MiniMax M3 Code Test: How Does It Stack Up Against DeepSeek?
MiniMax M3 outperforms DeepSeek in first-generation code quality and prompt comprehension across two real-world tests.
This article compares MiniMax M3 and DeepSeek through two practical coding tests: generating a Super Mario HTML game and building a backend admin system framework. M3 demonstrates superior first-generation quality, accurately understanding prompts without requiring multiple optimization rounds. It also shows lower Token consumption and benefits from multimodal capabilities, making it a strong contender among domestic AI coding models.
Introduction
The battle for programming prowess among Chinese AI models is heating up. After DeepSeek made its mark in code generation, MiniMax recently released its M3 model, also claiming exceptional programming capabilities. So who truly represents the ceiling of domestic coding models? This article puts MiniMax M3 through two real-world tests—HTML game development and backend management system scaffolding—and compares the results head-to-head with DeepSeek.
Test Environment Setup: Cloud Code + MiniMax M3
For this test, we used the Cloud Code plugin in VS Code paired with the MiniMax M3 model for code generation. Cloud Code is an AI programming assistant plugin in the VS Code ecosystem that supports multiple model integrations, allowing developers to call different vendors' LLM APIs through a unified interface for code generation, completion, refactoring, and more. Similar tools include GitHub Copilot, Cursor, Cline, and others that together form the mainstream AI-assisted programming toolchain. Cloud Code's core advantage lies in its open provider architecture—developers aren't locked into a single model and can flexibly switch between different AI backends based on task requirements, which is precisely what makes the side-by-side comparison between M3 and DeepSeek in this article possible.
The configuration process is relatively straightforward:
- Log into the MiniMax dashboard to obtain an API Key
- Add a new MiniMax provider in Cloud Code, selecting the Hailuo type
- Enter the API Key, then select the latest M3 model from the model list
- Set both the default model and fallback model to M3
You might not have noticed, but MiniMax M3 is a multimodal model—it supports not only pure text generation but also video, images, and other modalities. A multimodal model refers to an AI model capable of simultaneously processing and generating multiple data types (such as text, images, audio, and video). Unlike traditional text-only large language models, multimodal models integrate data representations from different modalities during training, giving them cross-modal understanding and generation capabilities. International models like GPT-4o and Gemini pioneered multimodal capabilities, and MiniMax M3 has followed this technical approach domestically. For programming scenarios, multimodal capability means the model can not only understand requirements described in text but can also potentially use screenshots, design mockups, and other visual inputs to assist code generation—particularly valuable in frontend UI development.
Regarding pricing, M3 offers two modes: monthly subscription (with usage refreshing on a timed window) and pay-per-use (purchasing a fixed Token quota that's consumed until depleted). Developers can choose flexibly based on their usage frequency.
Test One: Generating a Super Mario Game from Scratch
Test Method
The first test is quite hardcore—having M3 generate a Super Mario-style game in pure HTML from just a single prompt. No configuration files, no Cloud Code .md documentation—relying entirely on the model's understanding of the classic "Super Mario" game to recreate the game logic.
Generating a complete game in pure HTML (typically including inline CSS and JavaScript) places extremely high demands on an AI model's capabilities. The model needs to handle game rendering (Canvas API or DOM manipulation), physics engine (gravity, collision detection), game loop (requestAnimationFrame), user input handling (keyboard event listeners), and sound effects (Web Audio API) all within a single file. As a classic platform jumping game, Super Mario's core mechanics include precise jump physics models, terrain collision detection, character state machines (standing, running, jumping, dying), and more—all requiring the model to have deep "understanding" of game development. This test essentially evaluates the model's long code generation ability and complex logic organization capability.
The prompt was extremely concise: "Make an advanced Mario game, a Super Mario game, generate the game file in the root directory."
