OpenLLMVTuber: A Deep Dive into the Open-Source AI Virtual Character Framework

OpenLLMVTuber is an open-source framework that brings AI to life with voice, expressions, and Live2D characters.
OpenLLMVTuber is a 10K-star open-source AI virtual character framework that chains together speech recognition, large language models, text-to-speech, and Live2D character rendering into a seamless interactive pipeline. Its modular architecture allows flexible swapping of components at every layer, supporting both fully local deployment and cloud APIs. Key features include real-time voice interruption and visual perception via camera or screen capture.
From Chat Boxes to AI Characters That Can Talk and Move
The interaction paradigm for most AI applications still hasn't moved beyond the text chat box — you type a message, the model returns text, and that's where the interaction ends. But what if AI could do more than just type replies? What if it had a visual persona that could listen to you speak, respond with its own voice, and even "perform" its replies with matching facial expressions and gestures?
OpenLLMVTuber is exactly that kind of open-source project. With over 10K stars on GitHub, it's essentially a complete AI virtual character framework that chains together Automatic Speech Recognition (ASR), Large Language Models (LLM), Text-to-Speech (TTS), and a Live2D character frontend into a seamless interactive pipeline. Users speak into a microphone, the system transcribes the speech to text, sends it to a large language model for processing, converts the generated response back to speech via TTS, and finally the Live2D character on the frontend speaks along with synchronized expressions and movements — presenting an AI character that can hear, speak, and move.
Live2D, mentioned above, is a 2D animation technology developed by the Japanese company Cybernoids. It achieves quasi-3D dynamic effects through mesh deformation and parameter-driven animation while preserving the original 2D illustration style. Unlike traditional 3D modeling, Live2D doesn't require building a complete three-dimensional model. Instead, it splits a flat illustration into multiple layers (such as eyes, mouth, hair, body, etc.) and uses physics simulation and parameter mapping to achieve natural motion effects. This technology was originally widely used in Japanese visual novel games and mobile game character displays, and later became one of the core technologies in the VTuber industry. In OpenLLMVTuber, Live2D serves as the final presentation layer — mapping AI-generated voice and emotional information into the character's lip sync, expression changes, and body movements.

Two Usage Modes: Browser Debugging and Desktop Companion
OpenLLMVTuber offers two primary usage modes to fit different scenarios:
Web Mode
Opens directly in a browser, ideal for development debugging and feature demonstrations. You can quickly verify whether each module is configured correctly, observe the entire pipeline in action, and conveniently demo it within your team.
Desktop Mode
This is the more practical mode — the character floats on your desktop with a transparent background, essentially functioning as a "desktop pet." You can place the AI character in a corner of your screen and chat with it anytime while coding or reading documentation. This form factor transforms AI from a tool into a kind of "companion," delivering an experience that feels completely different from a traditional chat window.
Modular Architecture: OpenLLMVTuber's Core Competitive Advantage
The most noteworthy aspect of this project isn't how good the Live2D character looks — Live2D is just the final presentation layer. The real technical challenge lies in seamlessly connecting four major modules — speech recognition, LLM inference, speech synthesis, and the character frontend — while maintaining sufficient flexibility.
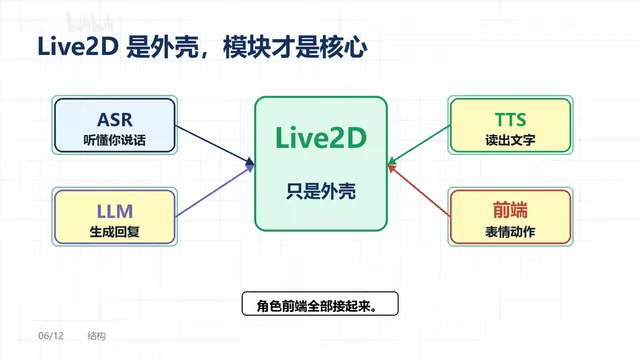
OpenLLMVTuber features a clean modular architecture:
- LLM Layer: Supports Ollama for local models, OpenAI-compatible API endpoints, and cloud services like Claude, Gemini, DeepSeek, and more
- ASR Layer: Swappable speech recognition solutions, both local and cloud-based
- TTS Layer: Similarly supports switching between multiple TTS engines
- Frontend Presentation Layer: Live2D character rendering with synchronized expressions and movements
ASR (Automatic Speech Recognition) is the key technology that converts human speech signals into text. Modern ASR systems are typically built on deep learning architectures — OpenAI's Whisper model, for example, is a classic end-to-end speech recognition solution trained on 680,000 hours of multilingual data, supporting recognition and translation in nearly 100 languages. For local deployment scenarios, common ASR solutions include various quantized versions of Whisper (such as faster-whisper), FunASR, and others; cloud-based options include Google Speech-to-Text, Azure Speech Services, and more. ASR latency and accuracy directly impact the fluidity of the entire conversation pipeline, making the choice of ASR solution one of the critical factors in system optimization.
