Six Major AI Events in One Day: OpenAI False Bans, Anthropic Pause Call, Grok Tops Arena
Six Major AI Events in One Day: OpenAI…
A whirlwind day in AI: OpenAI bugs, Anthropic pause calls, Grok's rise, and ChatGPT hitting 1 billion users.
Six major AI events unfolded in a single day: OpenAI's bug falsely banned Pro users sparking trust concerns, Anthropic called for pausing frontier model development citing recursive self-improvement risks, DeepSeek experienced quality degradation during its V3-to-V4 transition, Grok's E5 image model topped Chatbot Arena rankings, ChatGPT surpassed 1 billion monthly active users in record time, and WeChat began testing AI-powered payment features signaling the rise of AI Agents.
OpenAI Account Ban Fiasco: A Bug-Triggered Trust Crisis
Yesterday, a large number of ChatGPT Pro users suddenly found their accounts banned, and panic quickly spread through the community. Today, OpenAI officially confirmed that this was an internal bug, not a deliberate ban.
ChatGPT Pro is OpenAI's highest subscription tier, launched in late 2024 at $200/month, offering unlimited access to all models (including o1 pro mode), higher rate limits, and priority access to new features. For these power users, service interruptions don't just mean tool unavailability—they can directly impact business workflows and productivity. The weight of service stability commitments is far higher than for average consumers.
Affected users have begun getting their accounts restored, and OpenAI compensated them with an extra month of subscription. But the problems didn't end there: Codex also experienced anomalies simultaneously, apparently scrambling quota allocations for all subscription accounts. Codex is OpenAI's AI coding assistant service for developers, with a quota allocation system that distributes different computing resources and API call limits based on subscription tiers. The quota confusion indicates a failure in the backend user permission management system, typically involving database state inconsistencies or inter-microservice communication errors.
A question worth pondering: Once trust is damaged, can one free month of subscription really make up for it? For Pro users paying $200/month, service stability is the most fundamental promise. Consecutive system-level failures will inevitably cause some users to reassess their subscription decisions.
Anthropic Releases Major Statement: Calling for a Pause on Frontier Model Development
Anthropic released a major statement today calling on global AI companies to simultaneously pause frontier model development. Their core reasoning centers on concerns about "recursive self-improvement" posing uncontrollable risks—in simple terms, AI potentially starting to upgrade itself.
Recursive Self-Improvement is one of the core concepts in AI safety, referring to an AI system that can understand and modify its own code, architecture, or training process to produce a more powerful version, which can then further improve itself, creating a positive feedback loop of exponential capability growth. This concept was first described by I.J. Good in his 1965 "intelligence explosion" hypothesis. While current large language models haven't achieved full recursive self-improvement, they've already demonstrated abilities to write code and optimize algorithms, making the leap from "assisting humans in improving AI" to "autonomously improving AI" no longer far-fetched.
Community reactions were sharply polarized:
- Supporters view this as responsible behavior, arguing that AI safety issues genuinely require industry-wide coordination
- Skeptics see it as merely a competitive tactic, given that Anthropic itself is still aggressively iterating on Claude
This contradictory stance of "calling for a pause while accelerating development" significantly undermines the statement's credibility. But what's undeniable is that recursive self-improvement is indeed one of the most critical concerns in AI safety, deserving serious attention from the entire industry.
DeepSeek Quality Fluctuations Raise Community Concerns
Over the past two days, multiple developers have reported severe degradation in DeepSeek's instruction-following capabilities, with noticeably worse coding experiences. Tasks that previously completed smoothly now frequently produce errors.
DeepSeek is a large language model series developed by China's DeepSeek company. Its V3 version gained widespread attention in the global developer community thanks to its exceptional cost-performance ratio and open-source strategy. The transition from V3 to V4 involves architecture upgrades, training data updates, and inference optimization—capability fluctuations during this period are technically explainable, but for developers in production environments, any regression represents real business risk.
The community has two main interpretations:
- Optimists: This is normal fluctuation during the V3-to-V4 transition; brief regression during model switching is a common phenomenon
- Pessimists: This may signal instability in domestic models, exposing infrastructure-level issues
Meanwhile, the price war among DeepSeek's third-party API proxies continues, with the gap between V4 Pro proxy prices and official pricing growing ever wider. These "proxy services" are third-party API resellers that offer API calls below official pricing through bulk purchasing or technical means. This ecosystem is particularly prevalent in China's AI developer community but also brings concerns about uncontrollable service quality and data security risks. Price advantages matter, but if core capabilities fluctuate, developers' migration costs and trust costs will rise sharply.
Grok Releases Image Generation Model, Immediately Tops the Arena
xAI released the Grok E5 image generation model today, which immediately topped the arena rankings upon launch. The "arena" here refers to Chatbot Arena (operated by LMSYS), which uses an ELO-like blind comparison mechanism where real users vote on preferences without knowing model identities—currently one of the most credible model evaluation platforms in the industry. The image generation space was previously dominated by Midjourney, DALL-E 3, Stable Diffusion, and others; Grok E5's top ranking signifies a major breakthrough by xAI in visual generation quality.
This model supports synchronized audio-visual generation, with a significant leap in image quality. "Synchronized audio-visual generation" means the model can simultaneously understand and generate text, image, and even audio content—an important milestone in multimodal AI.
