LFM2.5 Local Deployment Hands-On: An 8B Parameter Model That Outperforms GPT-o3s in Tool Calling
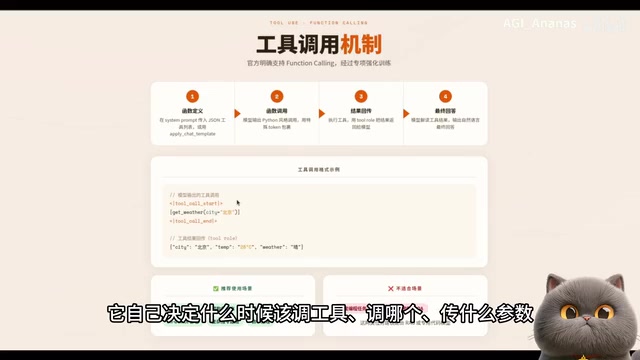
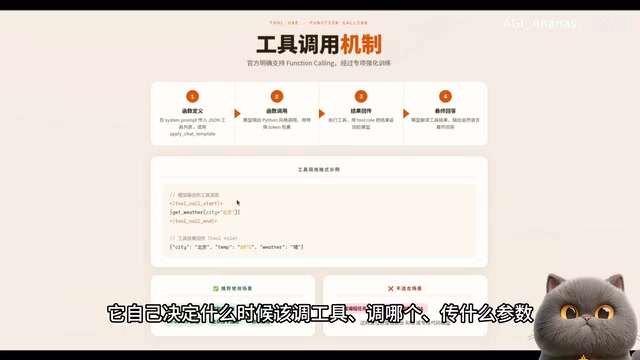
LFM2.5 locally deployed on 16GB VRAM outperforms GPT-o3s in tool calling with only 1.5B active parameters.
This article covers a full hands-on evaluation of Liquid AI's open-source LFM2.5 model, including its MOE + liquid convolution architecture, local deployment on a 16GB VRAM GPU with FP8 quantization, and GraphRAG tool-calling benchmarks against GPT-o3s. Despite activating only 1.5B of its 8.3B parameters, LFM2.5 achieves superior tool orchestration, faster inference, and lower memory usage than the 20B GPT-o3s.
Introduction: An Agent Model Built for Local Deployment
Liquid AI has open-sourced the LFM2.5 model. This isn't yet another behemoth that can only run on servers — it's a lightweight Agent model specifically designed for local deployment and edge devices. With a total of 8.3B parameters but only 1.5B activated per inference, it can run smoothly on consumer-grade GPUs while delivering surprisingly strong tool-calling capabilities.
This article provides a comprehensive evaluation of LFM2.5 across three dimensions: architecture analysis, local deployment troubleshooting, and hands-on GraphRAG tool-calling benchmarks.
LFM2.5 Architecture Breakdown: Why It's Both Fast and Efficient
The Hybrid Advantage of MOE + Liquid Convolution
LFM2.5 uses a MOE (Mixture of Experts) architecture, activating only 18% (~1.5B) of its 8.3B total parameters per inference. This directly translates to gains in both speed and memory efficiency.
MOE (Mixture of Experts) is a conditional computation architecture first proposed by Jacobs et al. in 1991, recently revitalized by Google's Switch Transformer and Mistral's Mixtral. The core idea is to distribute model parameters across multiple "expert" sub-networks, with a gating network (Router) selectively activating only a few experts per inference. This allows the model to have a large number of parameters (representing greater knowledge capacity) while keeping actual computation costs proportional only to the activated parameters. LFM2.5's ratio of 8.3B total to 1.5B activated parameters (~18%) means it has knowledge capacity approaching an 8B model but inference speed and memory usage closer to a 1.5B model.
But the more critical innovation lies in its layer design: of its 24 layers, 18 use Liquid AI's proprietary LIV (Liquid) convolution, with only 6 layers retaining traditional attention mechanisms.
