Step 3.7 Flash: Deep Dive into the 198B Sparse MoE Multimodal Model
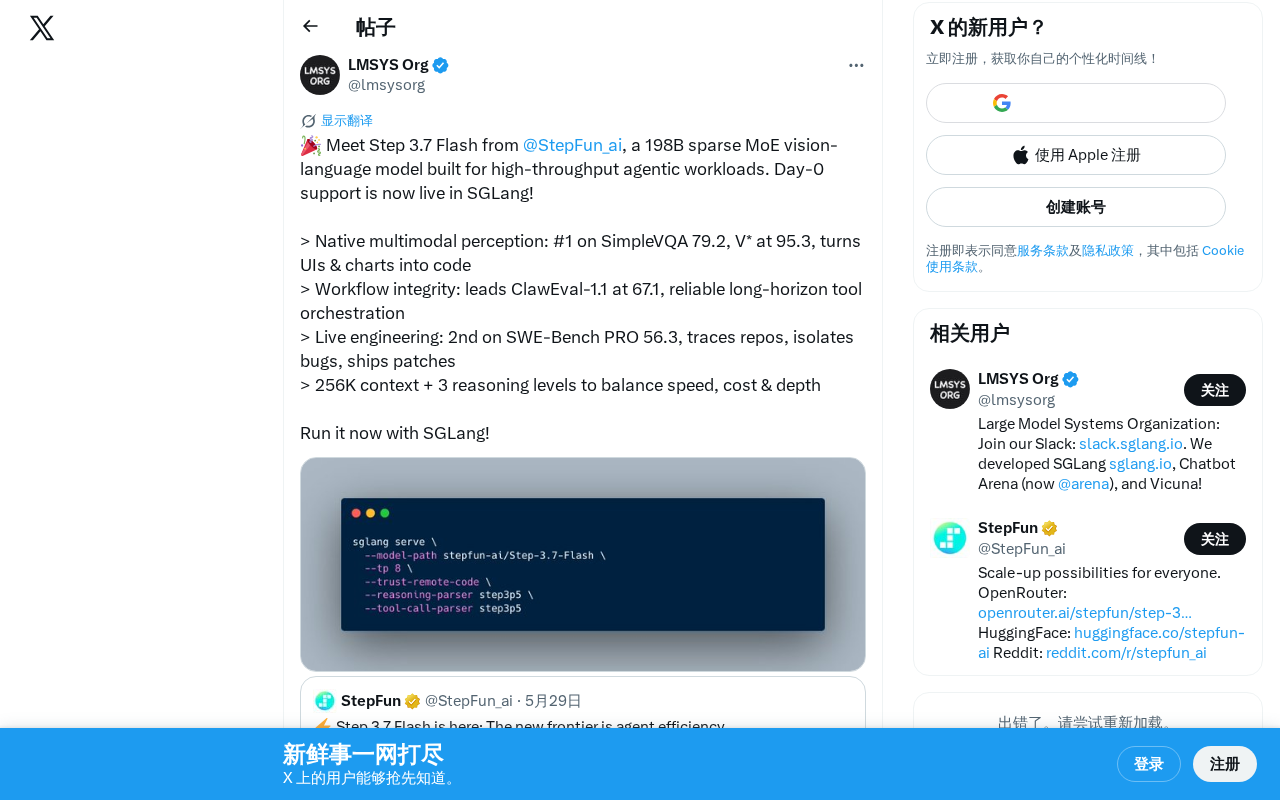
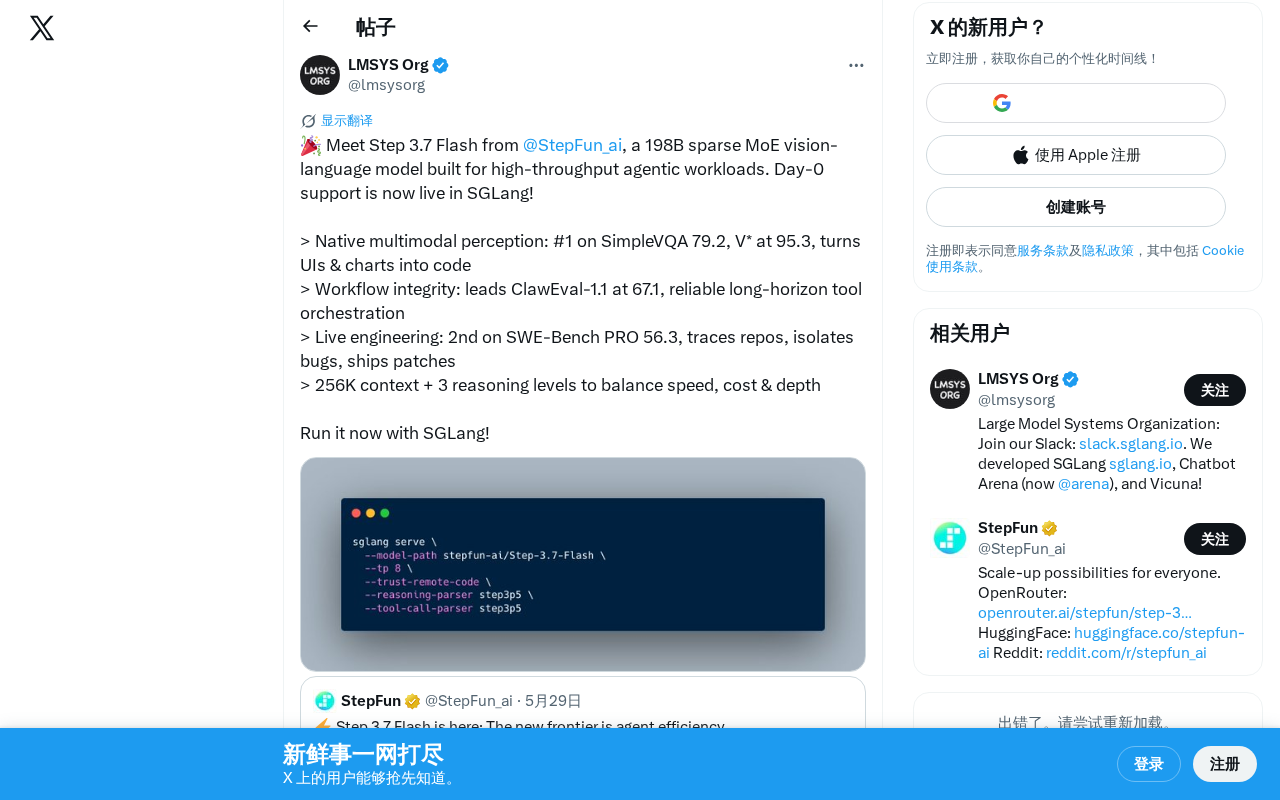
StepFun AI releases Step 3.7 Flash, a 198B sparse MoE vision-language model designed for Agent workloads.
StepFun AI releases Step 3.7 Flash, a 198B-parameter sparse MoE vision-language model designed for high-throughput Agent workloads. The model achieves top-tier performance across multimodal understanding (SimpleVQA #1, V* 95.3), tool orchestration (ClawEval-1.1 leader), and software engineering (SWE-Bench PRO #2), while supporting 256K context window and three-level reasoning. It has received day-one support from the SGLang framework.
Overview
StepFun AI has officially released Step 3.7 Flash, a 198B-parameter Sparse Mixture of Experts (Sparse MoE) vision-language model designed specifically for high-throughput agentic workloads. The model has received day-one support on the SGLang framework, allowing developers to deploy it immediately.
Core Capabilities Breakdown
Native Multimodal Perception
Step 3.7 Flash excels in multimodal understanding. It claimed first place on the SimpleVQA benchmark with a score of 79.2 and achieved an impressive 95.3 on the V* test.
About these two benchmarks: SimpleVQA is a standardized test suite in the Visual Question Answering domain that evaluates a model's precise understanding of image content across multiple dimensions including object recognition, scene understanding, and spatial relationship inference. The V* benchmark focuses on visual grounding and fine-grained perception, testing a model's ability to perform precise identification in complex visual scenes—placing extremely high demands on the quality of the underlying visual encoder. Achieving top-tier performance on both tests simultaneously means Step 3.7 Flash possesses comprehensive visual perception capabilities ranging from macro-level scene understanding to micro-level detail recognition.
