Jeremy Howard Takes Aim at Anthropic: The Power Monopoly Paradox Behind AI Safety Narratives
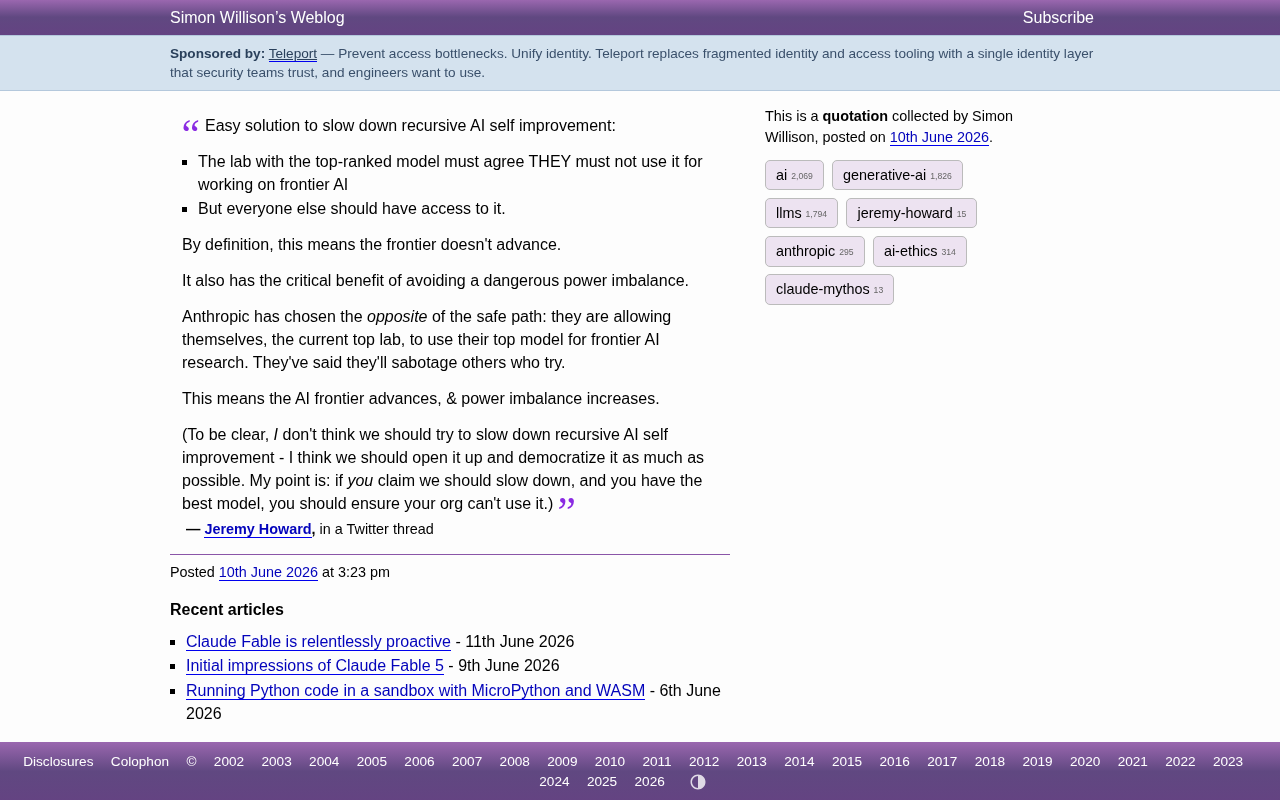
Jeremy Howard exposes the logical paradox in Anthropic's AI safety claims vs. its monopolistic practices.
fast.ai founder Jeremy Howard publicly challenges Anthropic's AI safety strategy, arguing that the lab uses its top-ranked models for frontier AI research while restricting others from doing the same. He proposes a logical consistency test: if recursive self-improvement is truly dangerous, the leading lab should ban itself from using its own models for frontier research while granting everyone else access. Howard advocates for AI democratization and openness, exposing the tension between safety narratives and commercial monopolization in the AI industry.
