Is Context Engineering the Core of Agent Development? A Deep Dive into Architecture and Practical Solutions

Context engineering is the core of Agent development: dynamically building optimal decision environments for stateless LLMs.
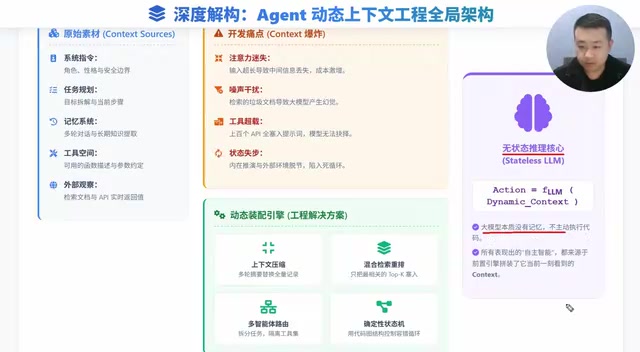
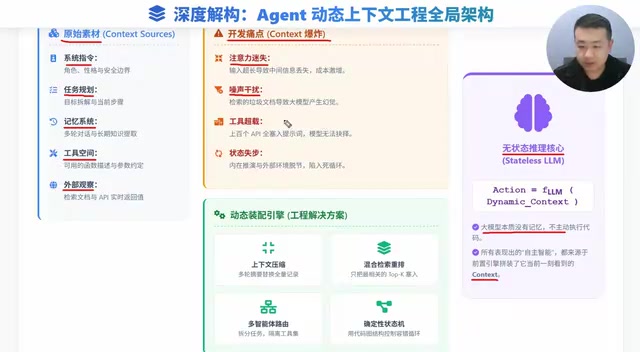
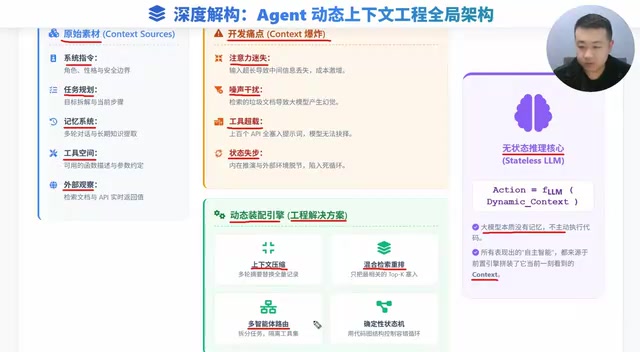
This article systematically explains why context engineering is the core of Agent development. LLMs are fundamentally stateless functions, and Agent intelligence depends entirely on precise context assembly. A mature Agent's context comprises five modules—system instructions, task planning, memory system, tool space, and external observations—facing four pain points: Lost in the Middle, noise-induced hallucinations, tool overload, and state desynchronization, addressed through compression, hybrid retrieval with reranking, multi-Agent architecture, and deterministic state machines.
Introduction: The Hidden Depth Behind an Advanced Interview Question
"Some say the core of Agent development is context engineering—do you agree?" This interview question seems simple but is deceptively complex. If you simply answer "agree" or "disagree," you've already lost half the battle. Because while the question appears to test your understanding of prompts, it's actually evaluating your deep expertise in Agent architecture design.
This article, based on an in-depth explanation by Bilibili creator Peng Yu, systematically breaks down the core logic of context engineering in Agent development, helping you understand from an architectural perspective why context management is the lifeblood of Agents.
Why I Strongly Agree: The Nature of LLMs Determines Everything
To understand this viewpoint, you first need to see through the essence of large language models—an LLM is fundamentally a stateless function. It has no memory, doesn't think proactively, and won't call tools on its own.
This concept stems from the fundamental design principles of the Transformer architecture. Every time you call an LLM API, the model doesn't "remember" the previous conversation—it simply receives the entire token sequence of the current input, computes attention weights between tokens through the Self-Attention mechanism, and outputs the most probable next token. This stands in stark contrast to traditional stateful services (like database connections). Because of this, so-called "multi-turn conversations" are essentially the developer re-concatenating and sending the complete history of messages to the model each time—the model itself maintains no session state.
All the "intelligence" you see an Agent display—planning, reflecting, researching—is fundamentally because we precisely assemble the environment state, historical memory, and task objectives into a context at each moment, then feed it to the model.
So Agent development is really about upgrading from the elementary level of "writing prompts" to dynamic state management engineering. This is a qualitative leap—from manually concatenating strings to building a complete information flow system.
The Five Core Modules of Agent Context
A mature Agent's context is far more than a single sentence—it's dynamically assembled from five core building blocks:
1. System Instructions (Identity Card)
Defines the Agent's role, personality, and safety boundaries. This is the most fundamental layer, determining "who the Agent is" and "what it cannot do." System instructions are typically placed at the front of the context as a System Message, leveraging the model's high attention weight on sequence-initial information to ensure role settings remain effective throughout the conversation.
