#SGLang
14 related articles
 Product Reviews
Product Reviews·3 min
Manus Hands-On Review: How Does This AI Agent Perform on the DeepSeek Tech Stack?
Hands-on review of Manus AI Agent on the DeepSeek tech stack, analyzing task execution, Chinese reasoning capabilities, strengths, limitations, and the potential of domestic LLMs in Agent applications.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
DeepSeek-V3.2 Released: Coding and Math Capabilities Join the Global Top Tier
DeepSeek-V3.2 released with coding, math, and Agent capabilities matching Gemini 3.0 Pro, setting new open-source SOTA. Detailed analysis of performance gains, use cases, and deployment tips.
Read more →
 Tutorials
Tutorials·3 min
llama.cpp MTP Acceleration Deployment Guide: Configuration Steps & Real-World Benchmarks
Guide to enabling MTP multi-Token prediction acceleration in llama.cpp, covering CUDA setup, desktop configuration, model selection, and benchmarks showing ~60 Token/s with Qwen3 27B.
Read more →
 Research
Research·2 min
Agent Loops in Practice: Transforming Token Output into Productivity from CUDA Kernels to Automated Research
Deep dive into how the Humanize framework transforms LLM tokens into engineering productivity via Agent Loops. Covers KDA winning CUDA kernel contests, virtual hardware optimization, and 50% research cost reduction.
Read more →
 Tutorials
Tutorials·2 min
Tutorial: Deploying a PD-Disaggregated SGLang Multi-Node Inference Cluster on AMD GPUs
Learn how to deploy a PD-disaggregated SGLang inference cluster on AMD GPUs using a single config file, boosting LLM throughput and latency performance.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
SGLang v0.5.12.post1 Released: DeepSeek V4 Stability Fixes and Blackwell Adaptation
SGLang v0.5.12.post1 stability patch details: 12 critical fixes covering DeepSeek V4 garbled text and crashes, NIXL PD disaggregated inference logic, Blackwell B300 adaptation, and cold start optimization.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
Step 3.7 Flash: Deep Dive into the 198B Sparse MoE Multimodal Model
Deep dive into StepFun AI's Step 3.7 Flash, a 198B sparse MoE vision-language model with 256K context and 3-level reasoning, excelling in multimodal understanding, AI coding, and Agent tool orchestration.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
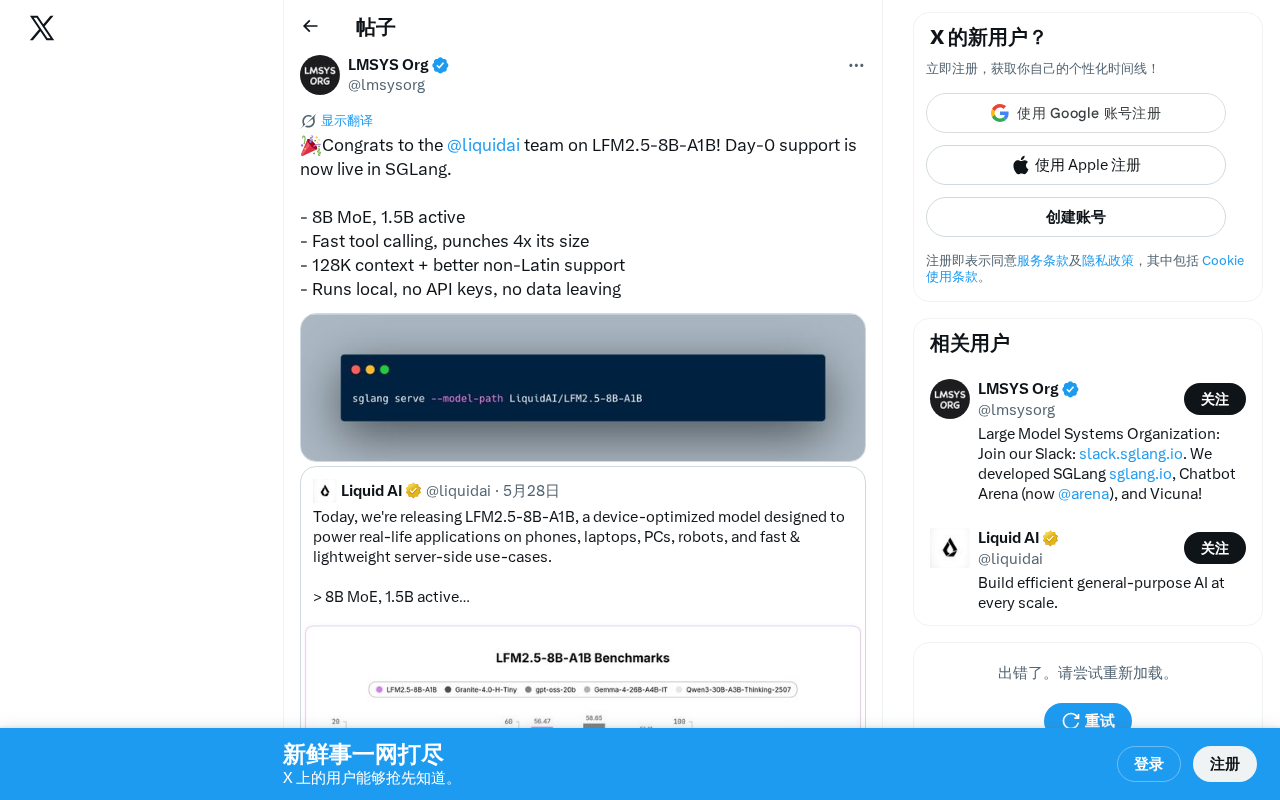