Generated Results
After a period of analysis and code writing, M3 generated a complete HTML game file in the root directory. The actual running results were impressive:
- Visual presentation: Complete game interface with character and scene elements all present
- Sound support: Built-in sound effects (synthesized via Web Audio API)
- Controls feel: Supports hold-to-charge jumping—the longer you hold, the higher you jump
- Core gameplay: Character movement, jumping, and other core mechanics run smoothly
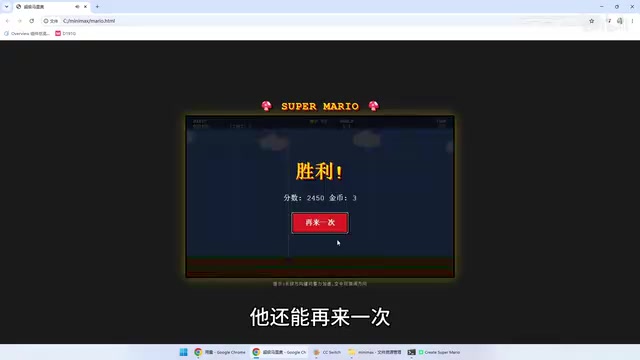
Of course, the generated game has some shortcomings: it lacks enemy elements like poison mushrooms, has no multi-level system, and the character can't proceed to the next level after dying. But considering this was generated from a single sentence with zero configuration, the overall completeness is quite impressive. According to tester feedback, community members also tried the same task with other models and DeepSeek, but M3's performance was the best.
Test Two: Backend Management System Framework Page
Test Background
The second test is more aligned with real development scenarios—using the exact same prompt to have M3 build a backend management system framework page, then directly comparing it with DeepSeek's previously generated results.
The test project is an npm-based frontend project, starting with an empty project directory running on localhost:3003. The prompt was identical to the one used when testing DeepSeek previously—no modifications whatsoever—ensuring a fair comparison.
M3 vs DeepSeek: First-Generation Quality Comparison
After receiving the prompt, M3 first performed task analysis and build planning, then progressively executed code generation. The final result outperformed DeepSeek's first-generation version across multiple dimensions:
1. More Accurate Layout Understanding
The prompt explicitly required the left navigation bar to use a card format, and M3 accurately understood this requirement and implemented it correctly. In AI programming, "Prompt Comprehension" is one of the key metrics for measuring a model's practical utility. It refers not only to whether the model can identify keywords in the prompt, but more importantly whether it can accurately grasp the user's implicit intent and domain conventions. For example, "card format" has a clear visual meaning in frontend UI design—an independent visual container with rounded corners, shadows, and padding—rather than simple list items. This ability to map from natural language to precise technical implementation relies on the model's learning of extensive frontend code and UI design patterns during training. DeepSeek, on the other hand, failed to understand this requirement on its first generation, producing a left navigation that was simply a list with icons, requiring subsequent prompt optimization to correct.
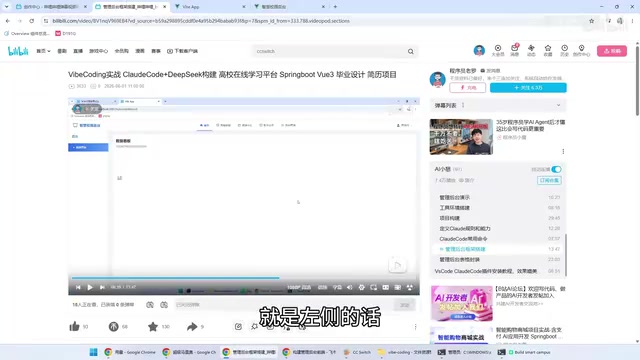
2. Proactive Feature Additions
M3 not only completed the basic framework scaffolding but also proactively read the project's system documentation files, adding additional functional modules based on contextual information—demonstrating stronger context comprehension. This proactive use of project context reflects the model's capability in "Agentic Coding"—not just passively executing instructions, but actively exploring the project environment and understanding project conventions to generate code that better fits actual requirements.