The TTS (Text-to-Speech) side offers equally rich options. In recent years, driven by advances in deep learning, TTS technology has evolved from concatenative synthesis and parametric synthesis to end-to-end neural network synthesis. Current mainstream open-source TTS solutions include GPT-SoVITS (supporting few-shot voice cloning), the VITS series, Bark, CosyVoice, and others — all capable of generating near-human natural speech with support for emotion control and speech rate adjustment. Cloud TTS services like ElevenLabs and Azure TTS deliver even better performance in terms of audio quality and latency. In AI virtual character scenarios, TTS must not only generate high-quality speech but also output timestamp information for lip-sync, which places additional requirements on the choice of technology.
On the LLM side, Ollama deserves special mention. It's an open-source project specifically designed for running large language models locally, dramatically simplifying the process of deploying and running LLMs on personal computers. Users can download and run mainstream open-source models like Llama, Qwen, Gemma, and Mistral with a single command, while Ollama automatically handles model quantization, GPU acceleration, memory management, and other low-level details. More importantly, it provides an OpenAI-compatible API interface, meaning any application that supports the OpenAI API format can seamlessly switch to Ollama's local models. For OpenLLMVTuber, using Ollama means the entire conversation pipeline can run completely locally without sending any data to the cloud — a significant advantage for privacy protection and offline use cases.
The benefits of this design are obvious: for fully local deployment, use Ollama with local models paired with local ASR/TTS; for better quality and speed, connect to cloud APIs. Each layer can be independently swapped out — switching to a different LLM doesn't require rewriting the entire system.
Standout Features: Voice Interruption and Visual Perception
Beyond the basic voice conversation pipeline, OpenLLMVTuber includes several features with significant practical value:
Voice Interruption
When the AI character is speaking, you can interrupt it directly without waiting for it to finish the entire response. This feature may seem simple, but it's extremely important in real interactions — it makes the conversation rhythm closer to natural human communication rather than the rigid "wait for your turn" pattern.
From a technical implementation perspective, voice interruption involves multiple parallel processing challenges. The system must continuously monitor microphone input and perform Voice Activity Detection (VAD) while the AI character is playing audio. When it detects the user starting to speak, the system must immediately stop the current TTS audio playback, interrupt the ongoing streaming text generation, clear the audio buffer, and then seamlessly switch to a new round of speech recognition. This requires the entire system to adopt an asynchronous architecture design with event-driven coordination between modules. A poorly implemented interruption mechanism can lead to echo problems (the AI's voice being recaptured by the microphone) or state confusion, making this seemingly simple feature an important indicator of an AI conversation system's engineering quality.
Visual Perception
The project supports camera input, screen recording, or screenshot functionality, enabling the AI character to "see" you or the current screen content.
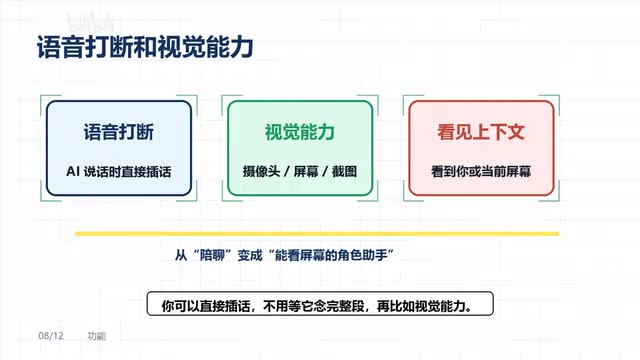
This capability dramatically expands the range of application scenarios. The character is no longer limited to passively listening and responding — it can actively perceive visual information and react accordingly. For example, if you're writing code, it can see the screen content and offer suggestions; in a livestreaming scenario, it can see the chat overlay and interact with it. This capability relies on multimodal large models (such as GPT-4o, Gemini Pro Vision, etc.) for image understanding. The system feeds captured frames as images into the multimodal model, which then generates more context-aware responses by combining visual information with the conversation history.
