RAG Technology Full-Stack Analysis: Core Principles, Enterprise Implementation & Learning Path
RAG has become the critical bridge connecting enterprise data with LLMs and an essential AI application need.
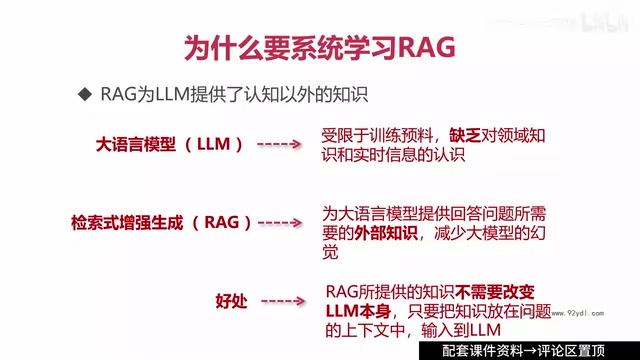
RAG (Retrieval-Augmented Generation) retrieves from external knowledge bases before LLM response generation, addressing model knowledge cutoff and hallucination deficiencies. It has become a core technology for enterprise AI deployment with mature implementations in pharmaceutical, home furnishing, and aviation industries. However, enterprises often fail due to lacking systematic understanding and iterative optimization capabilities. Systematic RAG learning requires covering vector databases, retrieval strategies, Agent integration, Knowledge Graph fusion, and emphasizing hands-on practice.
Why RAG Has Become Essential for AI Applications
It's been barely two years since ChatGPT launched, yet the large model landscape has undergone revolutionary changes. OpenAI's O1 and O3, along with China's standout DeepSeek R1—these powerful, efficient, and affordable models keep emerging, providing a solid foundation for the explosion of AI applications.
Currently, a massive number of enterprises both domestically and internationally have already integrated or are preparing to integrate AI applications to empower their businesses. Enterprise AI demand is rapidly shifting from general-purpose to scenario-specific, spawning a large number of highly vertical AI applications. Companies that can establish a rapid "scenario → pain point → AI capability" matching mechanism will gain an overwhelming advantage in this wave.
In this context, the two cornerstones of AI application development—Agents and Knowledge Bases—have become core competitive advantages. RAG (Retrieval-Augmented Generation) is the critical bridge connecting enterprise internal data with large language models.

What is RAG? An Intuitive Analogy
RAG (Retrieval-Augmented Generation) was formally introduced by Meta AI's research team in 2020 in their paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Its core idea is to combine an information retrieval system with a generative language model: before the model generates an answer, it first retrieves relevant document fragments from an external knowledge base, then feeds these fragments as context into the model, guiding it to produce more accurate, verifiable answers. This architecture fundamentally addresses two inherent deficiencies of purely parametric language models—knowledge cutoff dates and hallucination problems.
The best way to understand RAG is through a human analogy:
- Large Language Model = The human brain's central processing
- Agent = Human hands, capable of using various tools to complete tasks
- RAG = External knowledge that humans rely on
Human long-term memory capacity is limited—we can't memorize everything and still need to consult references when facing problems. Similarly, large language models are constrained by their training data and need external information sources for knowledge they haven't encountered. RAG is the core mechanism through which LLMs access external knowledge.
Three Core Values of RAG
- Expanding Cognitive Boundaries: Provides LLMs with knowledge beyond their training data, enabling them to answer domain-specific professional questions
- Reducing Hallucinations: LLM "hallucination" refers to the model generating content that appears reasonable but is actually inaccurate or entirely fabricated. This phenomenon stems from the fundamental nature of language models—they are statistical probability-based text prediction systems optimized for generating fluent, coherent text rather than guaranteeing factual accuracy. RAG injects real document fragments into the context, providing the model with reliable factual anchors that mechanistically constrain the model's divergence space. It remains one of the most practical solutions for reducing hallucinations in industry.
- Real-time Knowledge Updates: Knowledge provided by RAG can be continuously updated to stay synchronized with real-world information, without requiring model retraining
More importantly, using RAG doesn't require modifying the LLM itself—you simply place the retrieved knowledge into the question's context and feed it to the model. This "plug-and-play" characteristic significantly lowers the barrier for enterprises to deploy AI applications.