3. Detail Comparison
Both models had minor imperfections, such as unnecessary underlines and bullet points in navigation items. But overall, M3 achieved with zero optimization what DeepSeek required multiple rounds of prompt refinement to accomplish. Higher first-generation quality means fewer iteration cycles needed by developers, which directly translates to improved development efficiency.
Key Conclusion
M3's core advantage lies in its "get it right the first time" comprehension ability. With the same prompt, M3's first-generation result closely matches expectations, while DeepSeek requires multiple rounds of iterative optimization.
Token Consumption and Cost-Effectiveness Analysis
Throughout the testing process, M3's Token consumption was surprisingly low. After completing both the Super Mario game and the backend framework page tasks, usage statistics showed almost no significant change. In contrast, many developers have reported that using DeepSeek with Cloud Code is "very Token-hungry."
It's worth explaining the concept of Tokens and their impact on costs. A Token is the basic unit by which large language models process text—one Token corresponds to approximately 3-4 characters in English or 1-2 characters in Chinese. In API calls, Token consumption is divided into input Tokens (the prompts and context sent by the user) and output Tokens (the content generated by the model), with typically different pricing for each. In AI-assisted programming scenarios, since code generation tasks often require passing in large amounts of project context (such as file structures, existing code, configuration files, etc.), Token consumption is far higher than in ordinary conversation scenarios. Therefore, Token efficiency directly impacts developers' usage costs, which is why Token consumption is included as an important evaluation dimension.
Of course, there's a possibility of usage refresh delays, but from the actual experience, M3 does perform well in Token efficiency. For pay-per-use users, this means lower usage costs.
Summary and Recommendations
Through two rounds of real-world testing, MiniMax M3 demonstrated impressive code generation capabilities:
| Comparison Dimension | MiniMax M3 | DeepSeek |
|---|---|---|
| First-generation quality | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Prompt comprehension | More precise | Requires multiple rounds |
| Token consumption | Lower | Higher |
| Multimodal support | Video/image support | Primarily text |
| Game generation | Best results | Slightly inferior |
M3's biggest highlight is its deep prompt comprehension ability, delivering high-quality code on the first generation and significantly reducing the time developers spend repeatedly adjusting prompts. As a model that also supports multimodal inputs, M3 has indeed demonstrated strong competitiveness among domestic programming models.
It's worth noting that evaluating AI programming models is a multi-dimensional problem. This article's tests focus on frontend code generation and prompt comprehension. In other dimensions such as backend logic, algorithm implementation, and code debugging, different models may perform differently. When choosing tools, developers should make comprehensive considerations based on their actual tech stack and use cases.
Recommendations for developers: If you're pursuing a "get it right the first time" code generation experience, M3 is worth trying. If you're already comfortable with DeepSeek's workflow, you can also keep M3 as an alternative, switching flexibly between different scenarios. The landscape of AI-assisted programming tools is evolving rapidly—maintaining an open attitude toward new tools is key to staying ahead in the efficiency race.
Related articles
CosyVoice v3.5 in Practice: Solving the Performance Direction Challenge in AI Voice Acting
Hands-on testing of Alibaba's CosyVoice v3.5 instruction control and pronunciation correction vs Doubao TTS stability issues, with voice design tips and LLM debugging methodology for AI voice acting.
Gordon Ramsay's Wild American Food Adventure: A Culinary Journey Through Swamps, Smoky Mountains, and Texas
Gordon Ramsay explores Louisiana swamps, Smoky Mountains, and Texas in National Geographic's Uncharted — hunting nutria, catching rattlesnakes, and discovering America's diverse food roots.

Vibe Coding in Practice: The Right Way to Communicate with AI — Just Ask When You Don't Understand
Learn effective AI communication techniques for Vibe Coding: how to ask when you don't understand, discover plan gaps through follow-ups, and align on terminology with AI.