This means the model can accurately understand image content and directly convert UI interfaces and charts into code—a critical capability for automation workflows and agent applications. The ability to transform visual information directly into executable code gives Step 3.7 Flash a clear advantage in scenarios such as front-end development assistance and reverse engineering of data visualizations.
Workflow Completeness and Tool Orchestration
In complex workflow execution, Step 3.7 Flash leads with a score of 67.1 on the ClawEval-1.1 benchmark, demonstrating reliable long-horizon tool orchestration capabilities.
ClawEval's evaluation logic: ClawEval is a tool-calling evaluation framework designed specifically for AI Agents, simulating real-world multi-step task execution scenarios with a focus on model reliability and error recovery during tool chain orchestration. Unlike simple single-call tool tests, ClawEval requires models to make consistently correct decisions in dynamically changing task environments—including when to call which tool, how to handle anomalous results returned by tools, and how to coordinate resources across multiple parallel subtasks. This metric measures a model's execution reliability in multi-step, multi-tool-call scenarios, making it a core consideration for building production-grade AI Agents.
Long-horizon tool orchestration means the model can maintain contextual consistency throughout complex tasks, invoke different tools in the correct sequence, and perform reasonable error handling when exceptions occur. This is also one of the most challenging capabilities in the current AI Agent landscape.
Real-Time Software Engineering Capabilities
On the SWE-Bench PRO benchmark, Step 3.7 Flash ranked second with a score of 56.3, demonstrating solid practical engineering capabilities.
SWE-Bench PRO's industry standing: SWE-Bench PRO is one of the most authoritative evaluation benchmarks in software engineering, built on real GitHub Issues and open-source code repositories. It requires models to complete the end-to-end bug localization and fix pipeline—from understanding problem descriptions and retrieving relevant code files to generating repair patches that pass unit tests. Unlike synthetic datasets, every task in SWE-Bench PRO comes from real software development scenarios, and it is regarded by the industry as the gold standard for measuring the practical engineering capabilities of AI coding assistants. A score of 56.3 means the model can independently resolve more than half of real-world software defects, which represents top-tier performance at the current state of the art.
It can track repository structures, locate bugs, and generate fix patches, making it an extremely competitive AI coding assistant in the software development domain.
Architecture Design Highlights
Efficiency Advantages of Sparse MoE Architecture
The 198B total parameter count employs a sparse mixture of experts architecture, where only a subset of experts are activated during inference, dramatically reducing computational costs while maintaining model capacity.
Technical principles of Sparse MoE: The Sparse Mixture of Experts architecture originated from a groundbreaking 2017 paper by Google Brain. Its core idea is to partition the model into multiple independent "expert" sub-networks and use a lightweight Gating Network to dynamically determine which experts should be activated for each input token. During inference, typically only Top-K experts (e.g., Top-2) are activated, making the actual computation far less than what the total parameter count would suggest—for a model with 198B total parameters, the actual activated parameter count may be only on the order of 20-40B. This architecture has been extensively validated by top models including Mistral's Mixtral series, Google's Gemini 1.5, and DeepSeek-V2, establishing it as the mainstream technical approach for large language models to balance capability with efficiency.
This design is particularly well-suited for high-throughput scenarios, enabling more concurrent requests to be served with limited computational resources. Compared to dense models of equivalent parameter scale, the sparse MoE architecture offers significant advantages in inference latency and memory footprint—this is also the origin of the "Flash" in Step 3.7 Flash's name, reflecting the pursuit of a balance between speed and efficiency.
256K Context Window and Three-Level Reasoning
Step 3.7 Flash supports an ultra-long 256K context window, capable of processing large-scale documents and complete codebases.
Technical significance of ultra-long context: The attention mechanism in traditional Transformer architectures has O(n²) computational complexity, causing memory consumption to explode as sequence length increases, which limited early models' context windows to 4K-8K tokens. To break through this bottleneck, the industry has developed several key technologies including RoPE positional encoding extrapolation, sliding window attention, and FlashAttention. A 256K context window (approximately equivalent to 200,000 Chinese characters or 500,000 English words) means the model can process an entire medium-sized codebase, hundreds of pages of technical documentation, or hours-long conversation histories in a single pass—this is decisive for software engineering tasks requiring holistic code understanding and Agent application scenarios requiring persistent memory.
