OpenAI Codex Record & Replay Explained: Show It Once and the AI Learns

OpenAI Codex's Record & Replay lets AI learn tasks from a single human demonstration.
OpenAI has introduced Record & Replay for Codex, a feature that lets users teach AI repetitive tasks by demonstrating them just once. Unlike traditional macro recording, Codex builds semantic-level understanding of workflows, enabling it to generalize across different inputs. The feature leverages Computer Use, Browser Use, and plugins to execute tasks across tools and platforms, marking a shift from prompt-based to demonstration-based AI interaction.
Overview
OpenAI has launched a brand-new "Record & Replay" feature for Codex, allowing users to teach AI how to complete repetitive tasks through a single demonstration. This is no longer traditional programming or prompt engineering — you simply perform the task as you normally would, and Codex learns your workflow and preferences, converting them into reusable "Skills."
Codex was originally released in 2021 as OpenAI's code generation model and served as the underlying engine for GitHub Copilot. In 2025, OpenAI repositioned Codex as a cloud AI software engineering agent capable of handling multiple coding tasks in parallel within a sandboxed environment, including writing functional code, fixing bugs, running tests, and submitting Pull Requests. The addition of Record & Replay marks Codex's expansion from a pure code generation tool into a general-purpose workflow automation platform, with capabilities that now extend well beyond traditional IDE-assisted programming.
How Record & Replay Works: Show It Once, Remember It Forever
The core concept behind this feature is remarkably simple: You show it what to do, and it learns.
The technical foundation of this design traces back to a classic paradigm in robotics and AI — "Learning from Demonstration" (LfD). In this paradigm, an agent doesn't acquire behavioral strategies through explicit programming but instead infers intent and rules by observing the operational trajectories of human experts. Early LfD was primarily applied to motion imitation in industrial robots, but Codex has migrated this concept to the software operation layer: instead of observing physical movements, it observes clicks, inputs, and navigation sequences on screen. The core challenge of this approach lies in extracting a generalizable "strategy" from a single demonstration, rather than merely recording a macro script.
Take OpenAI's own YouTube video publishing workflow as an example. The entire process involves extracting metadata from a publishing spreadsheet, locating the matching asset package, and filling in fields and settings one by one in YouTube Studio. While none of these steps are complex, repeating them manually every time is time-consuming and error-prone.

Now, users simply let Codex "watch" them perform the operation once: pulling the title and description, adding a thumbnail and English subtitles, and saving the video as private. Once complete, Codex automatically reviews the recorded content and transforms the learned knowledge into a reusable skill.
What Makes Up a Codex Skill: More Than Just Step Recording
What Codex learns isn't merely a mechanical recording of operational steps — it's a structured understanding of the entire workflow:
- Metadata location: Remembering which row of which spreadsheet the data is stored in
- Asset package organization: Understanding the file structure of the upload package
- Operational flow: How to add subtitles, save, and verify each upload

