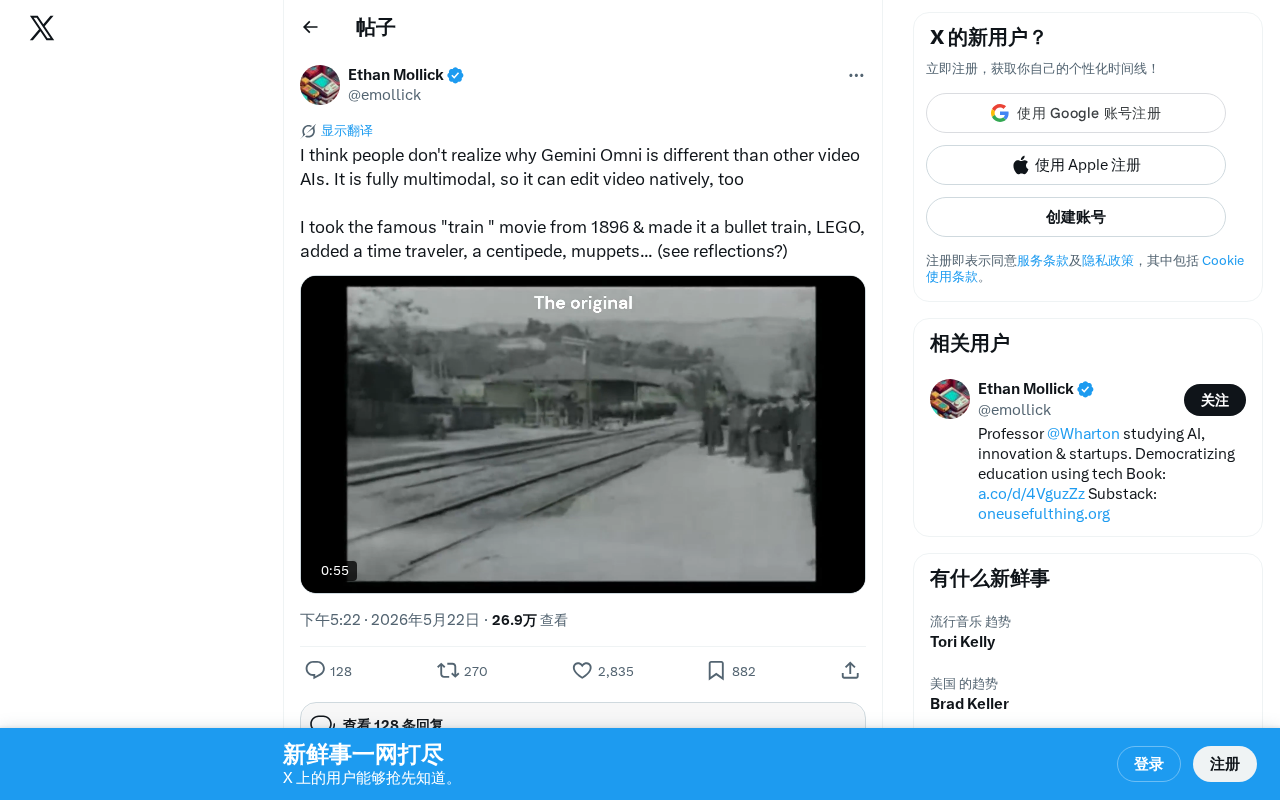
Gemini Omni distinguishes itself from traditional video AIs by natively editing existing videos rather than generating new ones from scratch. Demonstrated on the iconic 1896 Lumière brothers' train film, it showcases capabilities including style conversion to LEGO, element replacement, and character addition — all while preserving original composition and handling complex visual details like reflections.
What Makes Gemini Omni Unique: Native Multimodal Video Editing
Recently, a user shared Gemini Omni's video editing capabilities on Twitter, sparking widespread attention. The user pointed out that many people haven't realized the fundamental difference between Gemini Omni and other video AIs — it is fully multimodal and can natively edit video, rather than simply generating new content.
"Natively Multimodal" means the model was designed from the ground up to process multiple information modalities — text, images, audio, and video — within a single unified model, rather than chaining multiple single-modality models together through a pipeline. This means the model internally shares the same representational space across different modalities, enabling deep cross-modal understanding and generation, rather than mere format conversion or modality stitching.
Hands-On Demo: Transforming the Classic 1896 Train Film
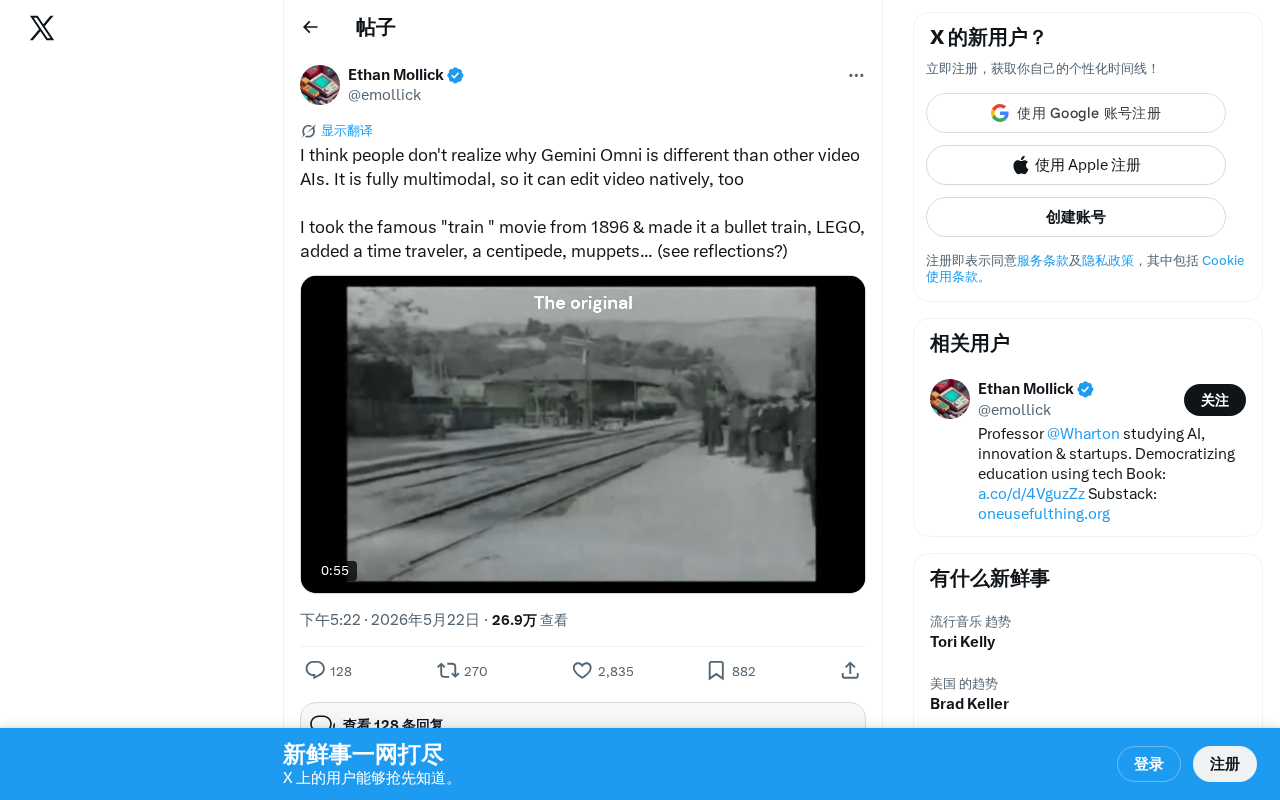
The user demonstrated Gemini Omni's various editing capabilities using the famous 1896 "train arriving at a station" film as source material. L'Arrivée d'un train en gare de La Ciotat is an approximately 50-second short film shot by the Lumière brothers, considered one of the most iconic early works in cinema history. Legend has it that audiences fled their seats in terror when they saw the train approaching the camera. Choosing this film as demo material carries deep symbolic significance — it represents the origin point of visual media technology, while using AI to creatively edit it showcases the cutting edge of that same technology 127 years later.
Specific demonstrations included:
- Turning the regular train into a bullet train: Replacing the core element while maintaining the original frame composition
- Converting the footage to LEGO style: Achieving a complete visual style transformation
- Adding a time traveler character: Naturally integrating a new character into the existing scene
- Inserting a centipede element: Demonstrating responsiveness to unconventional creative requests
- Adding a Muppet character: Even showing reflection effects, demonstrating the ability to handle complex visual details
All these operations were performed directly on the original video, rather than regenerating an entirely new video from scratch.
