Silent Revenue Sharing: A Smart Solution for Content Copyright Protection in the AI Era
Silent revenue sharing turns content piracy into free promotion by redirecting earnings to original creators.
This article examines YouTube's Content ID system as a proven model for copyright protection that silently redirects ad revenue from reposted content to original creators. Rather than deleting infringing content, this approach transforms piracy into free promotion. The piece explores its implications for the AI era, where style transfer and cross-modal conversion complicate copyright attribution, and discusses how Chinese platforms like Bilibili and Douyin could adopt similar mechanisms to shift from punishing infringers to compensating creators.
An Overlooked Copyright Protection Strategy
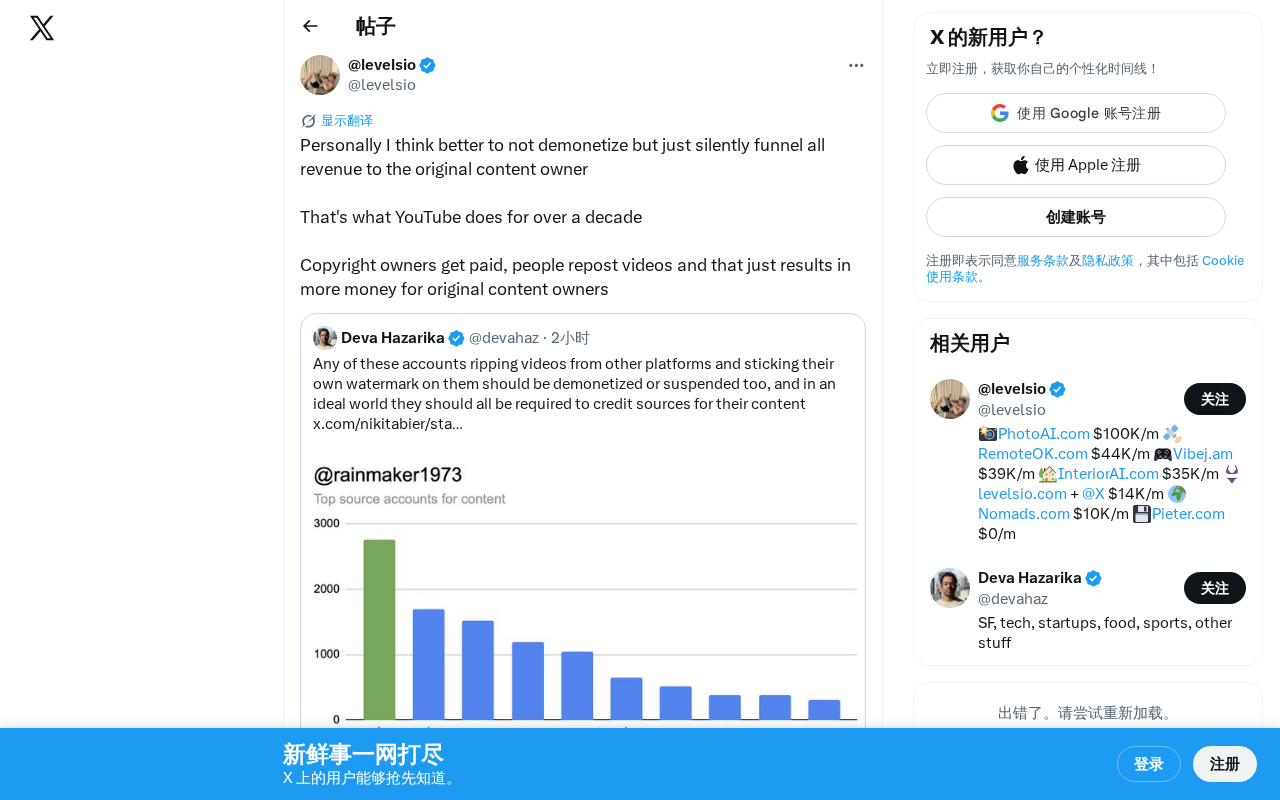
In an era where AI-generated content and content repurposing are increasingly rampant, protecting original creators' rights has become a core challenge in platform governance. Recently, a tech industry observer raised a thought-provoking point on Twitter: instead of directly demonetizing infringing content, why not quietly redirect all revenue to the original content owner?
