OpenAI Launches Long-Term Token Discounts: As Compute Scarcity Becomes the Norm, How Should Enterprises Lock In AI Capacity
OpenAI offers 1-3 year Token discounts as compute scarcity reshapes AI industry dynamics.
OpenAI has launched a long-term Token discount program for 1-3 year commitments, addressing growing enterprise demand for guaranteed compute capacity. As AI models grow more powerful and compute-intensive, physical constraints in GPU production, data center construction, and power supply create persistent bottlenecks. This move mirrors cloud computing's reserved instance model and signals AI's transition into critical infrastructure, with implications for how enterprises plan and secure their AI compute resources.
Compute Demand Outstrips Supply — OpenAI Enters Pre-Sale Mode
OpenAI CEO Sam Altman recently shared an important signal on social media: more and more customers are demanding guaranteed compute capacity from OpenAI. In response, OpenAI has officially launched a Token discount program for 1–3 year commitments.
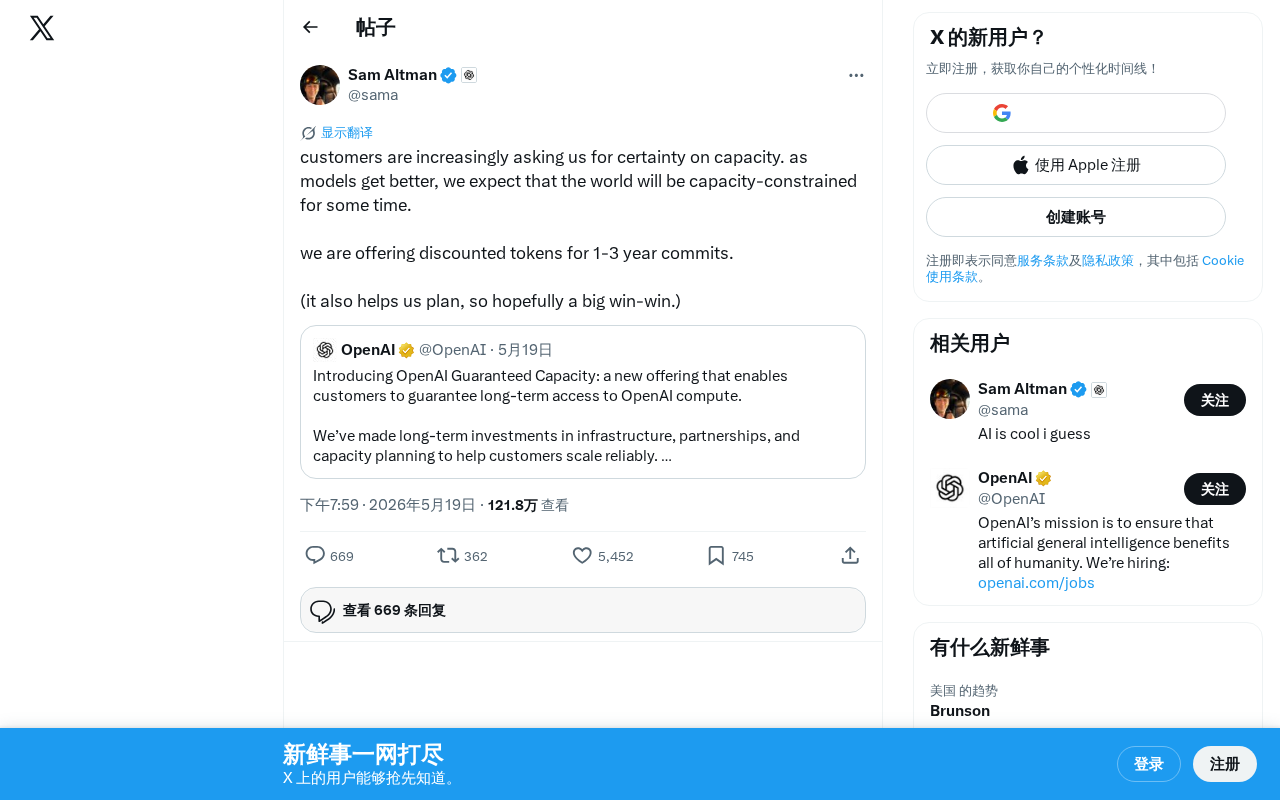
Altman wrote in his post:
"Customers are increasingly asking us for certainty of compute capacity. As models get better, we expect the world to be in a compute-constrained state for quite some time. We are offering discounted tokens for 1-3 year commitments. This also helps us with planning, so hopefully it's a win-win."
