Six Core Concepts of AI Large Language Models: The Complete Evolution from Chatbot to Autonomous Worker

A clear evolution chain explaining how AI went from chatting to autonomously getting work done.
This article breaks down six core AI concepts — Agent, RAG, Function Calling, MCP, Skill, and Harness — across four evolutionary stages. Starting from how LLMs understand language and manage context, it progresses through retrieving private data with RAG, executing real-world tasks via Function Calling and MCP, achieving autonomous planning with Agents, and ensuring safety through Skills and Harness.
Introduction: The Generational Gap Between 10 Minutes and 3 Seconds
Getting AI to handle a complex task used to be a chore — extracting information from documents and generating a report meant writing prompts, calling APIs, managing context, and debugging repeatedly. The whole process took at least 10 minutes. Now, with the right Agent and Skill setup, you might only need to say one sentence, and it's done in 3 seconds.
This isn't a performance improvement — it's a generational leap. But the prerequisite is understanding what Agent, Skill, Harness, RAG, MCP, and Function Calling actually mean.
This article follows one clear thread — how AI evolved from merely chatting to actually getting things done — broken down across four stages that cover all six core concepts.
Stage One: Understanding Human Language — LLM, Tokens, and Prompts
Two Fundamental Capabilities of Large Language Models
The core technology behind AI conversations is the Large Language Model (LLM). It relies on two key capabilities:
- Natural Language Understanding (NLU): No matter how you phrase things — colloquially, vaguely, or emotionally — it filters out the noise like a real person and accurately identifies your true intent.
- Natural Language Generation (NLG): Based on what it understands, it generates high-quality responses and adjusts tone to fit the context — formal for professional queries, casual for small talk.
Together, these two capabilities form the foundation of conversational AI and serve as the bedrock for all AI applications.
Tokens: The Smallest Unit of Text Processing
AI doesn't read text character by character like humans do. Instead, it breaks text into smaller units called Tokens. For example, the Chinese phrase "杭州好玩吗" ("Is Hangzhou fun?") gets split into four tokens: 杭州/好/玩/吗. Each token maps to a numerical ID (Token ID) — internally, the model only works with numbers.
The model generates responses through prediction: based on existing tokens, it calculates the most likely next token, then chains them together one by one to form complete sentences.
The practical significance of understanding tokens is this: the "context window" you often hear about is measured in tokens. If a model can handle 8,000 tokens, that's how much information it can "see" at once — anything beyond that gets forgotten.
Prompts and Prompt Engineering
A Prompt is your starting point for communicating with AI — your question or request. But the difference between a casual question and a carefully crafted one is enormous.
For example, if you say "Hangzhou travel guide," AI gives you a generic, encyclopedia-style dump of information. But if you say "Plan a 3-day Hangzhou trip on a $300 budget, organized by day, including transportation and food recommendations," the response becomes far more specific and immediately actionable.
This methodology of communicating clearly is called Prompt Engineering — using structured expression and explicit constraints to turn vague instructions into precise directives that AI can accurately interpret.
Stage Two: Remembering You — Context, Memory, and RAG
Context: Implementing Short-Term Memory
Planning a trip can't be done in a single message — you'll add preferences across multiple exchanges. If AI can't remember what was said earlier, its responses become irrelevant.
In practice, every time you send a new message, the system bundles the entire conversation history and sends it along with your new question to the model. This bundled background information is called Context — essentially giving AI short-term memory.
But the context window is limited (ranging from a few thousand to tens of thousands of tokens). Once the limit is exceeded, critical information gets "pushed out," causing the model to forget initial premises — much like a memory overflow.
Memory: Compressing for Long-Term Recall
The solution is to have the model proactively compress and summarize conversation history — stripping away verbose details while preserving key logic and core facts. This distilled essential information is called Memory.
Think of it like writing meeting minutes after a business meeting: an hour-long discussion condensed into three to five key decisions. Memory essentially gives AI the ability to "take notes," keeping critical information accessible throughout extended conversations.
RAG: Breaking Through Private Data Barriers
When you say "Plan my trip based on the travel guides I've saved," a general-purpose LLM is stumped — it can only answer based on public data and knows nothing about your private materials.
RAG (Retrieval-Augmented Generation) works in four steps:
- Data Preprocessing: Your guides and notes are split into small chunks, converted into vector format, and stored in a private knowledge base
- Intelligent Retrieval: When you ask a question, the system converts it into a vector and matches it against the most relevant chunks in the knowledge base
- Context Augmentation: The retrieved chunks are combined with the original question to form an enhanced Prompt
- Precise Response Generation: The model generates an answer based on the augmented context, producing responses that match your intent while referencing your private materials
RAG lets AI truly "know you" — making it especially valuable for enterprise knowledge bases and personal assistant applications. But note: RAG only makes AI answer better. It still can only talk — it can't take action.
Stage Three: Taking Action — Function Calling, MCP, and Agent
Function Calling: Teaching the Model to "Fill Out Forms and Issue Commands"
When you say "Check tomorrow's second-class high-speed rail availability from Beijing to Shanghai," traditional AI just tells you "You can open the 12306 app" — that's an execution gap.