Liquid convolution is Liquid AI's core technical innovation, inspired by the neural circuit dynamics of the C. elegans roundworm in biological neuroscience. Unlike the standard Transformer's self-attention mechanism, liquid convolution uses dynamically adjustable convolution kernels to process sequential information, with computational complexity that scales linearly with sequence length (O(n)) rather than the quadratic scaling of self-attention (O(n²)). This means that when processing 128K tokens of long text, the computational load of liquid convolution layers is roughly 1/1000th that of attention layers. Liquid AI first publicly introduced this technology in LFM1.0, and LFM2.5 is its evolved version for large-scale commercial use.
Standard Transformer attention mechanisms see computation grow quadratically with context length — a major performance bottleneck for long-sequence inference. Liquid convolution doesn't have this problem. By replacing most layers, the model achieves dramatically faster inference on long sequences with lower memory usage. The remaining 6 GQA attention layers ensure long-range comprehension capability, creating a complementary architecture.
GQA (Grouped Query Attention) is an attention optimization introduced by Meta in LLaMA 2, sitting between standard Multi-Head Attention (MHA) and Multi-Query Attention (MQA). It groups Query heads to share Key and Value heads, preserving MHA's expressiveness while significantly reducing KV Cache memory usage. In LFM2.5, the 6 GQA attention layers handle tasks requiring global dependency modeling (such as long-distance coreference resolution), while the 18 liquid convolution layers handle local feature extraction — forming a hybrid architecture with clear division of labor.
Training Scale and Agent-Specific Optimization
Training data reached 38 trillion tokens — three times that of the previous generation LFM2. More importantly, the model underwent large-scale reinforcement learning (RL) with specific optimization for tool calling and Agent tasks. It supports a 131K token context window, 9 languages (including Chinese), and uses the LFM1.0 open-source license that permits commercial use.
Looking at the official benchmarks, tool-calling-related BFCL-v3 and BFCL-v4 scores improved by 19 and 23 points respectively over the previous generation. BFCL (Berkeley Function Calling Leaderboard) is a function-calling evaluation benchmark published by UC Berkeley, specifically measuring LLM performance in real-world tool-calling scenarios. BFCL-v3 tests simple single-tool calling accuracy, while BFCL-v4 escalates to complex scenarios including multi-tool parallel calling, nested calls, and conditional branching. The benchmark covers the complete pipeline from API format parsing and parameter type inference to call timing decisions, making it one of the most authoritative standards for evaluating Agent capabilities. LFM2.5's significant improvement on v4 demonstrates a qualitative leap in complex tool orchestration.
The telecom test simulating real Agent scenarios improved by 74 points — an extraordinary margin. Instruction following (IFEval) reached 91.8, and math reasoning (Math500) reached 88.8.
LFM2.5 Local Deployment: Full Troubleshooting Log on 16GB VRAM
Environment Configuration Essentials
The test environment used an RTX 5060Ti with 16GB VRAM, Ubuntu 22.04, and CUDA 13.0 (Blackwell architecture GPU). Deployment used the vLLM framework, requiring a Python 3.12 environment.
vLLM is a high-performance LLM inference framework developed by UC Berkeley. Its core innovation, PagedAttention, manages KV Cache using a method similar to operating system virtual memory, boosting memory utilization from the typical 50-60% of traditional frameworks to over 90%. For function calling, vLLM uses a guided decoding mechanism to constrain model output to structured data conforming to JSON Schema, ensuring correct tool parameter formatting.
Key steps:
- Create a clean conda environment (Python 3.12)
- When installing vLLM, specify the Extra Index URL (required for CUDA 13.0)
- Model download is approximately 17GB
Critical Startup Parameters Explained
FP8 quantization is essential: The BF16 original is 17GB, which won't fit in 16GB VRAM. FP8 quantization allows normal operation with minimal quality loss. After startup, it occupies approximately 14GB VRAM.
FP8 (8-bit floating point) quantization is an inference acceleration technology first supported in hardware by NVIDIA's Hopper architecture (H100) and further optimized in Ada/Blackwell architectures. Compared to BF16 (16-bit brain floating point), FP8 halves the storage space per parameter while leveraging the GPU's FP8 Tensor Cores for nearly lossless computation. FP8 comes in two formats: E4M3 offers higher precision and is suitable for weight storage, while E5M2 has a larger dynamic range and is better suited for activation values. In practice, FP8 quantization typically impacts LLM output quality by less than 1% in benchmark score differences while delivering nearly 2x memory savings.
