Learning Path for AI Agent Development: A Complete Guide from Core Architecture to Production Deployment
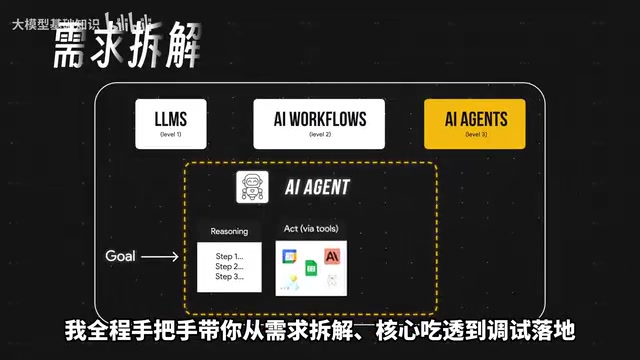
A systematic guide to AI Agent development from core architecture to production deployment.
This article outlines a complete learning path for AI Agent development across five key stages: core architecture (perception, planning, action), the ReAct paradigm and Chain of Thought reasoning, multi-agent collaboration patterns, RAG integration for private knowledge bases, and lightweight deployment strategies. It provides practical guidance on frameworks, debugging challenges, and business scenario adaptation.
Why Now Is the Best Time to Learn AI Agent Development
From intelligent agent performances on China's Spring Festival Gala stage to public interactions with humanoid robots, AI Agents are moving from the lab into the mainstream. This isn't just hype within the tech community — it signals the emergence of an entirely new career track.
2024 has been dubbed the "Year of the Agent" by the industry, with leading AI companies like OpenAI, Google DeepMind, and Anthropic all making Agents a strategic priority. Gartner predicts that by 2028, at least 15% of daily work decisions will be made autonomously by AI Agents. Behind this trend is the leap in large language model capabilities — models like GPT-4 and Claude 3 now possess sufficient reasoning and instruction-following abilities to make building reliable autonomous Agents feasible.
On Bilibili (a major Chinese video platform), a tutorial series claiming "all 748 episodes" of zero-to-hero Agent development has attracted significant attention. Marketing hype aside, the very emergence of such systematic tutorials illustrates a clear trend: Agent development is shifting from an exclusive domain of a few researchers to a skill accessible to everyday developers and even non-technical professionals.
This article outlines a complete learning path for AI Agent development based on such a course framework, helping interested readers build a clear knowledge map.
Core Agent Architecture: Perception, Planning, and Action
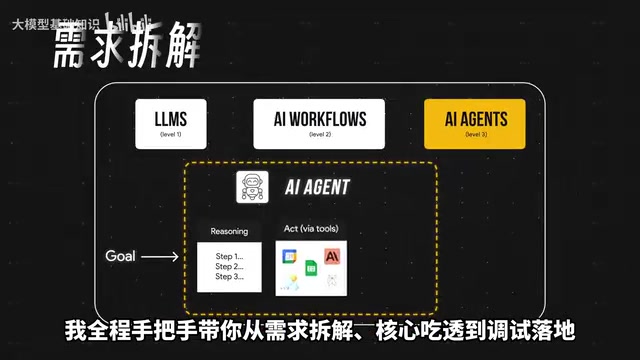
Every Agent system revolves around three core modules: Perception, Planning, and Action. This architectural design draws from classical models of intelligent agent behavior in cognitive science and mirrors the "perceive-decide-execute" loop in robotics. Beyond these, you also need to understand the following key components:
Memory Module: The Agent's Continuous Learning Capability
What fundamentally distinguishes an Agent from a standard LLM conversation is its memory capability. Short-term memory handles the current conversation context, typically corresponding to the model's Context Window. Long-term memory stores historical interaction data, usually implemented through vector databases or structured storage, enabling the Agent to maintain consistency and coherence across multiple conversation turns. In Stanford University's 2023 "Generative Agents" paper, it was precisely through an ingenious memory retrieval mechanism that 25 AI characters exhibited remarkably realistic social behaviors in a virtual town.
Tool Use: The Agent's Execution Capability
Tools are the Agent's "hands and feet" — through API calls to external tools, Agents gain capabilities like search, computation, and code execution. Understanding the Function Calling mechanism is the first hurdle for beginners.
Function Calling is a key capability introduced by OpenAI in June 2023. It allows large models to identify user intent during conversations and generate structured function call requests. Unlike traditional approaches that parse outputs with regular expressions, Function Calling incorporates tool description schemas during model training, enabling the model to natively understand when to call external tools and what parameters to pass. This mechanism was subsequently adopted by Anthropic's Tool Use, Google's Function Declaration, and other implementations, becoming the industry-standard interface for Agent development.
Planning Module: The Agent's Decision-Making Brain
This is the Agent's "brain," determining how to decompose steps and allocate resources when facing complex tasks. Mastering Task Decomposition methodologies is fundamental to building reliable Agents. Common planning strategies include: top-down decomposition (recursively breaking large tasks into subtasks), plan-execute-revise (generating a complete plan first, then executing step by step with dynamic adjustments), and search-based planning (such as Tree of Thoughts, which searches for optimal solutions across multiple reasoning paths).