This structured understanding means that even when the specific content differs next time (different video titles, different thumbnails), Codex can correctly generalize and apply the workflow.
It's worth noting that this is fundamentally different from the recording features in traditional macro recorders or browser automation tools (such as Selenium or Playwright). Traditional macro recording is pixel-level or DOM-level exact reproduction — it records "click at coordinates (x,y)" or "enter text in the element with id abc," and breaks the moment the interface layout changes. Codex's skill learning, by contrast, operates at a semantic level — it understands the intent of "fill in the corresponding video title in the title field," so even if the position of interface elements changes, the skill can still execute correctly as long as the semantic structure remains intact. This leap from "operation recording" to "intent understanding" is the core value that large language models bring to automation tools.
Practical Application: From Learning to Independent Execution
In the demo video, OpenAI showcased the complete end-to-end workflow. When a user opens a new conversation thread, attaches the next video's asset package, and asks Codex to handle it, it can independently complete all steps:
- Match the asset package with the correct row in the spreadsheet
- Fill in all metadata fields
- Add the thumbnail and English subtitles
- Upload the video in private mode
- Verify that all content has been saved correctly
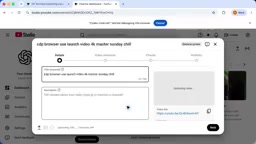
The entire process requires no further explanation of any steps or preference settings from the user.
Use Cases Go Far Beyond Video Publishing
OpenAI has made it clear that Record & Replay's applications extend well beyond the video publishing scenario. Typical use cases cited by the company include:
- Video publishing: The YouTube workflow demonstrated in the demo
- Pull Request management: Formatting and sharing code review requests according to team standards
- Calendar invite setup: Creating meeting invitations based on personal preferences
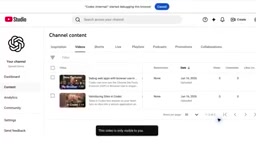
More importantly, the execution method is flexible — when a skill is invoked again, Codex can complete the task through Computer Use, Browser Use, connected plugins, or a combination of all three.
Among these, "Computer Use" is one of the most significant technical breakthroughs in the AI Agent space in 2024–2025. It refers to an AI model's ability to directly manipulate graphical user interfaces (GUIs) just like a human — moving the mouse, clicking buttons, typing text, and reading screen content. Unlike traditional API-based automation, Computer Use doesn't require the target application to provide a programming interface and can theoretically operate any software with a graphical interface. Anthropic was the first to introduce this capability in Claude in October 2024, and OpenAI subsequently followed suit in its Operator product and Codex. The underlying technology relies on the visual comprehension capabilities of multimodal large models — the model needs to "read" UI elements in screenshots and plan the correct sequence of operations.
This means Codex isn't limited to any single interaction method but can execute complex workflows across tools and platforms.
What This Means for AI Automation
This feature represents a significant shift in the interaction paradigm for AI assistants. Traditional AI automation requires users to precisely describe every step — essentially writing "natural language programs." Record & Replay transforms the interaction from "describing" to "demonstrating," dramatically lowering the barrier to entry.
The significance of this shift needs to be understood from a cognitive science perspective. Prompt engineering has been a core skill in AI applications since 2023, but it fundamentally requires users to have the ability to make tacit knowledge explicit — you need to translate "how I usually do this" into precise natural language instructions. Cognitive science research shows that a large portion of human expertise falls under "procedural knowledge" — the type of knowledge where you "know how to do it but can't articulate it clearly." For example, an experienced video operations specialist might not be able to list every single check they perform when publishing a video, yet they never miss a step when actually doing it. Record & Replay directly bypasses this cognitive bottleneck, allowing AI to learn from the behavior itself rather than from descriptions of the behavior — an approach known in human-computer interaction design as "Programming by Demonstration."
For workflows that are difficult to describe precisely in words but are repeated daily, this "learning by demonstration" approach may be far more efficient than any prompt engineering. Users don't need to think about how to translate their operational habits into instructions — they just need to do it once the way they normally would.
This also hints at the direction of AI Agent development: evolving from tools that require precise instructions into genuine assistants that can learn through observation. When AI can understand your way of working rather than merely executing your commands, the efficiency of human-AI collaboration will take a quantum leap.
Key Takeaways
Related articles
A Giant Shot: An AI Screenshot Tool with Built-in MCP That Lets AI Directly Control Your Computer
A Giant Shot is a desktop screenshot tool with a built-in MCP Server, offering 11 annotation tools, smart OCR, AI chat, and desktop automation for Cursor and Claude Desktop.

Three Essential Claude Code Configuration Techniques: A Practical Guide to CLAUDE.md, Memory & MCP
Master three Claude Code configuration techniques: use CLAUDE.md for project rules, Memory for auto-learning preferences, and MCP for connecting GitHub and external tools.
Token Doomsday: The Industry Truth Behind AI Coding's Spiraling Costs
GitHub Copilot shifts from flat-rate to per-token billing, sending dev costs from $29/mo to $1,000+. Uber burns its annual AI budget in months. A deep dive into Token Doomsday.