Behind this brief statement lies a profound transformation underway in the AI industry — a shift from competing on "model capabilities" to competing for "compute resources."
Why Has Compute Become a Bottleneck?
Improving Model Capabilities Are Driving Explosive Demand
With the continuous iteration of models like GPT-4o, o1, and o3, AI use cases are transitioning from experimental exploration to large-scale production deployment. Enterprise customers are no longer just "trying out" AI — they're deeply embedding it into core business processes, driving exponential growth in inference compute demand.
A key trend: more powerful models typically require more computational resources. Take reasoning models (like the o-series) as an example — they perform multi-step "thinking" when answering questions, consuming far more Tokens than traditional models. It's worth understanding what Tokens mean here — Tokens are the basic units that large language models use to process text. Models don't directly understand human "words"; instead, they split text into smaller fragments. In English, one Token corresponds to roughly 4 characters or 0.75 words; in Chinese, a single character is typically encoded as 1–2 Tokens. OpenAI's API charges based on total input and output Tokens, with significant price differences across models.
The o-series reasoning models employ a technical paradigm called "Chain-of-Thought Reasoning." Unlike traditional models that generate answers in one pass, reasoning models perform multi-step logical deduction internally, similar to how humans "think it through before answering." This mechanism significantly improves model performance on complex tasks like mathematics, programming, and scientific reasoning — but at the cost of multiplied computation. A simple analogy: traditional models are like answering by intuition, while reasoning models are like working through calculations on scratch paper before giving an answer — every step on that scratch paper consumes compute and Tokens. When enterprises deploy these models in high-frequency scenarios like customer service, programming, and data analysis, compute consumption skyrockets.
The Supply Side Faces Physical Constraints
GPU chip production cycles, data center construction timelines, power supply expansion periods — these are all physical constraints measured in years. Even with NVIDIA producing at full capacity and Microsoft and OpenAI aggressively building data centers, supply growth in the short term still cannot match demand growth.
Specifically, current AI training and inference primarily relies on NVIDIA's high-end GPUs, particularly the H100 and the latest B200 series chips. These chips are manufactured using TSMC's most advanced process nodes, and TSMC's advanced node capacity is itself extremely tight — needing to be allocated among AI chips, smartphone chips, high-performance computing chips, and other demand sources. From chip design to wafer fabrication, packaging and testing, through to customer delivery, the entire cycle typically takes 6–12 months. Data center construction takes even longer — from site selection, permitting, and construction to commissioning, it often requires 18–36 months. Power supply is another increasingly prominent bottleneck: a large AI data center can consume hundreds of megawatts, equivalent to the electricity consumption of a mid-sized city, and many regions simply cannot provide such massive incremental power in the short term.
Altman's statement that "the world will be in a compute-constrained state for quite some time" is a candid acknowledgment of this reality.
Long-Term Token Commitment Discounts: A Win-Win Business Model
Value for Customers
OpenAI's 1–3 year Token commitment discounts are essentially similar to the "Reserved Instances" model in cloud computing. AWS, Azure, and other cloud providers validated this model's effectiveness long ago.
Reserved Instances are a mature business model that has been running in the cloud computing industry for over a decade. Taking AWS as an example, users can choose 1-year or 3-year reservation periods, committing to use specific types and quantities of compute instances in exchange for discounts of up to 72% compared to on-demand pricing. Microsoft Azure and Google Cloud have similar "Committed Use Discounts" mechanisms. The economic logic is clear: cloud providers gain stable revenue expectations and capacity planning data, while customers receive price discounts and capacity guarantees. OpenAI bringing this model to the AI API space signals that AI services are transitioning from early experimental consumption to enterprise-level strategic procurement.