2. Task Planning (Scratch Pad)
Like a scratch pad at work, it records which step the current task decomposition has reached. This gives the Agent multi-step reasoning and task decomposition capabilities. Typical implementations include Chain-of-Thought prompting and the Plan-and-Execute pattern, where the latter first has the model generate a complete execution plan, then executes step by step while dynamically adjusting based on feedback.
3. Memory System (Short-term + Long-term)
Divided into short-term chat history and long-term historical data, with the latter dynamically retrieved from vector databases. The memory system gives the Agent "experience." Short-term memory is usually stored directly in the context window, while long-term memory relies on vector databases (such as Pinecone, Milvus, Chroma, etc.) for persistent storage, recalling relevant fragments through semantic retrieval when needed. This layered memory architecture simulates the collaboration between human working memory and long-term memory.
4. Tool Space (Toolbox)
Tells the Agent what "wrenches and screwdrivers" are currently available—the description information of callable APIs. Tool descriptions are typically presented as JSON Schema or function signatures, including tool name, functionality description, parameter types, and return value formats. OpenAI's Function Calling and Anthropic's Tool Use are both standard implementations of this paradigm.
5. External Observations (Real-time Feedback)
For example, freshly searched news, API return results, or error messages. This is the Agent's window for interacting with the external world. In the ReAct (Reasoning + Acting) framework, external observations are explicitly labeled as Observation, alternating with the model's Thought and Action to form a complete reasoning-action-observation loop.

All five components are constantly changing. How to efficiently fit them into a limited context window is the first step of context engineering.
Four Core Pain Points: Why You Can't Just "Stuff Everything In"
Some might ask: Don't modern LLMs have context windows of hundreds of thousands or even millions of tokens? Why not just stuff everything in?
Don't think that way. This is precisely where practical experience shows—in real development, we face four core pain points:
Pain Point 1: Lost in the Middle
This is a phenomenon verified by academia—when context is too long, the model experiences "intermittent amnesia" for information in the middle positions. Moreover, longer context means slower inference and higher costs.
The Lost in the Middle phenomenon was first systematically verified by Nelson F. Liu et al. from Stanford University in their 2023 paper. Research found that when key information is placed in the middle of long text, the model's retrieval and reasoning accuracy drops significantly, while information at the beginning or end is better utilized. This relates to the Transformer's positional encoding mechanism and the U-shaped curve of attention distribution—the model naturally assigns higher attention weights to the beginning and end of sequences. This finding directly influences document arrangement strategies in RAG systems and priority design in context assembly.
Pain Point 2: Noise-Induced Hallucinations
If retrieved documents contain typos or junk information, the model gets led astray and starts "confidently spouting nonsense." This problem is particularly acute in RAG systems.
RAG (Retrieval-Augmented Generation) is currently the most mainstream knowledge enhancement paradigm in Agent development, first proposed by Meta AI in 2020. Its core approach is to retrieve relevant document fragments from external knowledge bases before the model generates an answer, then inject them into the context for reference. However, RAG is not a silver bullet—if retrieval quality is poor and returns documents irrelevant to the question or containing incorrect information, the model may actually be misled by this "noise," producing hallucinated outputs that are more deceptive than without retrieval. This is why retrieval precision and document quality control are critical in RAG engineering.
Pain Point 3: Tool Overload
If you give an Agent 100 tool descriptions at once, it gets "dizzy" and may even hallucinate non-existent parameters. Tool descriptions themselves consume massive tokens and interfere with the model's decision-making.
Experiments show that when available tools exceed 15-20, the model's tool selection accuracy begins to noticeably decline. Each tool's JSON Schema description typically consumes 200-500 tokens—100 tools' descriptions alone could consume 20,000-50,000 tokens, not only squeezing out space for other critical information but also making it difficult for the model to make precise selections among many similar tools.
Pain Point 4: State Desynchronization
The Agent thinks it executed successfully, but the external environment has actually thrown an error. When the context isn't updated in time, the Agent falls into an infinite loop. This is especially common in asynchronous operations and network requests—for example, if an Agent calls an API but it times out without returning, and the context doesn't correctly record this exception, the Agent may continue reasoning based on false premises, causing all subsequent decisions to be built on an incorrect foundation.
Dynamic Assembly Engine: Four Solutions
This is the real substance interviewers want to hear—facing the above pain points, how do we build a dynamic assembly engine?
Solution 1: Context Compression and Summarization
Don't let the Agent be a "parrot." When conversations get too long, have the model generate summaries and replace full history with condensed information. This saves tokens while preserving key information.