YouTube's Content ID System: Over a Decade of Silent Revenue Sharing in Practice
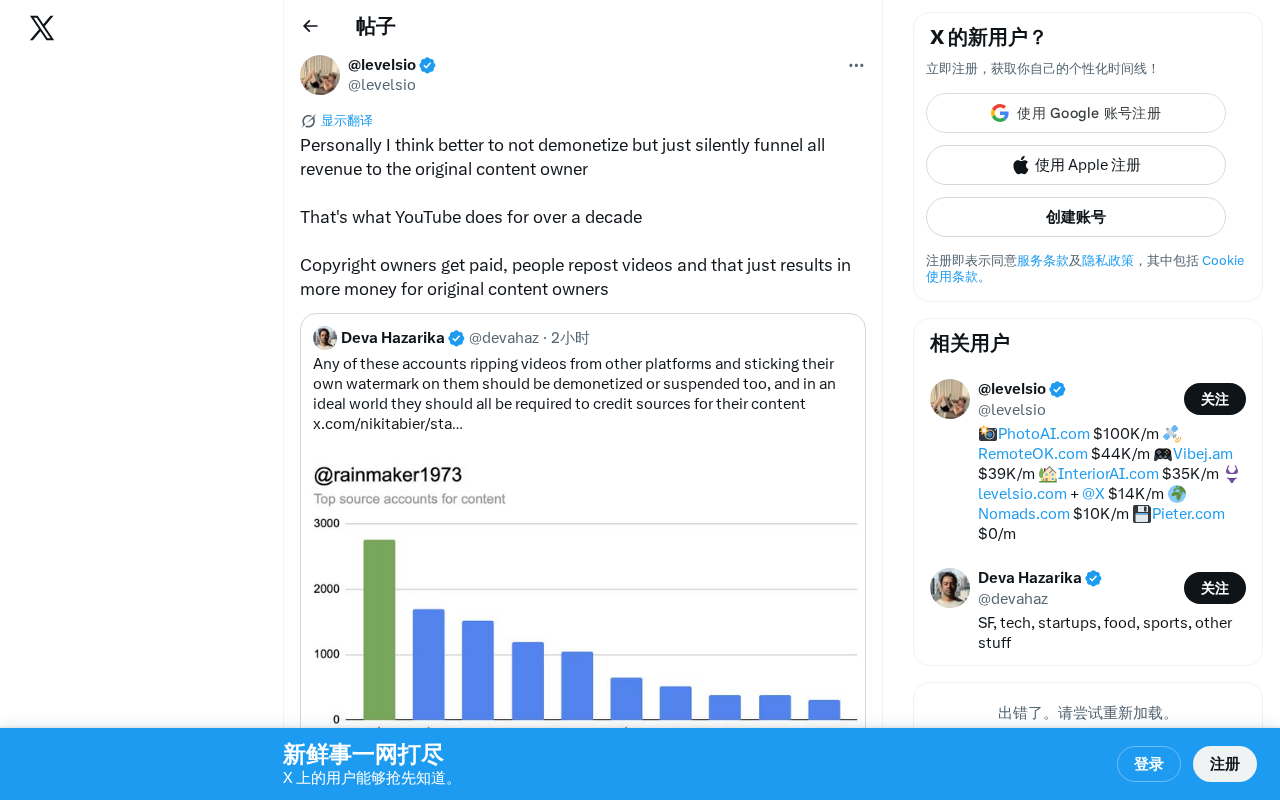
The blogger pointed out that YouTube has actually been executing this strategy for over a decade. The core mechanism is the well-known Content ID system:
- No deletion, no banning: When the system detects reposted or repurposed content, it doesn't immediately take down the video
- Silent revenue transfer: The video continues to exist and generate views, but ad revenue automatically flows to the original copyright holder
- Win-win-win: Reposters gain exposure (though no income), viewers get to see the content, and original creators earn additional revenue
The brilliance of this model lies in transforming "copyright infringement" into "free promotion." Every repost becomes a distribution channel for the original creator, rather than a theft of their interests.
How Content ID Works Under the Hood
YouTube's Content ID system is one of the world's largest digital rights management systems. Its technical core is based on audio fingerprinting and video fingerprint matching algorithms. Copyright holders first upload their original content to the Content ID database, where the system generates a unique digital fingerprint for each piece of content (similar to human DNA). When any user uploads a new video, the system compares it against over 100 million reference files in the database within seconds. Even if the video has been cropped, sped up, filtered, or mixed with other content, the system can still identify matching segments with extremely high accuracy. Copyright holders can choose from three actions: block the video, track viewing data, or monetize the video and collect ad revenue. According to official Google data, Content ID has cumulatively paid out over $9 billion in revenue to copyright holders. This figure alone demonstrates the commercial viability of the silent revenue sharing model — it's not a theoretical concept, but a mature business model validated over more than a decade.
What Silent Revenue Sharing Means for the AI Content Ecosystem
The Blunt Approach Most Platforms Take Today
Currently, most platforms handle content infringement in a fairly blunt manner:
- Directly deleting infringing content
- Banning reposter accounts
- Revoking monetization privileges
These approaches may seem "just," but they offer no direct financial compensation to original creators. Once content is removed, creators receive neither traffic nor revenue.