This signals that Musk's AI team is beginning to make serious moves in the multimodal space. Grok is no longer just the chatbot known for its "edgy" personality—it's demonstrating top-tier capabilities in image generation, one of the most competitive tracks. Considering xAI's computing resources (including its Memphis supercomputing cluster equipped with 100,000 H100 GPUs) and data advantages (massive multimodal data from the X platform), its subsequent performance in areas like video generation is equally worth watching.
ChatGPT Monthly Active Users Surpass 1 Billion: AI's iPhone Moment
ChatGPT's monthly active users have officially surpassed the 1 billion mark. In less than 4 years since its late 2022 launch, this growth rate means: 1 in every 8 people on Earth uses ChatGPT at least once a month.
For comparison, Facebook took about 8 years to reach 1 billion MAU (2004-2012), Instagram took about 10 years, and TikTok took about 5 years. ChatGPT breaking this milestone in under 4 years sets one of the fastest user growth records in internet product history.
OpenAI also revealed a staggering data point: their highest-usage internal user consumes approximately 100 billion tokens per month. Tokens are the basic units that large language models use to process text; 100 billion tokens equals roughly 75 billion English words, which translates to approximately 1 million standard-length novels. This means the heaviest user's monthly AI interaction volume is equivalent to generating a small library's worth of content. This level of usage intensity typically occurs in scenarios where AI is deeply integrated into automated workflows, such as large-scale code generation, data analysis, and content creation pipelines.
The 1 billion MAU milestone marks AI tools' official transition from the "novelty" phase to the "mass adoption" phase, with a penetration rate that even exceeds smartphones in their early days.
WeChat Tests AI Payments: The Ultimate Form of Digital Assistants
WeChat is internally testing an AI payment feature that allows users to complete payment operations directly through an AI assistant. This means in the future, you'll only need to tell the AI "help me make a payment," and it can actually execute the transaction.
AI transforming from a chat tool into a true digital assistant—WeChat is moving fast with this play. The core concept here is AI Agent—an AI system capable of autonomously perceiving its environment, making decisions, and executing actions, fundamentally different from traditional Q&A chatbots. Payment is the "litmus test" for Agent capabilities because it involves irreversible real-world operations.
But the accompanying security and privacy concerns cannot be ignored:
- How to prevent accidental payment triggers?
- What if the AI is induced to execute malicious payments? (i.e., "prompt injection attacks"—where malicious third parties craft special inputs to induce AI to perform unauthorized operations)
- Where are the boundaries of payment authorization? (such as setting security boundaries like amount thresholds and payee whitelists)
WeChat's advantage lies in its massive payment ecosystem and user base—WeChat Pay processes over 1 billion daily transactions, covering the vast majority of online and offline payment scenarios in China. If the AI payment feature matures and launches successfully, it will significantly accelerate AI Agent adoption in the Chinese market and potentially redefine how people interact with digital services.
Summary
Today's AI world was both eventful and surreal: OpenAI demonstrated infrastructure fragility through a bug, Anthropic exposed the industry's contradictory mindset through a statement, DeepSeek's fluctuations reminded us that model stability remains a challenge, while Grok's rise, ChatGPT's 1 billion MAU, and WeChat's AI payments collectively paint a picture of AI accelerating its penetration into daily life. AI competition has moved from "who's smarter" into a new phase of "who's more stable and who's more practical."
Related articles
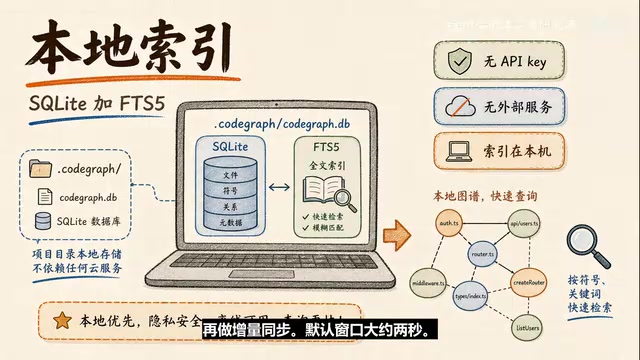
CodeGraph: Give Your Coding Agent a Code Map, Save 47% Tokens
CodeGraph is an open-source project with ~40K GitHub stars that uses Tree-sitter to build a local queryable code map, helping Claude Code and Cursor reduce 47% token usage and 58% tool calls.
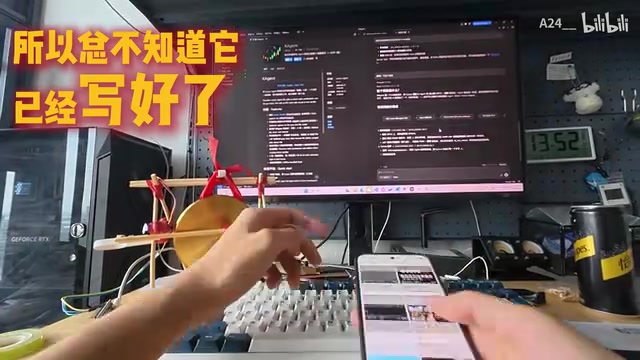
AI Finishes Writing Code, Automatically Strikes a Gong to Alert You: Open-Source Physical Feedback Tool DAgent
A developer built a physical feedback device with chopsticks and a small gong that auto-strikes when AI finishes coding. Now open-sourced as DAgent, it also simulates IPO bell-ringing when creating new files.

Level Up Claude Code: Building an Enhanced Plan Mode with Grill Me
Learn how to install and use the Grill Me Skill for Claude Code, replacing AI guesswork with structured questioning to clarify requirements before generating execution plans.