Deployment: Understanding the Full Pipeline Matters More Than Memorizing Commands
OpenLLMVTuber is not a simple "download and run" utility. The deployment process requires setting up a Python environment, installing dependencies, configuring the LLM interface, configuring speech services, and selecting a Live2D character frontend — the entire process has a certain technical threshold.
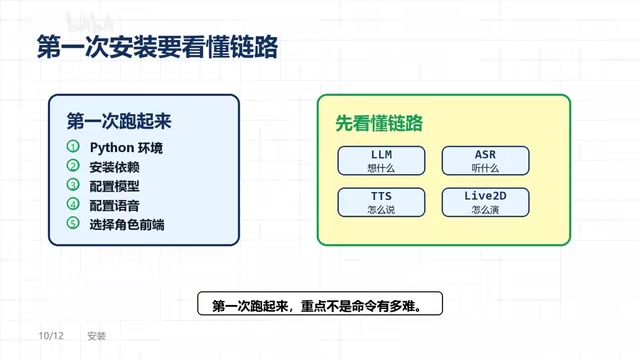
But as the project documentation emphasizes: The key to getting it running the first time isn't how difficult the commands are — it's understanding what each component (LLM, ASR, TTS, Live2D) is responsible for. Once you grasp the complete pipeline from "voice input → text → model inference → text → voice output → character performance," the entire project's logic becomes clear.
For users with some development experience, this is actually an excellent learning opportunity — through this project, you can gain a complete understanding of the full-stack architecture of an AI virtual character system. The selection criteria for each module, latency optimization strategies, and data flow patterns between modules are all highly valuable knowledge for real-world engineering.
Application Scenarios and Value Assessment
From a practical application standpoint, OpenLLMVTuber covers at least the following directions:
- Virtual Streamers / VTubers: Providing a complete technology stack for AI-driven virtual streamers
- Desktop AI Assistants: Desktop companion assistants with visual personas, offering a warmer experience than pure text interaction
- AI Characters / Digital Humans: Interactive AI characters for gaming, education, customer service, and other scenarios
- Agent Visualization Shell: Adding a speaking, expressive frontend persona to existing AI Agents
It's worth providing some context on the VTuber industry. VTuber (Virtual YouTuber) refers to content creators who use virtual avatars for livestreaming and video creation. The concept originated in 2016 with Japan's Kizuna AI and quickly grew into a massive industry. VTuber agencies like Hololive and Nijisanji now generate hundreds of millions of dollars in annual revenue. Traditional VTubers rely on real human performers using facial capture devices to drive virtual avatars, while AI-driven VTubers are entirely controlled by AI systems without requiring real-time human operation. The advantage of this model is the ability to run 24/7 with significantly reduced operational costs. The AI VTuber technology stack represented by OpenLLMVTuber is becoming a new trend in the industry, showing enormous potential especially in emerging scenarios like AI companionship and automated livestreaming.
The 10K-star community endorsement demonstrates that this project addresses a real need: In an era where LLM capabilities are already powerful enough, how do we evolve AI's interaction paradigm from cold text boxes to more natural, more expressive virtual characters? If you're exploring AI characters, virtual streamers, or desktop companion applications, OpenLLMVTuber is an open-source solution worth investigating in depth.
Related articles
Claude Code Installation & Setup Guide: Low-Cost Vibe Coding with Chinese AI Models
Step-by-step guide to installing Claude Code and configuring it with Chinese models like DeepSeek for low-cost vibe coding, including Node.js setup and CCSwitcher usage.
Keyroll: An In-Depth Look at a Stability-Focused Claude Refill Tool
In-depth review of Keyroll, a stability-focused Claude refill tool. Analyzing its core strengths, security implications, and compliance considerations for developers facing usage limits.
1700+ Top Developer Personal Website Collection: A Treasure Trove of Frontend Design Inspiration
A GitHub repo with 24,000+ stars featuring 1,700+ personal websites from top developers and designers worldwide. Styles range from minimalist to cyberpunk to 3D effects — perfect for design inspiration.