What Does Native Multimodality Mean? The Core Difference from Traditional Video AI
The key distinction lies in the word "native." Traditional video AIs (such as Sora, Runway, Pika, etc.) typically generate entirely new videos based on text prompts, working in a manner similar to "creating from nothing" — the model gradually generates frames from noise based on text descriptions. Gemini Omni, on the other hand, can understand and directly edit existing video content, more akin to "making modifications on existing material." Specifically:
- Understanding capability: It can "comprehend" every frame of a video, recognizing scene structure, object relationships, and motion trajectories
- Editing capability: Making creative modifications while preserving the original structure and temporal sequence, including style transfers, element additions, and character replacements
- Detail handling: Processing complex visual details like reflections and lighting to make edits appear more natural
From a technical perspective, this requires the model to possess not only generative capabilities but also frame-by-frame spatial understanding of input video — including implicit completion of traditional computer vision tasks such as depth estimation, object segmentation, and motion tracking. Previously, these tasks required separate specialized algorithms, but the native multimodal architecture unifies them within a single end-to-end model.
This capability dramatically lowers the barrier to video editing. Users need only describe their desired modifications in natural language to achieve effects that previously required professional video editing software (such as After Effects or DaVinci Resolve) and years of skill development. For content creators and everyday users alike, this means the way we express video creativity is being fundamentally redefined.
Key Takeaways
Related articles

Claude Code for Test Development in Practice: An AI Programming Workflow That Doubles Your Efficiency
A practical guide to Claude Code for test development: auto-generating test scripts, Plan Mode workflows, MCP + Playwright integration, and Subagent parallel tasks to build systematic AI-assisted workflows.

Hermes Agent Hands-On Review: An AI Efficiency Revolution for Indie Game Developers
Indie game developer reviews Hermes Agent vs OpenClaude: intelligent context compression, real-time Memory, remote control via Telegram, and practical use cases in game dev, social media, and email.

Vibe Coding Beginner's Guide: Tool Selection Across Three Categories with Practical Examples
A comprehensive guide to Vibe Coding's three tool categories: Agent frameworks, CLI Coding, and IDE tools, with practical examples including Snake game and data analysis workbench.