LangChain + MCP Agent Development: A Practical Guide to LLM Selection and Common Pitfalls
A practical guide to choosing the right LLM for LangChain + MCP agent development and avoiding common pitfalls.
This article explores LLM selection strategies for LangChain, LangGraph, and MCP agent development. It compares DeepSeek V3/R1 and Qwen3 across Function Calling support, MCP compatibility, and reasoning capabilities, highlighting that DeepSeek R1 lacks default Function Calling support while Qwen3 leads open-source models in agent and MCP integration. Practical recommendations cover model selection, dual-language development, and the latest Streamable HTTP protocol.
Introduction: Why LLM Selection Matters So Much
In the field of AI agent and workflow development, the combination of LangChain, LangGraph, and the MCP protocol has become the mainstream tech stack for enterprise-grade development. LangChain, the most popular framework for building LLM-powered applications, provides standardized abstraction layers for prompt management, model invocation, and tool integration. LangGraph is an extension library within its ecosystem specifically designed for building stateful, multi-step AI agents — based on directed graph concepts, it allows developers to define complex workflows with loops, conditional branches, and human-in-the-loop nodes. MCP (Model Context Protocol) is an open standard proposed by Anthropic that establishes a unified communication interface between LLMs and external tools. Together, these three form a complete agent development stack spanning the "framework layer + orchestration layer + communication layer."
However, the first pitfall many developers encounter in real projects isn't a code logic issue — it's compatibility errors caused by poor LLM selection.
This article, based on the latest tutorial content from Bilibili creator 码士集团 (Code Master Group), systematically covers how to choose the right LLM for agent development, along with the key differences between mainstream models like DeepSeek and Qwen in terms of Function Calling and MCP support.
Why Developers Must Be Familiar with Multiple LLMs
The tutorial raises an important point: As an LLM application developer, you should never focus on just one model. Whether it's DeepSeek, Qwen, Claude, or GPT-4o, you should understand each model's capability boundaries and ideal use cases.
This isn't just a matter of technical literacy — it's a practical necessity. When your manager asks, "Should we use DeepSeek V3 or Claude 3.7 for this project?" you need to provide professional recommendations across multiple dimensions: Function Calling support, reasoning ability, cost, and more. This is what's known as technical selection capability — and it's a key differentiator between junior and senior AI developers.
DeepSeek Series: Function Calling Pitfalls and Solutions
Understanding How Function Calling Works
Before diving into model differences, it's essential to understand Function Calling — the core mechanism behind it all. Function Calling is the cornerstone of LLM interaction with external tools: developers predefine a set of functions with their names, parameter descriptions, and purposes, then pass these definitions to the model. When a user makes a request that requires external tool invocation, the model doesn't generate a natural language response directly. Instead, it outputs a structured JSON object specifying which function to call and what parameters to pass. The application parses this JSON, executes the actual function call, and returns the result to the model for final summarization. Without Function Calling, a model can only "talk" but not "act" — making agents impossible.
R1 Doesn't Support Function Calling by Default
DeepSeek currently has two flagship models:
- DeepSeek-V3 (API name: deepseek-chat)
- DeepSeek-R1 (API name: deepseek-reasoner)
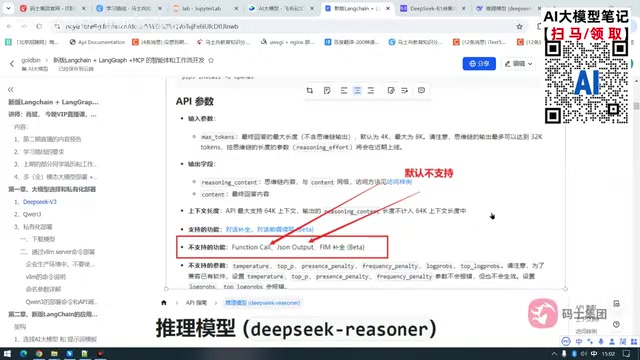
Here's a critical piece of knowledge: DeepSeek R1 does not support Function Calling or JSON Output by default.
