Pi: A Lightweight AI Coding Agent Framework — Setup & Hands-On Guide
Pi is a minimalist AI coding Agent framework enabling custom workflows with multi-model mixing.
Pi is a lightweight, composable AI coding Agent framework designed to give developers full control over their workflows. It supports multiple model providers, a plugin-based extension system, and shared skill files. This guide walks through building a custom Archon Dispatch extension using KimiK 2.6, demonstrating model mixing strategies that pair cost-effective models for implementation with powerful models for planning and review.
Why Do We Need a "Minimalist" Coding Agent?
The landscape of AI coding tools is undergoing a subtle shift. While Claude Code and Codex are powerful, they face two core issues: increasingly strict rate limits that frustrate developers, and massive codebases that make deep customization virtually impossible.
Rate Limiting is a request frequency cap set by API providers to prevent resource abuse. With tools like Claude Code and Codex, developers frequently call model APIs during intensive coding sessions, easily hitting per-minute request counts or daily token consumption limits, forcing workflow interruptions. This problem has become especially acute in 2025 — as AI coding tools have gone mainstream, the user base has surged, but GPU inference capacity hasn't scaled nearly fast enough to keep up, pushing providers to tighten quotas. Meanwhile, as large commercial products, Claude Code and Codex have massive, highly encapsulated codebases, making it nearly impossible for developers to modify their internal behavior to fit specific work scenarios.
Pi offers a fundamentally different approach — it's a minimalist coding Agent designed not to solve every problem out of the box, but to serve as a foundational framework on which developers build their own workflows. As Pi's tagline puts it: "There are many agent harnesses, but this one is yours."
This aligns perfectly with the current concept of "Harness Engineering": the toolchain itself matters more than the model. Harness Engineering is a methodology that emerged in the AI development community in 2025, built on a core insight: rather than chasing the latest and most powerful foundation models, invest your effort in optimizing the toolchain around the model — including prompt templates, context management strategies, task decomposition workflows, and quality gates. This philosophy stems from a practical observation: a well-designed workflow can enable a mid-tier model to produce results approaching those of a top-tier model, at one-tenth the cost or less. When we can no longer use the strongest models without limits, a carefully crafted workflow can make weaker models deliver high-quality results too.
Pi's Core Advantages & Architecture
Multi-Model Support: No More Vendor Lock-In
Pi natively supports a wide range of model providers without any workarounds. You can use:
- Kimi Code subscription (e.g., KimiK 2.6 used in this hands-on demo)
- Codex subscription
- OpenRouter (access to Qwen, Minimax, and other open-source models)
- GitHub Copilot
- Gemini
Configuration is straightforward: just modify models.json and auth.json to add new model providers. Take Kimi Code as an example — while it requires an API Key, it actually consumes subscription quota rather than charging per token. This is an increasingly popular pricing model where users pay a fixed monthly fee for a certain amount of usage time or request quota, rather than being billed precisely by input/output token count. In our testing, building a complete extension with a $40/month Kimi subscription consumed only 8% of the 5-hour limit and 2% of the weekly quota — far more cost-effective than Claude. The core value of this multi-model architecture is eliminating vendor lock-in: when a provider's service degrades, prices increase, or quotas tighten, developers can seamlessly switch to an alternative without modifying any workflow logic.