A Thought Experiment on AI Recursive Self-Improvement
Renowned AI researcher and fast.ai founder Jeremy Howard recently posted a widely discussed take on Twitter, targeting Anthropic — currently considered one of the top AI labs with leading large language models. He put forward a seemingly simple yet deeply penetrating logical argument: if you claim to want to slow down AI's recursive self-improvement, then you shouldn't be using the most powerful models to conduct frontier AI research yourself.
Jeremy Howard is one of the most influential practitioners and educators in the AI field. His organization fast.ai not only developed a widely popular open-source deep learning library but also taught hundreds of thousands of people deep learning through free online courses. Howard has long championed the democratization and decentralization of AI technology, opposing the concentration of advanced AI capabilities in the hands of a few large labs. He previously served as president of Kaggle and co-invented ULMFiT (a pioneering NLP transfer learning method) that laid important groundwork for the rise of pretrained models like BERT and GPT. His views carry considerable authority and influence within the AI community.
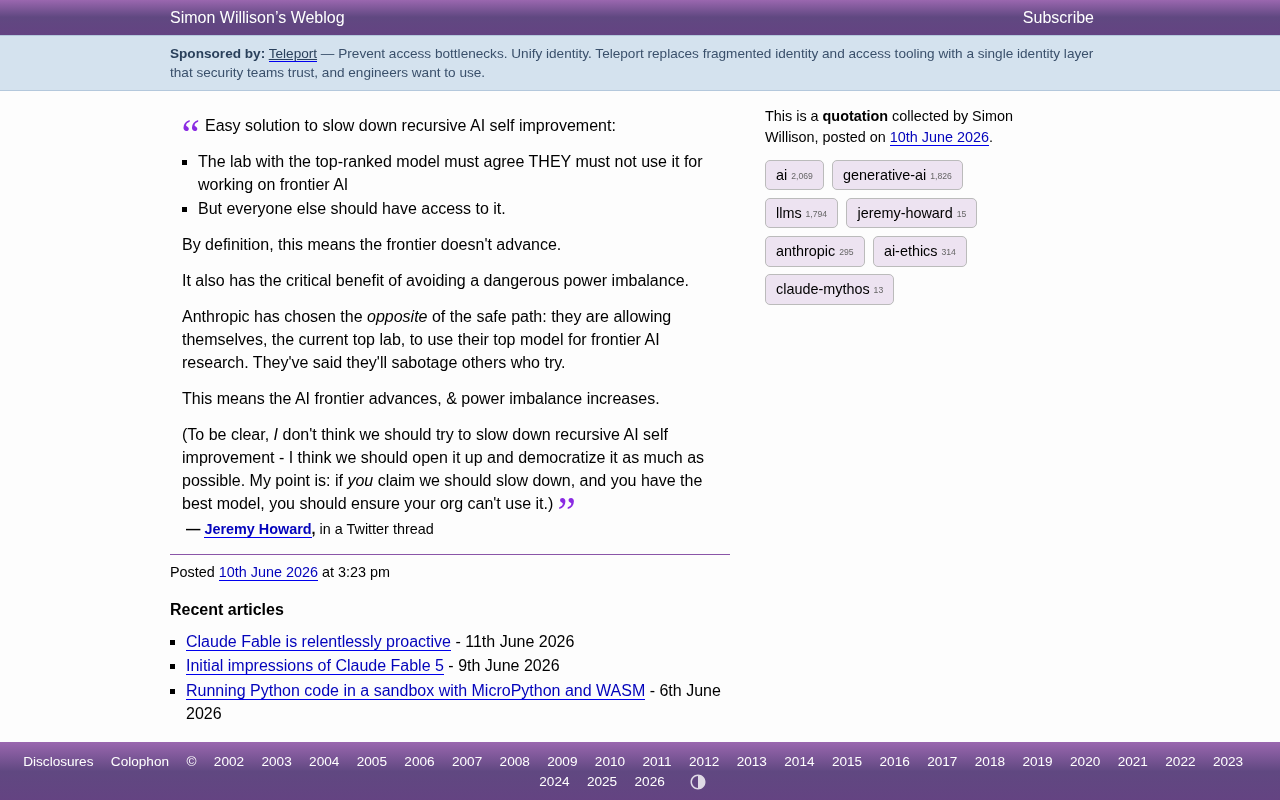
Howard's argument can be distilled into an elegant policy proposal:
- The lab that owns the top-ranked model must commit to not using that model for frontier AI research
- But everyone else should have the right to access that model
A key concept to understand here: AI Recursive Self-Improvement is a core and controversial concept in artificial intelligence, traceable to mathematician I.J. Good's 1965 "intelligence explosion" hypothesis. The central idea is that a sufficiently advanced AI system could understand and improve its own design, and the improved system would then have even greater self-improvement capabilities, creating a positive feedback loop. In the current era of large models, this concept has moved from theory to practice — AI labs are using existing models to assist with training data curation, code writing, architecture search, and even alignment research itself, meaning each generation of models is accelerating the creation of the next.