ReAct Paradigm and Chain of Thought: How Agents Actually Work

The ReAct Paradigm Explained
ReAct (Reasoning + Acting) is currently the most mainstream Agent design paradigm. It makes the large model "think" before "acting" at each step, forming a Reasoning → Action → Observation loop. Understanding ReAct's prompt design and execution flow is the core skill for Agent development.
The ReAct paradigm originated from a 2022 paper jointly published by Google Research and Princeton University: ReAct: Synergizing Reasoning and Acting in Language Models. Before this, LLM reasoning (e.g., Chain of Thought) and action (e.g., WebGPT's tool calling) were separate research directions. ReAct's breakthrough was unifying both in an interleaved framework: the model first generates a Thought, then decides on an Action, then observes the result (Observation), cycling until the task is complete. This design gives Agent behavior both interpretability and execution power. Experiments showed that ReAct significantly outperformed pure reasoning or pure action approaches on knowledge-intensive QA and interactive decision-making tasks.
Chain of Thought (COT) Technique
Chain of Thought makes the Agent's reasoning process interpretable and debuggable. In practice, COT not only improves Agent accuracy but also allows developers to pinpoint which reasoning step went wrong. COT was first proposed by Google Brain in 2022, with the core finding that simply adding "Let's think step by step" to the prompt or providing step-by-step reasoning examples could dramatically improve LLM performance on mathematical reasoning, logical judgment, and similar tasks. In Agent scenarios, COT has evolved into more variants, such as Tree of Thoughts (allowing multi-path exploration) and Graph of Thoughts (allowing merging and backtracking of thought nodes).
Common Challenges in Agent Development and Mitigation Strategies
The most frequently encountered issues in real-world development include:
- Hallucination Control: Agents may fabricate non-existent tools or information. This stems from the generative nature of LLMs — they tend to produce content that "looks plausible" rather than strictly verifying facts. Mitigation strategies include strictly constraining the available tool list, validating Agent output formats, and introducing fact-checking steps.
- Loop Traps: Agents repeatedly execute the same operation at certain steps. This commonly occurs when the Agent fails to extract useful information from observation results. It can be mitigated by setting maximum iteration limits, detecting repetitive behavior patterns, and introducing "reflection" steps.
- Context Overflow: Critical information gets lost in long conversations. As conversation turns increase, early key information may be pushed out of the context window. Solutions include summary compression, key information extraction and storage, and hierarchical memory architectures.
There are no silver bullets for these problems — they require accumulated debugging experience through practice.
Multi-Agent Collaboration: Breaking Through Single-Agent Limitations

Three Mainstream Multi-Agent Collaboration Patterns
A single Agent's capabilities are ultimately limited. As task complexity increases, multiple specialized Agents need to work together. Common collaboration patterns include:
- Hierarchical: A primary Agent assigns tasks to multiple sub-Agents. Similar to corporate management hierarchies, the primary Agent handles task planning and result integration while sub-Agents focus on their respective subtasks. The GroupChat mode in the AutoGen framework is a typical implementation.
- Peer-to-Peer: Multiple Agents negotiate as equals and make decisions by voting. Suitable for scenarios requiring multi-perspective verification, such as code reviews where multiple Agents separately check security, performance, and readability before synthesizing their opinions.
- Pipeline: Agents process sequentially, where one Agent's output becomes the next Agent's input. Suitable for tasks with clearly defined processing stages, such as a chain structure of "Information Gathering Agent → Analysis Agent → Report Generation Agent."
Currently, the mainstream multi-Agent development frameworks include: Microsoft's AutoGen (supporting multi-Agent conversations and collaborative programming), CrewAI (emphasizing role division and task workflows), LangGraph (graph-based state management), and MetaGPT (simulating multi-role collaboration in a software company). Each framework has its own strengths — choose based on the complexity and controllability requirements of your specific scenario.
Tuning Tips for Precise Output
Getting Agents to "follow instructions" is the most time-consuming part of development. Key techniques include:
- Precise system prompt design: Clearly define the role, behavioral boundaries, and output requirements; avoid vague instructions
- Strong output format constraints (JSON Schema, etc.): Leverage structured output features to ensure Agents return parseable, standardized formats
- Feedback-based iterative optimization: Use an "evaluator Agent" to score output quality, creating an automated quality improvement loop
- Appropriate temperature parameter tuning: Temperature near 0 produces more deterministic and consistent outputs, suitable for scenarios requiring precise execution; higher temperatures suit tasks requiring creativity
Deep Integration of RAG and Agents: Unlocking Private Knowledge Bases
When Agents need to handle domain-specific knowledge, RAG (Retrieval-Augmented Generation) becomes an indispensable component.
RAG was first proposed by Facebook AI Research in 2020, originally designed to address LLM knowledge staleness and hallucination issues. Its core idea is to retrieve relevant document fragments from an external knowledge base as context before generating answers. With the maturation of vector databases and improvements in embedding model quality, RAG has evolved from an academic concept into a standard architecture for enterprise applications. The 2024 trend is upgrading RAG from "passive retrieval" to "active retrieval" — where the Agent autonomously decides when to retrieve and what to retrieve, forming what's known as the Agentic RAG pattern.