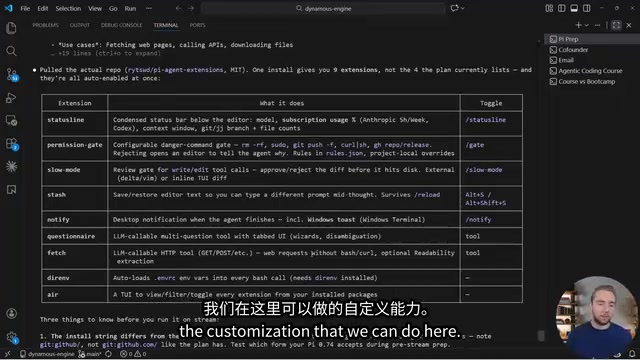
Extension Marketplace: Assemble Capabilities On Demand
Unlike Claude Code, which bundles all features built-in, Pi loads capabilities on demand through its extension system. Installing an extension takes just one command:
pi install @anthropic/pi-web-access
The extension marketplace offers a wealth of community-contributed tools, including:
- Web search & URL fetching
- Sub-agents: Allow the main Agent to spawn independent sub-agents that handle subtasks in parallel, each with its own context window and tool permissions, reporting results back to the main Agent upon completion
- MCP adapters: MCP (Model Context Protocol) is an open standard introduced by Anthropic in late 2024, designed to give AI models a unified way to connect to external data sources and tools. MCP uses a client-server architecture where the AI application acts as a client making requests, while MCP servers encapsulate access logic for databases, file systems, APIs, and other external resources. Through MCP adapter extensions, Pi can directly leverage the existing MCP server ecosystem, giving the Agent access to GitHub repos, Slack messages, database queries, and more — without writing custom integration code for each tool
- Status bar enhancements
- Permission gates (similar to Claude Code's hooks mechanism): A security mechanism that lets developers insert custom validation logic before the Agent executes sensitive operations (like writing files, running shell commands, or making network requests), ensuring the Agent doesn't perform dangerous actions without authorization
- Questionnaire interaction tools (similar to Claude Code's ask_user feature)
Skill System: Seamless Integration with Existing Workflows
Pi supports automatic skill file loading from the .agents/skills directory, and can be configured via settings.json to read directly from the .claude/skills directory, enabling skill sharing with Claude Code. This means you don't need to maintain two separate sets of skill files. Skill files are essentially structured prompt templates that define behavioral guidelines the Agent should follow in specific scenarios — such as code style preferences, testing strategies, commit message formats, and more. By sharing skill directories, developers can freely switch between Pi and Claude Code while keeping Agent behavior consistent.
Hands-On: Building the Archon Dispatch Extension
Extension Design Goals
The core objective of this hands-on project was to build a custom extension called "Archon Dispatch," turning Pi into a control panel for Archon background tasks. Archon is a GitHub Actions-based AI Agent orchestration system that lets developers define complex multi-step workflows and execute them asynchronously in the cloud. The design includes the following modules:
- Confirmation gate: Displays a confirmation dialog before executing a workflow, showing the workflow name, branch, and message preview
- Real-time status bar: Shows the number of currently running workflows and the latest logs
- Progress tracking: Tails log files in real time to avoid redundant reads — similar to the Unix
tail -fcommand, using file offset tracking to incrementally read new content rather than scanning the entire log file from the beginning each time - Completion callback: Sends a desktop notification when a workflow finishes and injects the results into the conversation context
- Workflow auto-discovery: Reads YAML configuration to determine whether Work Tree isolation is needed. Work Tree is a Git feature that allows checking out multiple branches simultaneously into different directories within the same repository. In the context of AI coding Agents, Work Tree isolation is crucial: when an Agent needs to execute multiple tasks in parallel, each task can run in an independent work tree without interference, avoiding the context-switching overhead of traditional git stash/checkout workflows
Build Process & Lessons Learned
The entire extension was written by the KimiK 2.6 model within Pi, consuming less than 100K tokens. Pi's meta-reasoning capabilities performed impressively throughout — meta-reasoning, in the AI Agent context, refers to a model's ability to understand and reason about its own runtime environment. In this specific scenario, KimiK 2.6 could not only write business code but also read Pi's own API documentation and extension interface definitions, understand the extension lifecycle hooks, event system, and registration mechanisms, and then generate extension code that conforms to the framework's specifications. This "bootstrapping" ability — an Agent leveraging its understanding of its own host environment to enhance itself — is an unexpected bonus of Pi's minimalist architecture: because the framework is small enough, the model can fully comprehend it within a limited context window.
