Jan Leike Launches New Research Project at Anthropic: Alignment Is Only Part of AGI Safety
Jan Leike launches a new Anthropic project, arguing AGI safety extends well beyond alignment.
Former OpenAI Superalignment co-lead Jan Leike has announced a new research project at Anthropic, emphasizing that alignment is only one piece of the AGI safety puzzle. After leaving OpenAI over disagreements about safety prioritization, Leike's move to Anthropic and his broadened focus signal a shift in the field toward treating AGI safety as a multi-dimensional systems challenge encompassing governance, social impact, and international coordination alongside technical alignment.
Jan Leike Announces a Brand-New Research Project at Anthropic
Jan Leike, former co-lead of OpenAI's Superalignment team, recently announced on Twitter that he is launching a brand-new research project at Anthropic, expressing great excitement about the endeavor.
"Alignment Is Just One Piece" — From Alignment to a Broader AGI Safety Vision
In his tweet, Jan Leike left a thought-provoking remark:
"Getting AGI right requires many things, and alignment is just one of them."
This statement deserves deeper analysis. As a top researcher who previously focused on AI alignment, Leike is now expanding his vision beyond alignment alone. AI alignment refers to the technical research direction of ensuring that an AI system's goals, behaviors, and decisions remain consistent with human values and intentions. Current mainstream alignment techniques include Reinforcement Learning from Human Feedback (RLHF), Anthropic's Constitutional AI (which has AI critique and revise itself based on predefined principles), and Scalable Oversight, among other methods. The core difficulty of alignment lies in the fact that human values are inherently vague, diverse, and even contradictory — and as AI capabilities grow, verifying alignment effectiveness becomes increasingly challenging.
Leike hinted that more details would be shared soon, suggesting the new project may address broader dimensions of AGI safety and governance — potentially including AI system controllability, social impact assessment, human-AI collaboration frameworks, or even AGI deployment strategies.
Background: Jan Leike's Journey from OpenAI to Anthropic
Jan Leike was previously the co-lead of OpenAI's Superalignment team, working alongside Ilya Sutskever. Superalignment was a research initiative proposed by OpenAI in July 2023, with the core objective of solving a fundamental challenge: when AI systems surpass human-level intelligence, how can humans ensure they can still effectively supervise and control these systems? Traditional alignment methods rely on human feedback, but when AI capabilities far exceed the scope of human understanding, humans may be unable to judge whether an AI's outputs truly meet expectations. OpenAI initially pledged to dedicate 20% of its compute resources to the team, with a four-year plan to tackle this problem, but actual resource allocation fell far short of that commitment.
In 2024, Leike departed OpenAI due to disagreements over the company's resource allocation and prioritization of safety research, subsequently joining Anthropic. His departure sparked widespread industry discussion about OpenAI's safety culture. Notably, this was not an isolated event — 2024 was a year of dramatic shifts in the AI safety talent landscape. Several core members of the Superalignment team left in succession, including co-lead Ilya Sutskever (who went on to found Safe Superintelligence Inc., a company focused on safety). The root cause of this exodus was the deep tension within AI labs between the "accelerate development" and "safety first" philosophies — under commercial pressure, safety research is often viewed as an obstacle to product iteration.
Anthropic itself is a company with AI safety at its core mission, co-founded in 2021 by former OpenAI VP of Research Dario Amodei and Daniela Amodei. Anthropic's central philosophy is to place AI safety research at the heart of commercial development, rather than treating it as an ancillary function. The company has produced several original safety research contributions, including the Constitutional AI methodology, model interpretability research (such as "dictionary learning" analysis of internal neural network features), and the Responsible Scaling Policy (RSP). The RSP defines AI Safety Levels (ASL), setting corresponding safety requirements for AI systems at different capability levels. As of 2024, Anthropic has raised over $7 billion in funding, and its flagship Claude model series has earned industry recognition for balancing safety and usefulness. Leike's decision to launch his new project at Anthropic indicates that the company provides an environment and resources more aligned with his research philosophy.
What This New Project Means for the AI Safety Field
AGI Safety Is a Systems Engineering Challenge, Not Just Alignment
Leike's statement reflects an important trend in AI safety research: ensuring the safe development of AGI is a multi-dimensional systems engineering challenge. Technical alignment — making AI systems behave in accordance with human intentions — is certainly critical, but it is far from the whole picture.
From a systems engineering perspective, AGI safety encompasses multiple interconnected layers: the technical layer includes alignment, interpretability, robustness, and formal verification; the governance layer includes AI system audit mechanisms, red-teaming standards, and capability evaluation frameworks (such as the ASL levels defined in Anthropic's RSP); the social layer involves assessing AI's impact on labor markets, risks of power concentration, and fairness in AI decision-making; and the international layer requires cross-border coordination mechanisms, such as the AI Safety Institute network established following the 2023 UK AI Safety Summit. A growing number of researchers recognize that even if technical alignment were perfectly solved, the deployment of AGI could still pose serious risks without adequate institutional and societal preparation. Institutional design, evaluation systems, deployment strategies, and international coordination are equally indispensable non-technical factors.
What the Flow of Top AI Safety Talent Signals
From a broader perspective, the fact that Leike has the opportunity to launch a new research project at Anthropic also reflects the current competitive landscape for talent in AI safety. The choices made by top researchers often reveal which organizations are truly investing sufficient resources and granting enough freedom for safety research. By comparison, Anthropic, DeepMind's safety teams, and emerging independent safety research organizations (such as ARC Evals and METR) are attracting an increasing number of top-tier talent, forming a research ecosystem with safety as its core mission. The directionality of this talent flow is itself an important signal: at a time when AI capabilities are advancing rapidly, organizations that genuinely treat safety research as a core priority are winning the trust and participation of the best researchers.
Looking Ahead: AGI Safety Research May Be Heading in a New Direction
Leike has indicated that more information will be shared soon. Given his deep expertise in alignment research and his explicit assertion that "alignment is just one piece," this new project is likely to open up new directions for AGI safety research. Regardless of the specific details, this will be an important development worth close attention in the AI safety field.
Key Takeaways
Related articles
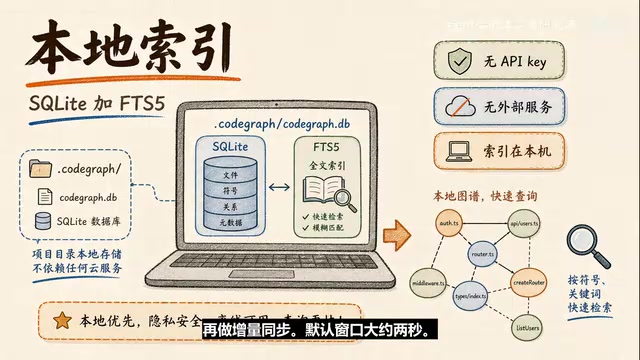
CodeGraph: Give Your Coding Agent a Code Map, Save 47% Tokens
CodeGraph is an open-source project with ~40K GitHub stars that uses Tree-sitter to build a local queryable code map, helping Claude Code and Cursor reduce 47% token usage and 58% tool calls.
AI Finishes Writing Code, Automatically Strikes a Gong to Alert You: Open-Source Physical Feedback Tool DAgent
A developer built a physical feedback device with chopsticks and a small gong that auto-strikes when AI finishes coding. Now open-sourced as DAgent, it also simulates IPO bell-ringing when creating new files.

Level Up Claude Code: Building an Enhanced Plan Mode with Grill Me
Learn how to install and use the Grill Me Skill for Claude Code, replacing AI guesswork with structured questioning to clarify requirements before generating execution plans.