LFM2.5-8B-A1B: A MoE Model with 1.5B Active Parameters Delivering 4x Its Weight Class Performance
Liquid AI releases LFM2.5-8B-A1B, a MoE model with 8B total params but only 1.5B active, matching 6B-class models in tool calling. Supports 128K context, local deployment, multilingual, with SGLang Day-0 support.
Read more →
 Industry Insights
Industry Insights·2 min
SGLang Enters Finance: How AI Inference Infrastructure Is Reshaping Wall Street
SGLang co-hosts a finance AI inference event with Crusoe AI and Cloudflare, exploring LLM inference deployment in trading, risk management, and compliance — signaling Wall Street's shift to production-grade AI infrastructure.
Read more →
 Industry Insights
Industry Insights·2 min
AMD MI355X Beats B200: Full-Stack Optimization Breakdown for 5% Lower TCO on DeepSeek-R1 Inference
AMD Instinct MI355X achieves 5% lower TCO than NVIDIA B200 on DeepSeek-R1 disaggregated inference via SGLang+MoRI full-stack optimization with 1.25x per-GPU throughput.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
Cloudflare Contributes Critical KV Cache and Mooncake Fixes to SGLang
Cloudflare contributes decode KV cache offload and Mooncake recovery fixes to SGLang, resolving garbled output under high concurrency for Kimi K2.6 and enabling automatic fault recovery in distributed inference.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
SGLang Hosts Agent Loops Office Hour, Focusing on Agentic Loop Architecture Optimization
SGLang team hosts an Agent Loops Office Hour exploring inference optimization for agentic loops, covering KV Cache reuse, low-latency multi-turn dialogue, and tool calling techniques.
Read more →
Industry Insights
Deep Dive into Three Major LLM Career …
·3 min
Deep Dive into Three Major LLM Career Paths: Requirements, Tech Stacks, and Career Prospects
Deep analysis of three core LLM roles—Application Engineer, Development Engineer, and Algorithm Engineer—covering technical requirements, salary thresholds, and career prospects including RAG, fine-tuning, and inference deployment.
Read more →
Tutorials
Decoding LLM Naming Conventions: Param…
·3 min
Decoding LLM Naming Conventions: Parameter Counts, Quantization Formats & VRAM Requirements Quick Reference
Decode LLM naming conventions, understand 32B parameters & AWQ/GGUF quantization formats, with 4-bit VRAM estimation formulas, MOE model pitfalls, and model selection by GPU tier.
Read more →