However, the hands-on work also exposed limitations of using weaker models:
- Reasoning loops: Kimi occasionally fell into lengthy reasoning token loops. This is a common failure mode when large language models use Chain-of-Thought reasoning — when the model encounters uncertainty during reasoning, it may repeatedly restate the same reasoning step or oscillate between two contradictory conclusions, consuming massive reasoning tokens without converging on a final answer. This issue is more common with mid-tier models, and solutions typically include setting reasoning token limits or automatically interrupting and switching to a stronger model when loops are detected
- Log pipeline issues: Node.js's
detached: trueon Windows caused child process output to be lost.detached: trueis an option in Node.js'schild_process.spawn()for creating child processes independent of the parent. This usually works fine on Unix systems, but Windows has a fundamentally different process model — Windows lacks Unix's process group concept, and detached process stdin/stdout pipe behavior is inconsistent, preventing log streams from being captured correctly - Last-mile failure: The extension successfully launched workflows but failed to properly inject output back into the Pi session
This confirms a key insight: weaker models are great for 80% of the work, but the final 20% of fine-tuning and debugging often requires a stronger model to step in. This is precisely why model mixing strategies matter — it's not just cost optimization, but a form of cognitive division of labor: letting models of different capability levels each handle what they do best.
Model Mixing Strategy: The Optimal Approach for Cost-Effective AI Coding
Through this hands-on project, a clear best practice emerged:
| Task Phase | Recommended Model | Reason |
|---|---|---|
| Planning & architecture design | Opus/GPT-5 | Requires strong reasoning |
| Research & implementation | Kimi/Qwen/Minimax | High cost-efficiency, fast |
| Code review & bug fixing | Opus | Precise problem identification |
| Everyday Q&A | Any small model | No strong reasoning needed |
The economic logic behind this layered strategy is clear: in a typical coding task, the planning and review phases usually account for only 10-15% of total token consumption, yet their impact on final quality is decisive. The implementation phase, which accounts for over 80% of token consumption, primarily involves translating an already-determined design into code, requiring relatively less reasoning depth from the model.
Pi's "Pi Advisor" extension is designed precisely for this — it lets you set a review model (like Opus) and a work model (like Kimi), automatically coordinating between the two. The work model handles routine code generation and file operations. When a decision point requiring deep reasoning is encountered, the system automatically hands the context to the review model for judgment, then returns the decision to the work model to continue execution. This hybrid strategy can dramatically reduce token consumption while maintaining high-quality output.
Conclusion & Outlook
Pi represents an important direction for AI coding tools: shifting from "monolithic mega-tools" to "composable minimalist frameworks." This trend echoes the Unix philosophy in software engineering — each tool does one thing and does it well, achieving complex functionality through composition. In the AI Agent space, this means the framework itself should be as lightweight as possible, delegating specific capabilities to pluggable extensions and returning model choice to the developer.
Pi's value lies not in out-of-the-box capabilities, but in:
- Fully controllable workflow customization
- Model-agnostic architecture design
- Extremely low token overhead
- Community-driven extension ecosystem
For developers already practicing Harness Engineering, Pi may be the best current choice as a core toolchain component. Promising next steps include: building dedicated Archon workflows to systematically create Pi extensions, and refining model mixing strategies so that Kimi-tier models can consistently produce Opus-tier results. The latter is especially worth watching — if toolchain engineering can elevate mid-tier models' effective capabilities to near top-tier levels, it would fundamentally reshape the cost structure of AI coding tools, making high-quality AI-assisted programming accessible beyond just premium subscription users.
Related articles

Andrew Ng's Advanced AI Prompting Guide: Core Methods for Going from Beginner to Expert
Based on Andrew Ng's latest AI prompting tutorial, learn the core gaps between beginners and experts: providing context, overcoming sycophancy, iterative workflows, and four key principles.
AI Batch Rename Tool: One-Click File Name Standardization with LLM Semantic Understanding
Explore the AI Batch Rename Tool Pro v5.0: use LLM semantic understanding to intelligently standardize file names, with multi-engine API support and dual-model collaboration.

AI Engineering in Practice: The Progression Path from Vibe Coding to Enterprise-Level Development
Deep dive into AI engineering methodology, comparing Vibe Coding vs enterprise development, covering Claude Code, Codex tool selection, SuperPower plugin practices, and the path from prototype to production.