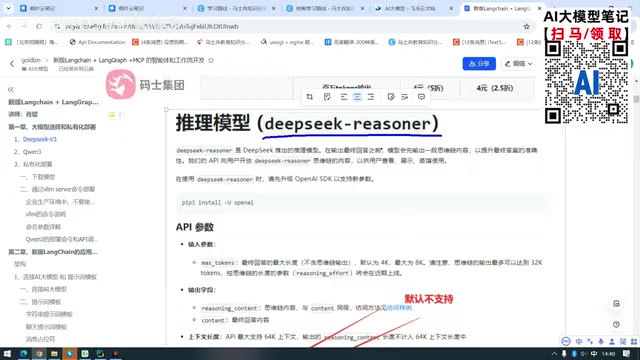
This means if you use the R1 model directly in agent development, you'll likely encounter errors like:
- "Structured output not supported"
- "Function Calling not supported"
This isn't a code bug — it's a limitation of the model itself. The official documentation clearly states this.
Solution: Use V3 or the R1-0528 Version
The tutorial offers two solutions:
Option 1: Use DeepSeek V3 (version 0324 or later recommended)
DeepSeek V3 has fully supported Function Calling since version 0324. Note that V3 versions prior to 0324 had a Function Calling loop bug that caused infinite loops, so make sure to use the latest version.
Option 2: Use the R1-0528 Version
DeepSeek's R1-0528 release officially added support for Function Calling and JSON Output. This is a major win for agent developers — it means you can now leverage R1's powerful reasoning capabilities while also performing tool calls.
Fine-Tuned R1 Can Also Support Function Calling
The tutorial also mentions that some government agencies and hospitals use DeepSeek R1 with Function Calling support — because they've fine-tuned the model. Function Calling is essentially achieved by incorporating large amounts of high-quality tool-calling data into the training set, and any model can gain this capability through fine-tuning. This reveals an important fact: Function Calling is not a hard architectural constraint but rather a result of training data and alignment strategy choices.
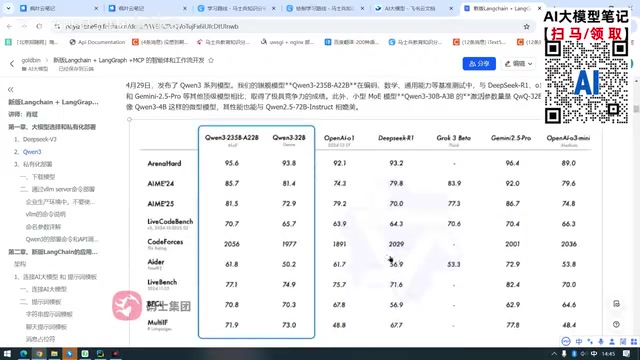
Qwen3: The Strongest MCP Support Among Open-Source Models
Architecture and Version Selection
Qwen3 offers two architectures, allowing developers to choose flexibly based on deployment needs:
| Architecture | Model Sizes | Characteristics |
|---|---|---|
| MoE | 235B (flagship), 30B | Large parameter count, strong capabilities |
| Dense | 8B, 14B, 1.5B | Lightweight, flexible deployment |
It's important to understand the fundamental difference between MoE and Dense architectures. In a Dense architecture, all model parameters are activated during every inference — for example, an 8B Dense model uses all 8 billion parameters to process every token. In contrast, a MoE (Mixture of Experts) architecture splits the model into multiple "expert" sub-networks, activating only a subset during each inference. For example, Qwen3's 235B MoE model has a total of 235 billion parameters, but each inference may only activate around 22 billion of them. This gives it the knowledge capacity of a large model while keeping inference costs close to a much smaller Dense model. This design strikes an elegant balance between performance and efficiency, which is why MoE has become the dominant trend in large model design in recent years.