RAG's Current State in Industry
Industry Application Cases
RAG is deeply integrating across numerous industries. At the World Artificial Intelligence Conference, multiple presentations covered practical RAG applications:
- Pharmaceutical Industry: Yunnan Baiyao's production knowledge AI assistant, Baiyao RPS intelligent Q&A
- Home Furnishing Industry: Gold Medal Home's AI assistant "Xiao Jin"
- Aviation Industry: Shenzhen Airlines' internal AI knowledge base—Shenzhen Airlines AI Sales Helper
Thriving Open-Source Ecosystem
In the open-source domain, RAG-related projects continue to emerge. Beyond AI application development frameworks like LangChain and LlamaIndex that integrate RAG functionality, numerous standalone RAG open-source projects deserve attention: RAGFlow, QAnything, FastGPT, MaxKB, Dify, and more, offering developers a rich array of choices.
Strong Talent Market Demand
RAG technology is highly sought after across industries in the talent market. Beyond dedicated RAG engineer positions, product managers, backend engineers, project managers, architects, and other roles increasingly require RAG-related knowledge. In terms of industry distribution, beyond computer services, traditional industries like new energy, media, and securities also need RAG to empower their businesses.
Typical enterprise requirements for RAG talent include: retrieval optimization, reranking algorithms, and full-stack development capabilities.
Common Challenges in Enterprise RAG Implementation
Building a high-quality RAG system is not straightforward. In real enterprise cases, a common scenario unfolds: a team uses open-source RAG software combined with local documents to build an enterprise knowledge base, only to receive feedback like "the answers aren't good enough" or "AI is just so-so" during testing, ultimately abandoning the project and wasting resources.
The root cause is: A RAG system is a typical AI project that requires dynamic iteration. It demands not only a deep understanding of RAG's architecture, knowledge boundaries, and capability limits, but also mastery of RAG's development and iteration process. Only then can teams adapt to actual enterprise problems by applying existing strategies from the RAG framework or developing new optimization strategies.
Planning a Systematic RAG Learning Path
Three Major Learning Challenges
- Broad Technical Scope: RAG involves an extensive technology stack with limited structured learning materials, making it easy to lose direction
- Insufficient Practical Resources: Many resources cover theory, but few combine it with actual code implementation
- Difficulty Improving Accuracy: Facing complex enterprise data and diverse user queries, improving RAG accuracy is a significant challenge
Recommended Learning Roadmap
A systematic RAG learning path should follow a progressive approach:
- Foundation Stage: Start with RAG's three core components (Retrieval, Augmentation, Generation) to build the basic pipeline
- Optimization Stage: Adopt iterative optimization methods to validate and improve RAG system performance
- Extension Stage: Introduce Agents and Knowledge Graphs into RAG to enrich the capability matrix
- Advanced Stage: Combine model fine-tuning to further enhance RAG capabilities

Key Technology Stack Overview
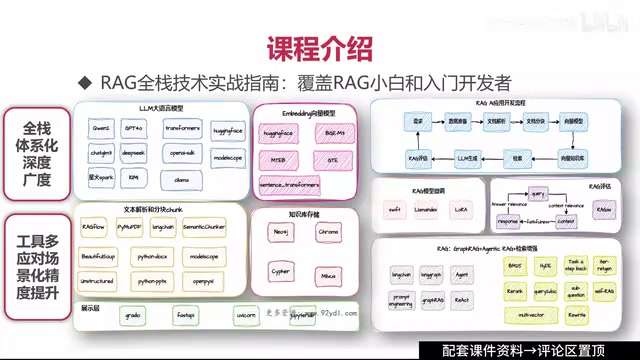
Systematic RAG learning should cover the following core technical areas:
-
Vector Database Selection: Vector databases are the core storage component of RAG systems. Unlike traditional relational databases that retrieve by structured fields, vector databases achieve semantic-level fuzzy matching through high-dimensional vector similarity computation (e.g., cosine similarity, Euclidean distance). After text is encoded by an Embedding model into floating-point vectors of hundreds to thousands of dimensions, vector databases use ANN (Approximate Nearest Neighbor) algorithms (such as HNSW, IVF) to complete billion-scale vector retrieval in milliseconds. Mainstream options include open-source Milvus, Qdrant, and Weaviate, as well as cloud services like Pinecone, each with different emphases on performance, scalability, and ease of use.
-
Document Parsing and Chunking Strategies: Choosing appropriate processing methods for different types of enterprise documents such as PDFs, Word files, and web pages. The quality of chunking strategies directly impacts retrieval quality. Common approaches include fixed-length chunking, semantic paragraph-based chunking, and hierarchical chunking based on document structure.