By definition, Howard's proposal would mean the AI frontier stops advancing — because the most powerful tools would be prohibited from being used for the most cutting-edge exploration. At the same time, it would prevent dangerous power imbalances, since the strongest models would be widely shared rather than monopolized by a single institution.
Anthropic's "Reverse Play"
Howard pointedly notes that Anthropic has chosen the exact opposite direction from this "safe path." As the currently recognized top lab, Anthropic not only allows itself to use the most powerful models for frontier AI research but has also indicated it would "sabotage" others who try to do the same.
Anthropic was founded in 2021 by former OpenAI VP Dario Amodei and his sister Daniela Amodei, with a core narrative of being an "AI safety company." The company introduced its Responsible Scaling Policy (RSP), which sets different safety thresholds and deployment standards based on the danger level of model capabilities. Anthropic also pioneered alignment techniques like Constitutional AI, which attempts to have models internalize safety guidelines during training. However, Anthropic is also a commercial company that has raised over $10 billion in funding with a valuation in the tens of billions, and its flagship Claude model series ranks at the top of multiple benchmarks. This dual identity of "safety mission" and "commercial competition" is precisely the target of Howard's criticism.
The "sabotage" here refers to a series of restrictive measures Anthropic employs in its model safety strategy — imposing usage restrictions on external users while internal teams can fully leverage model capabilities to advance research. Specifically, these safety restrictions operate on multiple levels: at the model level, techniques like RLHF (Reinforcement Learning from Human Feedback) and Constitutional AI make models refuse dangerous requests; at the API level, usage policies restrict certain types of output; at the deployment level, high-risk capabilities undergo dedicated red-teaming and capability evaluations. Additionally, Anthropic conducts "capability evaluations" that trigger stricter safety measures when models reach preset thresholds in specific dangerous domains. The "sabotage" Howard refers to is precisely these layers of restrictions imposed on external users — which objectively reduce external researchers' ability to use these models for frontier AI research.
This approach leads to two direct consequences:
- The AI frontier keeps advancing: The strongest models are used to develop even stronger models, accelerating the recursive improvement flywheel
- Power imbalances deepen: The capability gap between institutions controlling the strongest models and everyone else continues to widen
This creates a profound paradox: a company whose core mission is "AI safety" may, through its actual behavior, be creating the least safe scenario.
His True Position: Openness and Democratization
You might not have noticed, but Howard himself does not advocate for slowing down AI recursive self-improvement. He states his position explicitly at the end of his post:
"I personally don't think we should try to slow down AI recursive self-improvement — I think we should open it up and democratize it as much as possible."
His argument is essentially a logical consistency test: if you (referring to labs like Anthropic) claim that recursive self-improvement is dangerous and needs to be slowed down, then your actions should match your words. You should ensure your own organization cannot use the strongest models to advance frontier research, rather than restricting others while giving yourself a free pass.
This criticism strikes at a core tension in the AI industry — the conflict between safety narratives and commercial interests. When "safety" becomes a competitive moat rather than a genuine public commitment, it effectively serves market monopolization rather than human welfare. This phenomenon is not new in the tech industry — from telecommunications to social media, the strategy of "monopolizing in the name of regulation" has been seen time and again. Large enterprises often begin calling for strict regulation only after their own position is secure, because compliance costs burden small competitors far more than themselves.