Function Calling works in five steps:
- User asks a question: Describing the need in natural language
- Model outputs a command: After analysis, it outputs a structured JSON command (which tool to call, with what parameters)
- External program executes: Backend code takes the command and actually calls the API
- Model formats the result: Converts raw data into natural language
- Returns to user: Displayed in the chat interface
Core value: The model is no longer a bookworm that only answers questions — it's an executor that can reach out to external systems to fetch data and get real work done.
MCP: The "USB Standard" for AI Tool Integration
Function Calling solves the problem of calling a single tool, but every new tool requires custom adapter code — interface specs and output formats vary wildly, and code can't be reused.
MCP (Model Context Protocol) unifies and standardizes third-party tool interfaces. An AI application only needs to connect to the MCP protocol once to access all tools that follow the standard — achieving "connect once, access everything."
Using a delivery analogy:
- Function Calling = How the courier fills out the shipping label (prescribed format)
- MCP = Standardized parcel lockers (standardized interface)
One governs "how the model speaks," the other governs "how tools listen." Together, they completely eliminate the integration gap.
Agent: From Passive Q&A to Proactive Execution
Even with tool calling, you still have to direct every step — check the train first, then tell it to find a hotel. It's exhausting. Wouldn't it be nice to just say "Handle my Hangzhou trip for me"?
That's what an Agent does. In its ideal state:
- Thinks independently: Breaks down tasks into steps and creates a plan
- Calls tools on its own: Uses Function Calling or MCP to connect to external services as needed
- Keeps its own records: Logs every step in real time and dynamically adjusts when problems arise
A standard LLM is a passive responder to questions. An Agent is a proactive executor — you give it a goal, and it delivers an end-to-end solution.
Stage Four: Following the Rules — Skill and Harness
Skill: A Reusable Library of Personalized Rules
Every time you assign AI a task, you have to repeatedly emphasize "organize by day, prefer high-speed rail, avoid tourist traps" — this repetitive communication is extremely inefficient.
Skill converts your personalized preferences and execution rules into programmatic capabilities that AI can reuse — like a rule handbook, written once and used forever.
To compare: A Prompt is a one-time instruction (a sticky note), while a Skill is a reusable capability library (a rule handbook). When an Agent runs, it activates the relevant Skills as needed, dramatically reducing context overhead.
Harness: Putting Reins on the Agent
The more capable an Agent becomes, the more damage it can cause — booking the wrong train, skipping human confirmation and paying directly, or even formatting a hard drive to free up space. The root cause is the lack of effective dynamic constraints.
Harness provides a behavioral constraint framework that does four things:
- Provides comprehensive context: Prevents misjudgments caused by insufficient information
- Defines behavioral boundaries: Such as "no payments without human confirmation"
- Automatically validates results: Determines whether the task met expectations
- Provides timely corrective feedback: Pulls things back on track the moment they deviate
Harness doesn't limit capability — it lets the Agent unleash productivity within a controlled scope. Safety is the lifeline of AI deployment.
Summary: A Complete Evolution Chain
Looking back at the entire chain, each concept didn't appear out of thin air — it emerged as a solution to a specific problem encountered at the previous stage:
| Problem | Solution |
|---|---|
| AI gives irrelevant answers | Prompt Engineering |
| Can't remember what was said earlier | Context + Memory |
| Doesn't know your private data | RAG |
| All talk, no action | Function Calling |
| Every tool needs custom integration | MCP |
| Still requires step-by-step direction | Agent |
| Doesn't follow your preferences | Skill |
| More capability means more risk | Harness |
From "chatting" to "reliably getting work done," AI has evolved through: understanding human language → maintaining conversations → referencing private data → calling tools → autonomous planning → following rules → safe and controllable operation. This is the complete path from a general-purpose conversational model to a professional intelligent assistant.
Related articles
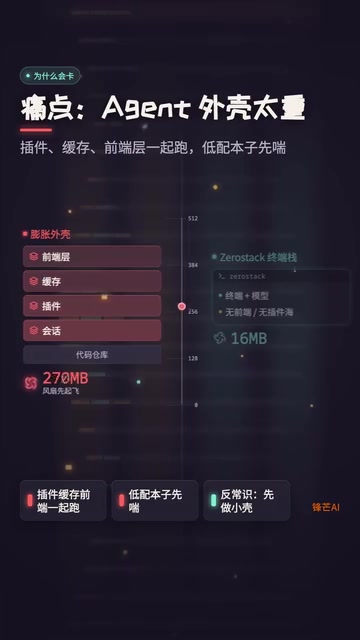
ZeroStack: An In-Depth Look at the Rust-Based Minimalist Coding Agent That Uses Only 16MB of RAM
In-depth review of ZeroStack, a Rust-based coding agent using only 16MB RAM. Analyzing its file I/O, multi-model support, permission controls, and ideal use cases.
ZCodeAI Free AI Agent Tool Review: Multi-Model Aggregation at Zero Cost
Detailed review of ZCodeAI, a desktop AI Agent tool by ZhiPu featuring free built-in models like DeepSeek V4 Flash and Xiaomi MiMo, with multi-model aggregation and no API Key required.
Claude Code Chinese Practical Handbook: A Complete Beginner's Guide for Users in China
A detailed look at the Claude Code Chinese handbook on Feishu, covering setup, domestic LLM integration, commands, and templates for users in China.