In terms of implementation, common strategies include: sliding window (keeping only the most recent N turns), recursive summarization (generating summaries at regular intervals to replace original text), and selective retention based on importance scoring. OpenAI's ChatGPT uses a similar summary compression mechanism when handling ultra-long conversations. A more advanced approach uses specialized smaller models (such as models fine-tuned for summarization tasks) to perform compression, avoiding consumption of the main model's inference resources.
Solution 2: Hybrid Retrieval and Reranking
You can't rely solely on semantic search (Embedding similarity)—you need an additional Reranker layer. This ensures the information injected into the context is "absolutely clean and absolutely relevant." This is the key guarantee of RAG system quality.
A Reranker is the second stage in the classic two-stage architecture of information retrieval. The first stage typically uses Embedding vector similarity for rough filtering (recall)—fast but limited in precision; the second stage uses a Cross-Encoder to perform fine-grained matching and scoring for each candidate document against the query. Unlike Bi-Encoder models, Cross-Encoders can capture fine-grained interaction features between query and document, resulting in significantly higher ranking quality. Common open-source Rerankers include Cohere Rerank, bge-reranker, and various BERT-fine-tuned models. In practice, typically Top-50 to Top-100 candidate documents are recalled first, then after Reranker precision ranking, Top-5 to Top-10 are injected into the context.
Solution 3: Dynamic Tool Recall and Multi-Agent Architecture
For the problem of oversized tool sets, there are two strategies:
- Dynamic Tool Recall: First use a lightweight model to select the 5 most relevant tools, then place only those 5 into the main model's context
- Multi-Agent Architecture: Distribute tasks to different sub-Agents, achieving physical isolation at the tool level
Multi-Agent architecture borrows from microservice design philosophy—decomposing a complex large task into multiple specialized sub-Agents, each responsible only for tools and knowledge in a specific domain. Typical implementations include frameworks like AutoGen and CrewAI. The advantage of this architecture is that each sub-Agent's context window only needs to load tool descriptions and knowledge relevant to its responsibilities, avoiding the decision confusion a single Agent faces with massive tools; meanwhile, sub-Agents collaborate through message passing, naturally achieving separation of concerns. However, Multi-Agent architecture also brings new challenges, such as inter-Agent communication overhead, task allocation coordination strategies, and global state consistency maintenance.
Solution 4: Deterministic State Machine Control Flow
Don't rely entirely on the model to "self-reason" within prompts. We should use graph-based frameworks (like LangGraph) to solidify logic, using code to enforce error handling and loop control. Hand deterministic logic to code, and non-deterministic reasoning to the model—this is mature architecture design.
LangGraph is an Agent orchestration framework from the LangChain team, whose core concept is modeling the Agent's execution flow as a directed graph (DAG or cyclic graph). Each node in the graph represents a processing step (such as calling an LLM, executing a tool, conditional branching), while edges define state transition rules. Unlike the purely LLM-autonomous ReAct pattern, LangGraph allows developers to explicitly define in code which transitions are deterministic (such as error retry logic, format validation, maximum loop count limits) and which nodes require LLM's non-deterministic reasoning. This "human-machine collaborative" control pattern dramatically improves Agent reliability and debuggability, and is the mainstream architecture choice for industrial-grade Agent development. Similar frameworks include Microsoft's Semantic Kernel, as well as DAG-based workflow engines like Prefect and Temporal.
The Golden Path for Interview Answers
If an interviewer asks "Is context engineering the core of Agent development?", the recommended answer path is:
- Clearly agree: Compare context to the Agent's "bloodstream" and "short-term brain"
- Demonstrate structured thinking: Break down the five modules of context (system instructions, task planning, memory system, tool space, external observations)
- Address pain points directly: Discuss attention loss, hallucinations, and cost control
- Present advanced solutions: Summary compression, hybrid retrieval with reranking, multi-Agent isolation, graph and state machine control flow
The elegance of this answer path is that it demonstrates a complete chain of thought from "what" to "why" to "how." The interviewer can judge that you not only understand concepts but also possess the ability to translate theory into engineering practice.
Conclusion
Agent development is absolutely not a word game—it's building a complex information flow system. The essence of context engineering is dynamically constructing the optimal decision-making environment for a "stateless function" within a limited window.
Once you understand this, you can break free from the beginner mindset of "writing Prompts" and enter the realm of true Agent architecture design. Whether in interviews or actual development, this thinking framework that starts from fundamentals and builds progressively will help you establish a systematic cognitive advantage.
Key Takeaways
- LLMs are fundamentally stateless functions; all intelligent behavior of Agents depends on precise context assembly
- A mature Agent's context consists of five modules: system instructions, task planning, memory system, tool space, and external observations
- Long contexts face four major pain points: Lost in the Middle, noise interference, tool overload, and state desynchronization
- Solutions include context compression, hybrid retrieval with reranking, dynamic tool recall/multi-Agent architecture, and deterministic state machines
- The essence of Agent development is building complex information flow systems, not simple Prompt writing
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.