Max Model Length needs to be limited: Primarily to reserve VRAM for KV Cache.
Enable Auto Tool Choice + Native Mode: This is the master switch for vLLM tool calling. Without it, the API will outright reject Tools parameters. When Enable Auto Tool Choice is enabled, vLLM automatically detects tool-calling intent in model output and parses the results into OpenAI-compatible tool_calls format for the client.
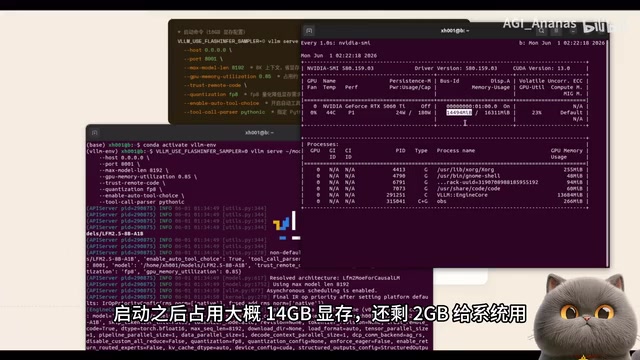
Important Limitations with 16GB VRAM
If you want to integrate with Agent frameworks like Hermes or OpenCore, they require at least 64K context — which 16GB VRAM simply cannot handle. The current configuration is suitable for writing your own code to call the API directly. For running full Agent frameworks, 24GB+ VRAM is recommended.
Additionally, the Tool Code Parser Pythonic parameter in vLLM 0.22.0 did not actually parse successfully in testing, because LFM2.5's tool-calling output includes Tool Code Start wrapper markers that the Pythonic parser doesn't recognize. You'll need to pair it with client-side parsing logic.
GraphRAG Tool-Calling Benchmark: LFM2.5 vs. GPT-o3s
Test Design
The test used the complete text of Romance of the Three Kingdoms, running through the full GraphRAG data processing pipeline (chunking, entity extraction, relationship extraction, community clustering). The four types of data were vectorized and stored in four separate vector databases, with four retrieval tools defined accordingly.
GraphRAG is a retrieval-augmented generation framework proposed by Microsoft Research in 2024, addressing the shortcomings of traditional RAG when handling complex relational queries. Traditional RAG only performs text chunking + vector retrieval, making it difficult to answer questions like "who has the best relationship with whom" that require a global knowledge graph. GraphRAG adds a knowledge graph construction step before vectorization: it first uses an LLM to extract entities and relationships from text, then applies the Leiden algorithm for community clustering on entities, generating multi-level summary indices. This way, retrieval can select the most appropriate index level based on question type — specific facts go through entity/relationship retrieval, while macro-level summaries go through community retrieval.
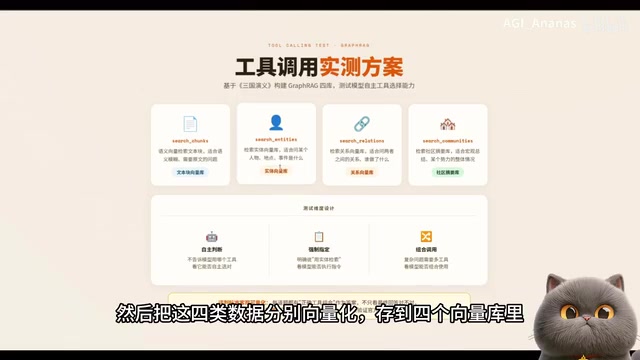
- Text chunk retrieval: Best for semantically ambiguous questions
- Entity retrieval: Best for questions about specific people or events
- Relationship retrieval: Best for questions about relationships between two parties
- Community retrieval: Best for macro-level summary questions
The comparison model was OpenAI's open-source GPT-o3s (20B parameters, MXP using 6 GPUs, deployed locally via Ollama).
Four-Round Test Results Comparison
Test 1: Autonomous Tool Selection
Both models correctly chose the text chunk retrieval tool. LFM2.5 consumed 4,141 tokens in 8.8 seconds; GPT-o3s consumed 3,616 tokens in 8.1 seconds. Performance was comparable.
