RAG System End-to-End Breakdown: From Vector Indexing to Production Optimization

How RAG technology makes LLMs precise and reliable in enterprise applications
This article provides a systematic walkthrough of RAG (Retrieval-Augmented Generation) technology. RAG overcomes three key LLM limitations — inability to access private data, high costs, and hallucination — by retrieving only the most relevant document chunks. The core pipeline includes document chunking and vector indexing, hybrid retrieval combining vector similarity and keyword matching, reranking for precision, and final answer generation. For production environments, three optimization techniques are essential: query clarification, multilingual expansion with query decomposition, and query classification across multiple knowledge bases.
Why Enterprise Applications Can't Do Without RAG
In the current wave of AI adoption, RAG (Retrieval-Augmented Generation) has become a standard technology in virtually every enterprise-grade AI application. Whether it's e-commerce customer service, corporate knowledge bases, or professional document Q&A systems, RAG is the critical bridge that transforms LLMs from "smart but unreliable" to "precise and production-ready."
LLMs have three core limitations: First, they can't access proprietary enterprise data or real-time information. Second, stuffing entire documents into the context window causes costs to skyrocket and inference speed to plummet. Third, when faced with massive amounts of information, they tend to hallucinate — generating inaccurate or even fabricated content.
The core idea behind RAG is remarkably simple — retrieve only the most relevant chunks. Imagine an employee handbook with 10,000 entries. When a user asks about annual leave policies, the system only needs to retrieve the ten entries related to time off and pass them to the LLM, rather than having the model read everything. The benefits are threefold: reduced token costs, faster response times, and over 90% reduction in hallucination rates.
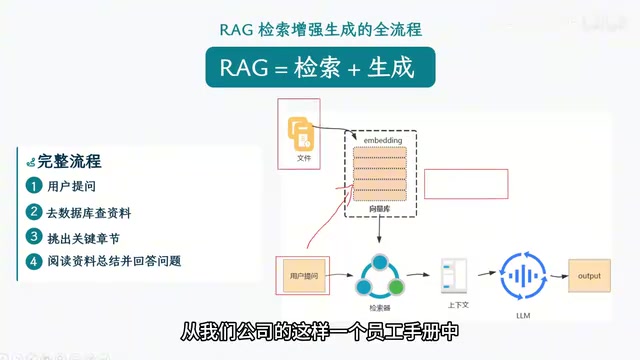
Vectors and Indexing: The Infrastructure of RAG
What Are Vector Embeddings
Vectors in AI applications are quite different from the two- or three-dimensional concepts you learned in high school math. They typically consist of hundreds to thousands of dimensions. The higher the dimensionality, the richer the semantic information they carry.
The core principle can be understood this way: if you simplify high-dimensional vectors into a 3D space for visualization, you'll notice that texts describing similar topics (e.g., content about athletes) cluster together in space after being converted to vectors, while texts about different topics (e.g., content about small animals) are distributed in a separate region. Semantically similar texts are also close together in vector space — this is the mathematical foundation of vector retrieval.
When a user asks a question, the system converts the question into a vector as well, then searches for the nearest text chunks in vector space. These chunks represent the knowledge most relevant to the user's question.
Choosing a Chunking Strategy
The first step in the indexing pipeline is splitting enterprise documents into appropriately sized chunks. Without chunking — converting an entire document into a single vector — there's essentially no difference from feeding the whole document directly to the LLM.
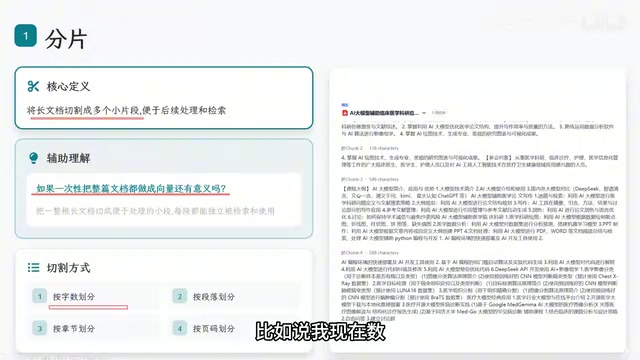
There are four common chunking approaches:
- By character count: Cut every 300 characters — simple but prone to breaking semantic coherence
- By paragraph: Split at line breaks, preserving semantic completeness within paragraphs
- By section: Ideal for structured documents, such as technical manuals split by chapter
- By page: Suitable for PDFs and other documents with clear page boundaries
There's no one-size-fits-all answer for which approach to use — the key is to decide based on your actual business scenario. Medical literature works well with section-based chunking, customer service FAQs with paragraph-based, and contracts might be best suited for page-based chunking.