Looking at the evolution of platform governance philosophy, internet content governance has gone through several distinct phases. The early "Safe Harbor" principle granted platforms immunity from liability as long as they promptly removed infringing content upon notification — this principle originated from Section 512 of the 1998 U.S. Digital Millennium Copyright Act (DMCA). Subsequently, Article 17 of the EU's 2019 Directive on Copyright in the Digital Single Market required platforms to take more proactive filtering responsibilities, marking a shift from "notice-and-takedown" to "filter-and-prevent." YouTube's Content ID model represents a third path: neither passively waiting for reports nor simply filtering and deleting, but establishing an automated interest distribution mechanism. This "market-driven governance" approach is increasingly influencing the direction of global copyright policy.
Three Key Advantages of Silent Revenue Sharing
By comparison, the silent revenue sharing model offers several notable advantages:
- Aligned economic incentives: Original creators are motivated to produce more quality content, since they benefit even when their work is reposted
- Reduced confrontation costs: Platforms don't need to invest massive resources in content review and takedown operations
- Self-regulating ecosystem: Reposters naturally decrease when they find no profit in it, or they transform into legitimate distribution channels
Unique Challenges of Copyright Attribution in the AI Era
However, this model faces new challenges in the AI era. When AI can deeply adapt original content, transfer styles, or even perform cross-modal conversions, accurately identifying the "original content owner" becomes extremely complex. A piece of text rewritten by AI into a video, a painting transformed by AI into a 3D model — copyright attribution in these scenarios is far more complicated than simple video reposting.
Copyright attribution in the AI era involves challenges at multiple legal and technical levels. First, the standard for determining "substantial similarity" needs to be redefined: in traditional copyright law, the core criterion for judging infringement is whether "substantial similarity" exists between two works. But when AI performs style transfer (such as applying Van Gogh's style to a photograph) or cross-modal conversion (such as turning a novel into an animation), the final product may look completely different from the original in form while being highly dependent on the original in creative essence. Second, there's the copyright issue of training data: large language models and image generation models use massive amounts of copyrighted content during training, and whether the generated results constitute "derivative works" of the training data remains legally unsettled across jurisdictions. Landmark lawsuits in 2024, such as The New York Times v. OpenAI and Getty Images v. Stability AI, are driving the formation of legal frameworks in this area, and their rulings will profoundly influence the design direction of copyright protection mechanisms in the AI content ecosystem.
How Chinese Content Platforms Can Learn from Silent Revenue Sharing
Domestic platforms like Bilibili, Douyin, and Xiaohongshu face equally severe content repurposing problems. Current approaches mostly rely on a "report-review-takedown" workflow, which is inefficient and yields zero benefit for original creators.
If these platforms could adopt YouTube's silent revenue sharing mechanism and build automated revenue distribution systems based on content fingerprint recognition, they might be able to protect creators' rights while maintaining the vitality of their content ecosystems.
Content Fingerprinting is the foundational technology for implementing this mechanism. Its principle involves extracting unique and robust feature vectors from multimedia content. For audio, commonly used technologies include Chromaprint and Echoprint, which generate compact hash values by analyzing spectral features. For video, spatiotemporal feature extraction is required, including keyframe analysis and motion vector matching. In recent years, the introduction of deep learning has significantly improved fingerprint recognition's resistance to tampering — even if content has been re-encoded, flipped, or watermarked, it can still be accurately matched. However, fingerprint recognition for text content remains a challenge, especially for AI-rewritten text where the semantics are identical but the expression is completely different. Traditional character-level comparison is virtually useless in these cases, requiring semantic embedding vector similarity calculations instead. If domestic platforms want to implement silent revenue sharing, they need sustained investment in these technical areas.
This is not just a technical issue — it represents a fundamental shift in platform governance philosophy: from "punishing infringers" to "compensating creators."
Conclusion
In the game between content creation and distribution, the optimal solution is often not zero-sum confrontation, but finding an interest distribution model that all participants can accept. While the silent revenue sharing model is far from perfect, it offers a paradigm worth serious consideration: letting market mechanisms, rather than administrative measures, solve copyright problems.
Key Takeaways
Related articles
OpenAI Codex Cloud Task Delegation: The Complete Workflow from VS Code to PR
A detailed guide to OpenAI Codex extension's cloud task delegation, covering the complete workflow from initiating cloud coding tasks in VS Code to reviewing changes and creating Pull Requests.
Coze Workflow in Practice: Complete Tutorial for AI One-Click Product Promo Video Generation
Step-by-step guide to building a Coze workflow for AI product promo videos, integrating HappyHours and Jimeng across 12 nodes with nine-grid storyboards and polling loops.

Getting Started with Claude Code: 5 Key Differences from Traditional AI Chatbots
Explore 5 key differences between Claude Code and traditional AI chatbots like ChatGPT, covering interaction, context, execution, memory, and tool integration.