-
Embedding Model Selection: Choosing the appropriate vectorization model based on business scenarios. For Chinese-language scenarios, localized models like BGE and M3E often outperform general English models, while multilingual scenarios may consider cross-lingual models like multilingual-e5.
-
Retrieval Strategy Optimization: Pure vector semantic retrieval isn't a silver bullet. For queries containing proprietary terms, product codes, or precise numbers, traditional BM25 keyword retrieval is often more accurate. Hybrid Search merges vector retrieval and keyword retrieval results through algorithms like RRF (Reciprocal Rank Fusion), balancing semantic understanding with exact matching. Building on this, Rerank models (such as Cohere Rerank, BGE-Reranker) perform secondary precision ranking on recalled candidate documents, using Cross-Encoder architecture to score query-document relevance more granularly, significantly improving the quality of context ultimately fed to the LLM—a critical component of RAG accuracy optimization.
-
Agent Integration: Combining RAG with intelligent agents to implement more complex business logic. Agents can dynamically decide whether to trigger retrieval based on question type, which knowledge base to search, or even orchestrate multi-step retrieval workflows.
-
Knowledge Graph Fusion: Knowledge Graphs organize structured knowledge in "entity-relationship-entity" triplet form, excelling at expressing complex multi-hop reasoning relationships. Combining Knowledge Graphs with RAG (i.e., GraphRAG, proposed and open-sourced by Microsoft Research in 2024) compensates for pure vector retrieval's shortcomings in cross-document associative reasoning. For example, when users ask questions involving complex relationships between multiple entities, the graph can traverse along relationship edges for multi-hop reasoning—particularly suitable for enterprise scenarios with extensive entity relationships such as supply chain management, pharmaceutical R&D, and legal compliance.
Final Thoughts: Action Beats Observation
RAG is not just a technology—it's one of the most important implementation directions for AI application development. For developers, systematically mastering RAG means being able to deeply integrate large language models with actual enterprise business, creating truly valuable AI applications.
It's worth emphasizing that RAG, as an AI application, inherently involves significant uncertainty in development, requiring different methods to be selected based on actual circumstances. Therefore, learning RAG cannot remain at the theoretical level—hands-on practice is king. Only through continuous iteration in real projects can you truly understand the applicable scenarios and trade-offs of each strategy.
In the era of the AI mega-wave, opportunities favor the prepared. Rather than being a hesitant bystander, actively get in the game—start by building your first RAG application.
Key Takeaways
- RAG (Retrieval-Augmented Generation) is the critical technology connecting enterprise internal data with LLMs, reducing hallucinations, expanding cognitive boundaries, and supporting real-time updates through external knowledge
- In 2025, enterprise AI demand is shifting from general-purpose to scenario-specific; as one of the two cornerstones of AI application development, RAG already has mature implementations in pharmaceutical, home furnishing, aviation, and other industries
- Common enterprise RAG failures stem from lacking systematic understanding and iterative optimization capabilities—RAG is a dynamically iterative AI project, not a one-time deployment
- Systematic RAG learning should follow a Foundation → Optimization → Extension → Advanced path, covering vector database selection, retrieval strategies, Agent integration, Knowledge Graph fusion, and other core technology stacks
- RAG talent demand is strong and not limited to specialized positions—product managers, architects, and other roles increasingly require RAG-related capabilities
Related articles
 Tutorials
TutorialsCursor + Codex Dual-IDE Collaboration: A Practical Methodology for Open-Source Project Customization
A complete methodology for open-source project customization based on real-world experience, detailing the Cursor+Codex dual-IDE workflow, seven-stage process, MVP validation, and AI source code reading techniques.
 Tutorials
TutorialsCursor Multi-Agent in Practice: Building a Full-Stack Next.js Blog in 50 Minutes
Build a full-stack blog in 50 minutes using Cursor IDE's multi-Agent mode with Next.js, Clerk auth, and Supabase. Learn the 4-phase AI Agent workflow and key integration pitfalls.
 Tutorials
TutorialsBuilding an AI Software Factory from Scratch: A Cursor Engineer's Hands-On Experience with Multi-Agent Collaboration
Cursor engineer Eric shares practical insights on building an AI software factory: automation levels, guardrail design, parallel Agent management, and scaling to 1000+ Agents for 24/7 development.