Retrieval and Reranking: The Key to Precision
Retrieval Strategies
Once text chunks are stored in a vector database, the system needs to retrieve relevant content from the massive pool of chunks when a user asks a question. There are two main retrieval approaches:
- Vector similarity search: Uses cosine similarity or Euclidean distance to find chunks whose vectors are closest to the user's query vector
- Keyword matching: Traditional text matching — any document containing the keywords is included as a candidate
In production, both approaches are typically combined (hybrid retrieval), returning the Top-N results — for example, the 10 chunks with the highest similarity scores.
Why Reranking Is Indispensable
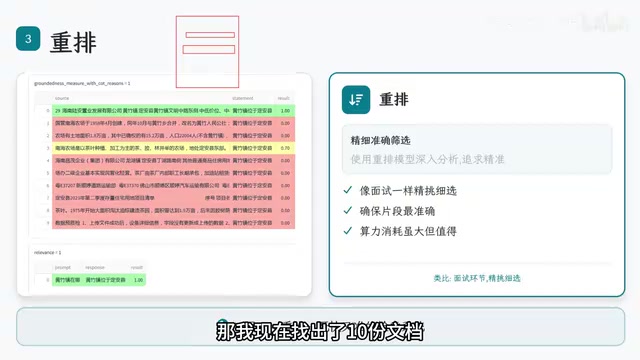
The retrieval stage is a coarse filtering process that follows the principle of "better to over-retrieve than to miss." The results inevitably contain a significant amount of noise. Take the question "Where is Huangzhu Town located?" as an example — among the 10 retrieved documents, there may be various entries that merely mention "Huangzhu" but have nothing to do with geographic location.
Reranking is the process of applying fine-grained scoring and reordering to the retrieved results. It uses more precise algorithms (typically cross-encoders) to re-evaluate the relevance of each chunk to the user's question, ensuring that only the highest-scoring, most relevant chunks are ultimately passed to the LLM.
Although this step consumes additional compute, it's absolutely worth it — if you skip reranking, the LLM faces a pile of noisy information, and all the effort put into the RAG system goes to waste.
Three Production Optimization Techniques
Optimization 1: Query Clarification
In practice, user questions are often vague and ambiguous. For example, if a user says "I want to write a technical document," the system can't determine which specific document they mean. In such cases, the LLM should first clarify the question by asking follow-ups like "Which technical document would you like to write?" — gathering enough information before entering the retrieval pipeline.
Optimization 2: Query Expansion
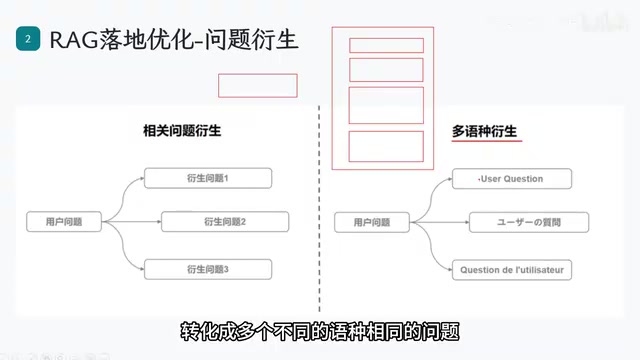
Query expansion operates on two dimensions:
Multilingual expansion: When the knowledge base contains documents in multiple languages — Chinese, English, Japanese, etc. — translating the user's question into multiple languages and retrieving separately can significantly boost recall rates.
Query decomposition: When a user asks a complex question (e.g., "How should I write a financial report document?"), the system breaks it down into multiple sub-questions — What are the formatting requirements? Are there any special conditions? What are the mandatory elements? Each sub-question is retrieved independently and the results are aggregated, preventing a single complex query from failing to surface sufficient information.
Optimization 3: Query Classifier
When an enterprise maintains multiple knowledge bases (HR, Finance, ERP, etc.), a query classifier can first determine which domain the user's question belongs to, then route it to the corresponding knowledge base for retrieval. This not only improves retrieval precision but, more importantly, significantly reduces system load in high-concurrency scenarios — such as when thousands of users are querying simultaneously.
Summary: Core Elements of Building a Reliable RAG System
A complete RAG system encompasses the following key stages:
- Input processing: Clarification, expansion, and classification
- Index construction: Proper chunking + vectorized storage
- Retrieval: Vector similarity + keyword hybrid search
- Reranking: Fine-grained scoring with cross-encoders
- Answer generation: Selecting an appropriate LLM to generate fact-based responses
By mastering these core stages, whether you're building an e-commerce customer service system or a proprietary enterprise knowledge base, you can make AI truly serve users with accuracy and reliability grounded in facts. RAG is not a set-it-and-forget-it solution — it's a systems engineering effort that requires continuous tuning based on your business scenario.
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.