This stage requires mastering:
- Vector database selection and usage: Mainstream options include Milvus (open-source, suitable for large-scale deployment), Pinecone (fully managed, out-of-the-box), and Weaviate (supports hybrid search). Selection should consider data scale, query latency requirements, and operational costs.
- Document chunking and embedding strategies: A critical step that directly impacts retrieval quality. Chunks that are too coarse introduce noise; chunks that are too fine lose context. Common strategies include paragraph-based chunking, semantic chunking, and overlapping chunking with sliding windows. The choice of embedding model (e.g., OpenAI's text-embedding-3, BGE series) is equally important.
- Connecting retrieval results with Agent reasoning: Ensuring retrieved information is effectively utilized. This includes relevance ranking, result deduplication, multi-path recall fusion, and explicitly referencing retrieved content in the Agent's thinking steps.
- Practical application of development frameworks: Lightweight tools like LangChain (mature ecosystem, rich components) and LlamaIndex (focused on data indexing and retrieval) have significantly lowered the development barrier.
Embedding RAG capabilities into Agents — enabling them to reason and make decisions based on enterprise private data — is currently one of the most commercially valuable application directions.
Lightweight Agent Deployment and Business Scenario Adaptation
Comparing Three Deployment Approaches
After development is complete, deploying Agents to production environments presents another challenge:
- Cloud Deployment: Suitable for scenarios with high compute requirements and large user bases. You can directly call APIs from providers like OpenAI and Anthropic, or deploy open-source models on AWS/Azure. The advantage is elastic scaling; the disadvantages are costs that grow linearly with call volume and data privacy concerns.
- Edge Deployment: Suitable for privacy-sensitive, low-latency scenarios. With model quantization (e.g., GPTQ, AWQ) and inference optimization frameworks (e.g., vLLM, Ollama), small Agents can run on consumer-grade GPUs or even CPUs.
- Hybrid Approach: Core reasoning in the cloud, lightweight interactions on-premises. This is currently the mainstream choice for enterprise deployment, balancing reasoning quality with reduced latency and costs.
Customized Development for Different Business Scenarios
Different business scenarios have vastly different requirements for Agents. Customer service Agents need high fault tolerance and emotional understanding, capable of handling users' ambiguous expressions and emotional fluctuations. Data analysis Agents require precise computation and visualization capabilities with zero tolerance for numerical errors. Code Agents need rigorous logical reasoning and the ability to understand complex codebase structures and dependencies. Only through scenario-specific customized development — including building specialized knowledge bases, designing domain-specific evaluation metrics, and scenario-oriented prompt engineering — can real business value be generated.
The Right Mindset and Advice for Learning Agent Development
One additional note: claims like "from beginner to expert in seven days" are obviously exaggerated. Agent development involves multidimensional knowledge spanning LLM fundamentals, software engineering, and business understanding — it simply cannot be fast-tracked. However, the following points are certain:
- The barrier to entry is lowering: Thanks to the rapid iteration of frameworks like LangChain, AutoGen, and CrewAI, the technical threshold for building basic Agents is indeed dropping fast. Agent logic that required hundreds of lines of hand-written code in 2023 can now often be accomplished with just a few dozen lines of configuration.
- Demand is growing: Enterprise demand for Agent development talent is exploding. LinkedIn data shows that job postings containing the keyword "AI Agent" grew over 300% year-over-year in 2024, spanning finance, healthcare, education, e-commerce, and other industries.
- Practice matters most: Theoretical learning is just the starting point — extensive debugging and iteration is where real learning happens. In Agent development, 80% of time is spent debugging — observing Agent behavior, analyzing failure causes, adjusting prompts and parameters. There are no shortcuts in this process.
I recommend learners create a systematic study plan of 6–12 weeks, investing 10–15 hours per week, combined with hands-on project practice, to truly master the core competencies of Agent development.
Conclusion
AI Agent development is one of the most worthwhile technical directions to invest in today. From understanding core architecture to multi-Agent collaboration, from RAG integration to lightweight deployment, every stage requires solid learning and practice. Rather than chasing quick fixes, build a systematic learning path and continuously accumulate competitive advantages in this rapidly evolving field.
Key Takeaways
Related articles
Claude Code Installation Guide & The Five Stages of AI Programming Tools Explained
Complete Claude Code installation guide with the five stages of AI programming tools, from manual coding to agents. Learn 0-to-1 project building and 1-to-100 iteration challenges.

Enterprise-Level AI Project Rules Files: 5 Hard Rules + 6 Writing Techniques
AI keeps messing up your code? Learn 5 hard rules and 6 writing techniques for enterprise-level Rules files in Claude Code, Cursor & more, with templates.
Building Cloud Computing Clusters from Old Phones: Google and UCSD Explore a New Path to Sustainable Computing
Google and UCSD explore building cloud clusters from old phones, leveraging ARM chip efficiency to cut e-waste and data center carbon footprints.