Specifically, this model delivers three types of value for customers:
- Cost certainty: Lock in Token prices and avoid potential future price increases
- Capacity certainty: Ensure sufficient compute resources are available when needed
- Budget predictability: Enterprise CFOs can incorporate AI spending into long-term budget planning
For enterprises that have already deeply integrated AI into their operations, the cost of compute disruption far exceeds the cost of a long-term commitment. It's like airlines signing long-term fuel contracts — not for speculation, but for operational stability.
Value for OpenAI
Altman candidly stated that "this also helps us with planning." Long-term commitments bring multiple benefits to OpenAI:
- Revenue predictability: Supports fundraising and financial planning
- Infrastructure investment justification: Clear future compute demand enables more precise data center investments
- Cash flow security: Stable cash flow from prepayments or long-term contracts is critical for a company burning billions of dollars annually
The importance of this cannot be overstated. OpenAI is currently in the most aggressive expansion phase in AI industry history. According to multiple reports, OpenAI's annualized revenue exceeded $5 billion in 2024, but operating costs are equally staggering — GPU leasing and data center operations alone consume most of the revenue, and when combined with model training and talent compensation, the company remains deeply unprofitable. At the end of 2024, OpenAI completed a $6.6 billion funding round at a $157 billion valuation, but this also means investors have extremely high expectations for its commercialization progress. In this context, long-term Token commitment contracts not only provide predictable revenue streams but also serve as important evidence of commercial sustainability for banks and investors, helping OpenAI secure future financing on more favorable terms.
Deeper Implications for the AI Industry Landscape
This move sends several signals worth noting:
AI has entered the "infrastructure" phase. When customers start demanding capacity guarantees and long-term contracts, it means AI APIs have transformed from "optional innovation tools" into "indispensable infrastructure." This is an important marker of industry maturation.
Compute is becoming a new strategic resource. Just as oil once defined the geopolitical landscape of the industrial era, compute is defining the competitive landscape of the AI era. Enterprises with sufficient compute reserves will gain significant competitive advantages.
AI service pricing models are evolving. From pay-as-you-go to long-term commitment discounts, and potentially to compute futures markets, AI service business models are rapidly converging with traditional commodity markets. In fact, startups are already exploring the concept of "compute exchanges," allowing enterprises with idle GPUs to rent out capacity to buyers who need it. If this trend continues, we may see "compute futures" markets similar to oil futures or electricity futures, where enterprises can lock in compute prices and capacity for future time periods. This financialization would not only help enterprises hedge against compute price volatility but also guide infrastructure investment through price signals. OpenAI's long-term Token discount program can be seen as an early form of this trend — essentially a forward contract. Notably, the cloud computing reserved instance market later spawned secondary trading markets where users can resell unused reserved capacity. Whether the AI Token market will develop similar liquidity mechanisms is equally worth watching.
Conclusion
Sam Altman's seemingly simple tweet actually heralds a new phase for the AI industry: compute scarcity will become the norm, not the exception. For enterprise decision-makers, the question to seriously consider is no longer just "which AI model to use," but "how to ensure sufficient AI compute availability for the next several years." In this battle for compute resources, enterprises that lock in resources early will have the upper hand.
Related articles
CodeGraph: Give Your Coding Agent a Code Map, Save 47% Tokens
CodeGraph is an open-source project with ~40K GitHub stars that uses Tree-sitter to build a local queryable code map, helping Claude Code and Cursor reduce 47% token usage and 58% tool calls.
AI Finishes Writing Code, Automatically Strikes a Gong to Alert You: Open-Source Physical Feedback Tool DAgent
A developer built a physical feedback device with chopsticks and a small gong that auto-strikes when AI finishes coding. Now open-sourced as DAgent, it also simulates IPO bell-ringing when creating new files.

Level Up Claude Code: Building an Enhanced Plan Mode with Grill Me
Learn how to install and use the Grill Me Skill for Claude Code, replacing AI guesswork with structured questioning to clarify requirements before generating execution plans.