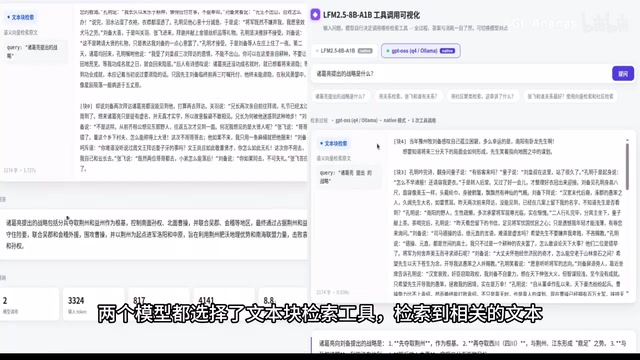
Test 2: Relationship Retrieval ("Who does Zhang Fei have the best relationship with?")
LFM2.5 consumed 3,203 tokens in 13.5 seconds; GPT-o3s consumed 1,630 tokens in 10.2 seconds.
Test 3: Community Clustering Retrieval
LFM2.5 consumed 2,262 tokens in 5.2 seconds; GPT-o3s consumed 1,943 tokens in 12.1 seconds. Here, LFM2.5 was noticeably faster.
Test 4: Multi-Tool Joint Calling
LFM2.5 correctly made two tool calls, consuming 4,643 tokens in 13.3 seconds. GPT-o3s, however, ran into problems — it redundantly made four calls, consuming 13,826 tokens in 33.1 seconds. This exposed GPT-o3s's weakness in complex tool orchestration.
Third-Party Travel Planning Task Validation
A more compelling set of third-party data: a travel planning task requiring 7 consecutive tool calls (checking weather for 3 cities, 2 currency conversions, sending an email, and setting a reminder).
| Metric | LFM2.5 (8B→1.5B) | GPT-o3s (20B→3.6B) |
|---|---|---|
| Tool Completion | 7/7 all successful | 3/7 (missed 4) |
| Memory Usage | 4.8GB | 11GB |
| Inference Speed | 266 Token/s | 146 Token/s |
| Total Time | 6.9s | 15s |
GPT-o3s activates more than twice the parameters of LFM2.5, yet its tool-calling capability was actually worse, slower, and more memory-hungry. This further confirms that LFM2.5's strategy of large-scale reinforcement learning specifically targeting Agent tasks is genuinely effective — parameter count isn't the sole determinant of Agent capability; training methodology and architecture design are equally critical.
Conclusion: Who Is LFM2.5 For?
LFM2.5 leverages 38 trillion tokens of training data plus large-scale reinforcement learning to achieve "fewer activated parameters, stronger Agent capabilities." For developers who need to deploy tool-calling Agents locally, this is currently one of the most cost-effective options available.
Ideal scenarios: Custom API calling, lightweight Agent development, edge device deployment
Not ideal for: Agent frameworks requiring 64K+ long context (16GB VRAM isn't enough), scenarios requiring native vLLM parsing support
If you have 24GB+ VRAM, you can unlock longer context windows and pair it with full Agent frameworks. Users with 16GB VRAM should write their own calling logic and interface directly with the API.
Related articles

A Gen-Z Woman Making $1.5M/Month: Deconstructing the Growth Methodology Behind AI Apps
Gen-Z indie dev Nicole built 4 hit AI apps earning $1.5M/mo. Deep dive into her industrialized UGC engine, traffic testing system, and minimalist tech stack.
Replit's AI Loops Workflow Explained: Multi-Agent Collaboration Replaces Prompt Engineering
Deep dive into Replit's AI Loops workflow: how orchestrators, parallel agents, and Computer Use Verifiers build automated closed-loop systems through multi-agent collaboration.
Claude Code + Skills: A Practical Guide to AI-Powered Test Case Generation
Learn how to use Claude Code + Skills to auto-generate enterprise-grade test cases. Covers AI Agent vs LLM differences, the four core capabilities, and the complete workflow from requirements to test cases.