Two Core Advantages
Advantage 1: Programmable Thinking Mode Switching
Qwen3 supports seamless switching between "deep thinking mode" and "non-thinking mode" via API parameters. This is extremely practical in real development:
- Complex logical reasoning → Enable deep thinking
- Simple Function Calling or MCP calls → Disable deep thinking for faster response
By comparison, DeepSeek's deep thinking mode toggle requires frontend button interaction rather than programmatic control, making it less flexible in automated workflows.
Advantage 2: Best Agent Support Among Open-Source Models
After half a month of hands-on use, the tutorial author gave a definitive assessment: Among open-source models, Qwen3 has the best support for MCP, Function Calling, and agents — bar none.
Additionally, the DeepSeek-R1-0528-Qwen3-8B distilled model combines the strengths of both, supporting deep thinking while being specifically optimized for MCP. This is worth keeping an eye on. The knowledge distillation technique involved here is an important model compression method: a large "teacher model" (DeepSeek R1) guides the training of a smaller "student model" (Qwen3-8B). The student model learns not only from standard training data but also from the teacher model's output probability distributions (i.e., "soft labels"), thereby inheriting some of the teacher's reasoning capabilities. This allows a model with only 8 billion parameters to exhibit reasoning and tool-calling abilities approaching those of much larger models, significantly lowering the deployment barrier.
MCP Agent Development: Dual-Language Implementation in Java and Python
Another highlight of the tutorial is its coverage of dual-language development approaches for MCP agents:
- Java for MCP server development: Ideal for enterprise backend integration, seamlessly connecting with the Spring ecosystem
- Python for MCP server development: Ideal for rapid prototyping and day-to-day AI engineering work
Particularly noteworthy is that the tutorial focuses on MCP agents using the Streamable HTTP communication mechanism — the latest evolution of the MCP protocol. Compared to the previous SSE approach, it's more flexible and efficient, representing the future direction of MCP development.
To appreciate the value of Streamable HTTP, it helps to review the evolution of MCP communication mechanisms. The earliest MCP used stdio (standard input/output), suitable only for local inter-process communication. SSE (Server-Sent Events) was introduced next — a unidirectional server push technology where clients can only passively receive data streams, and each connection requires maintaining a persistent HTTP connection, which falls short in scenarios requiring bidirectional communication or multiplexing. The latest Streamable HTTP allows clients and servers to conduct more flexible bidirectional streaming communication via standard HTTP requests, supporting request-level streaming responses without maintaining long-lived connections, making it much friendlier for load balancing and stateless deployments. This means MCP servers can be more easily deployed in Serverless or containerized environments, significantly reducing operational complexity in production.
Practical Selection Recommendations Summary
Based on the analysis above, here are recommendations for developers working on LangChain/LangGraph + MCP agent development:
- Function Calling scenarios: Prefer DeepSeek V3 (0324+) or Qwen3
- Deep reasoning + tool calling: Use DeepSeek R1-0528 or Qwen3's thinking mode
- Local deployment scenarios: Qwen3's 8B/14B Dense models offer the best cost-performance ratio
- MCP development: Qwen3 currently has the most comprehensive MCP support
- Don't lock yourself into a single model: Stay familiar with multiple models and develop strong technical selection skills
The LLM landscape evolves extremely fast. Staying up to date with the latest version features is the best strategy for avoiding pitfalls.
Key Takeaways
Related articles

Harness AI Engineering Programming: A Practical Guide for Enterprise-Level Project Implementation
A deep dive into Harness AI engineering programming, covering SDD, Agentic Scale development, and practical solutions for enterprise AI coding challenges.

Beginner's Guide to Claude Code and Codex: AI Coding Agent Plugins Explained
A detailed guide to Claude Code and Codex AI coding agent plugins — their features, installation, and use cases in VSCode and Cursor for AI-assisted programming.
Gemini 5.2 in Claude Code: Real-World Testing — Does It Crush Opus on Cost-Effectiveness?
Real-world testing of Gemini 5.2 in Claude Code vs Opus across web design, coding, creative tasks, and Storm research — analyzing the open-source model's cost advantage and ideal use cases.