More noteworthy is its three-level reasoning (3 reasoning levels) design, which allows users to flexibly trade off between speed, cost, and reasoning depth based on task complexity. This tiered reasoning mechanism is highly practical in real deployments: simple queries use lightweight reasoning for the fastest response, while complex tasks engage deep reasoning to ensure accuracy. For teams that need to control inference costs, this feature provides fine-grained resource management capabilities.
Deployment and Ecosystem Support
SGLang, as a high-performance LLM inference framework, has provided day-one native support for Step 3.7 Flash.
Technical advantages of the SGLang framework: SGLang (Structured Generation Language) is a high-performance LLM inference framework developed by a research team at UC Berkeley, optimized specifically for structured generation and complex reasoning tasks. Compared to mainstream inference frameworks like vLLM, SGLang introduces RadixAttention technology, which significantly improves throughput in multi-turn dialogue and Agent scenarios through a KV cache prefix-sharing mechanism—achieving 2-5x inference speed improvements in certain benchmarks. SGLang also natively supports function calling, JSON structured output, and multimodal input, making it particularly suitable for building production-grade AI Agent systems. Day-one support means model release and framework adaptation were completed simultaneously, allowing developers to use it in production environments without waiting for community adaptation.
Developers can deploy and call the model directly through SGLang, benefiting from its optimized inference performance and flexible scheduling capabilities. For teams already using SGLang, integration costs are minimal.
Competitive Landscape Analysis
The release of Step 3.7 Flash further intensifies competition in the large model space. Achieving top-tier performance simultaneously across multimodal understanding, code generation, and Agent tool calling makes it a strong competitor to models like GPT-4o and Claude Sonnet.
Competitive context in the AI Agent track: AI Agent workloads represent the core paradigm for current large model application deployment, referring to AI systems capable of autonomous planning, external tool invocation, and completing multi-step complex tasks. Unlike traditional single-turn Q&A, Agent workloads have three distinctive characteristics: intensive tool calling, strong long-range dependencies, and high concurrency demands—placing requirements on model inference speed, tool-calling accuracy, and long-context processing capabilities far exceeding those of ordinary conversational scenarios. Currently, leading players including OpenAI, Anthropic, and Google are all continuously investing in Agent capabilities, and this segment has become the core battlefield for large model commercialization. Step 3.7 Flash's architecture optimization specifically targeting Agent workloads positions it to establish differentiated competitive advantages in this high-value scenario.
For developers who need to build complex AI Agent systems, Step 3.7 Flash offers a unified solution combining multimodal understanding, long-context processing, and reliable tool calling—well worth close attention and evaluation.
Key Takeaways
- Step 3.7 Flash is a 198B-parameter sparse MoE vision-language model designed for high-throughput Agent workloads
- Achieves top-tier performance on multimodal benchmarks including SimpleVQA (79.2, first place) and V* (95.3)
- Leads on ClawEval-1.1 with 67.1, demonstrating reliable long-horizon tool orchestration capabilities
- Ranks second on SWE-Bench PRO (56.3), with capabilities to track codebases, locate bugs, and generate patches
- Supports 256K context window and three-level reasoning mechanism for flexible balance of speed, cost, and reasoning depth
- Has received day-one native support from the SGLang framework, offering out-of-the-box production deployment capabilities
Related articles
 Tech Frontiers
Tech FrontiersGitHub Agent HQ Launch: AI Coding Tools Enter the Era of Platform Competition
GitHub Universe unveils Agent HQ platform for unified coding agent management, Copilot upgrades with multi-model support. OpenAI completes restructuring, Anthropic tests new model, NVIDIA open-sources AI models.
 Tech Frontiers
Tech FrontiersGemini 3.5 Flash Achieves a Massive Leap on the GDPval Benchmark
Google Gemini 3.5 Flash surpasses Gemini 3.1 Pro on the GDPval benchmark. The lightweight Flash model leverages post-training techniques to approach frontier-level performance, redefining the balance between quality and cost.
 Tech Frontiers
Tech FrontiersGoogle Gemini Antigravity Weekly Quota Tripled — AI Coding Without Limits
Google Gemini triples Antigravity weekly quotas following a prior daily quota boost. Analyzing the impact on developers and its strategic significance in AI coding.