Deeper Industry Implications
The False Binary of Safety vs. Openness
For a long time, a popular narrative has existed in the AI industry: open models are dangerous, and closed development is the responsible approach. But Howard's logic reveals the other side of this narrative — while closed development may reduce external risks, it potentially creates greater systemic risk by giving a single institution asymmetric technological advantage.
In fact, the thriving open-source AI ecosystem is challenging this narrative. Meta's LLaMA series of open-source models broke the paradigm that large models could only be controlled by a few labs; Stability AI open-sourced Stable Diffusion, bringing image generation technology to the masses. Extensive academic research also shows that open-source models, through broad community review and red-teaming, often have their security vulnerabilities discovered and patched more quickly, while the security of closed models depends entirely on the developing institution's own evaluation capabilities and good faith.
Who Watches the Watchmen?
If the most powerful AI labs are simultaneously the developers of frontier technology, the setters of safety standards, and the judges of their own behavior, where does the credibility of such "self-regulation" come from? Howard's proposal, while seemingly simple, points to a fundamental governance question: In the AI field, where are the checks and balances on power?
Currently, global AI governance relies primarily on three mechanisms: corporate self-regulation (such as Anthropic's RSP, OpenAI's safety committee), government regulation (such as the EU AI Act, U.S. executive orders), and industry consensus (such as the Frontier Model Forum). However, all three mechanisms have obvious flaws: corporate self-regulation faces conflicts of interest, government regulation faces insufficient technical understanding and legislative lag, and industry consensus is easily dominated by leading companies. The more fundamental problem is that AI capability evaluation itself requires top-tier technical expertise, meaning only a few labs have the ability to judge whether their own models are safe — creating a classic "referee and player" dilemma.
Implications for China's AI Ecosystem
This discussion is equally relevant to China's AI industry. As domestic large model competition intensifies, how to find balance between technological progress and safety governance, and how to avoid "monopolizing in the name of safety," are questions worth deep consideration. The thriving open-source ecosystem (such as DeepSeek, Qwen, etc.) is, to some extent, putting into practice the AI democratization path that Howard advocates.
This trend is particularly strong in China: DeepSeek has gained widespread recognition in the international community with its cost-effective open-source models, with its V3 and R1 series demonstrating capabilities comparable to closed-source top-tier models across multiple benchmarks; Alibaba's Qwen (Tongyi Qianwen) series continues to open-source models at multiple scales, covering the full spectrum from lightweight to heavyweight; Zhipu AI's GLM series has also adopted an open strategy. These practices demonstrate that the open-source path not only doesn't weaken competitiveness but actually creates greater value through community collaboration and ecosystem building. When the capabilities of the strongest models are widely shared, the barrier to innovation is lowered, more eyes are available for security review, and the fruits of technological progress can be shared by more people.
Conclusion
The reason Jeremy Howard's remarks resonated so widely is not that he proposed a viable policy solution, but that he used concise logic to expose an industry-level contradiction: those who shout loudest about AI safety are often the ones who benefit most from the lack of it. Regardless of which side of the open vs. closed debate you stand on, logical consistency should be the most basic requirement.
The deeper significance of this discussion may be to remind us: in AI — a field that could reshape human civilization — we cannot rely solely on the good-faith promises of any single institution. True safety comes from transparency, openness, and effective checks and balances — not from locking the most powerful technology in a few people's vaults and telling the world it's for everyone's benefit.
Related articles

Codex VS Claude Code: The Token Economics Behind a 10x Price Gap
Same coding task: Codex costs $15, Claude Code costs $155. Deep dive into the real reasons behind the 10x gap — it's not pricing, it's token volume, output style, and context strategy.
Gemma 4 Open-Source Model Local Deployment Guide: Ollama Installation & Mobile Setup
Step-by-step guide to deploying Google's Gemma 4 open-source model locally with Ollama and running the lightweight version on mobile with tool calling support.
The Decline of Tokenmaxxing: Why Selling Outcomes Matters More Than Selling Tokens
The Tokenmaxxing craze is fading as enterprise AI procurement shifts from chasing Token counts to focusing on actual business outcomes. Learn why outcome-based AI evaluation is the right approach.