Stop Writing Prompts by Hand: Let AI Agents Prompt Themselves

Stop hand-writing prompts — design self-prompting loop systems that let AI agents prompt themselves.
AI coding is shifting from manually crafting prompts to designing self-prompting loop systems where agents review their own code, proactively fetch context, and self-correct. This paradigm shift — from prompt engineer to agent system designer — enables scalable, high-quality AI programming by leveraging feedback loops, quality gates, and emergent capabilities that far exceed what single hand-written prompts can achieve.
From Manual Prompting to Automated Loops: A Paradigm Shift in AI Programming
Here's a reminder worth repeating every month: You shouldn't be manually writing prompts for your coding agents anymore — you should be designing loop systems that let agents prompt themselves.
This insight comes from a developer's deep reflection on AI coding workflows shared on YouTube. He admits that despite being exposed to various agent loop concepts early on, truly embracing this philosophy was a long journey. And as it turns out, the person who was ahead of the curve (Pete, as he mentions) was right once again.

The Problem with Traditional Agent Loops: Cool but Impractical
Early agent loops like the Ralph Loop did help developers understand how AI agents could accomplish more tasks over time. The core idea behind agent loops originates from cybernetic feedback loops — systems that feed their output back as part of the input, enabling self-regulation. In AI programming, early agent loops attempted to have large language models automatically execute generated code, detect errors, and fix them, forming a closed loop of "plan → execute → observe → correct." This shares similarities with the REPL (Read-Eval-Print Loop) in traditional software engineering, but with LLM reasoning capabilities added, giving the loop much stronger adaptability.
However, these loops also brought a serious side effect — error rates skyrocketed.
The modifications agents made within loops looked impressive but weren't actually productive. The root cause was that early loops lacked effective quality control mechanisms. An agent might introduce two new bugs while fixing one, creating a vicious cycle of "fix and break." Eventually, many people found themselves falling back to the old approach: manually writing carefully crafted prompts, guiding agents step by step through tasks. This is a shared experience among AI programming practitioners — after trying every new tool and method, they retreat to the comfort zone of hand-crafted prompts.

The Turning Point: Letting Agents Prompt Themselves
The real breakthrough came after systematically building self-prompting loops. Here are several key practices:
Agent Self-Review: Building a Generate-Review Closed Loop
Instead of relying on manual review of agent-generated code, set up an automated system where the agent reviews its own code, provides feedback, makes adjustments, and then triggers another review. This forms a complete closed loop:
Generate → Review → Feedback → Correct → Re-review
This mechanism allows code quality to continuously improve with each iteration without requiring human involvement in every detail. Importantly, the "review" here isn't just simple syntax checking — it includes multi-dimensional evaluation such as logical consistency verification, code style compliance checks, and potential security vulnerability scanning. The agent in its reviewer role is given different system prompts and evaluation criteria than in its generator role. This "role separation" strategy effectively prevents self-confirmation bias — just as in software engineering, the code author shouldn't be the sole code reviewer.
Using a Hermes Agent to Proactively Fetch Context
This represents a fundamental shift in thinking. Previously, developers had to find relevant context information themselves and feed it to the agent. Now, a Hermes agent proactively brings context to you rather than you going out to find it.
The Hermes agent, named after the Greek messenger god, serves as an information intermediary — proactively retrieving, filtering, and integrating the context information needed before an agent executes a task. This addresses a fundamental limitation of large language models: the finite context window. Even though the latest models support context lengths of hundreds of thousands of tokens, developers still face the challenge of deciding what information to include. The Hermes agent's approach is like an evolved version of RAG (Retrieval-Augmented Generation) architecture — it doesn't just retrieve documents but can understand the current codebase's structure, dependency relationships, historical change records, and even architectural decision documents, then automatically inject the most relevant information into the working context of subsequent agents.
This means agents aren't just executors — they're also collectors and organizers of information. They can understand what background knowledge the current task requires and autonomously acquire and integrate that information.
Accepting a Disruptive Conclusion
This ultimately leads to a paradigm-shifting conclusion: Most of your agent runs probably shouldn't use prompts you wrote by hand.

In other words, the human role should shift from "issuing instructions one by one" to "designing the operating mechanism."
Why Self-Prompting Loops Matter So Much
The core logic behind this idea is actually quite clear:
-
Human prompts have inherent bottlenecks: When writing prompts, we're limited by our own depth of understanding of the problem and our grasp of the context. Agents, during execution, often discover issues and details we couldn't have anticipated. This is like a classic insight in software project management: at the start of a project, the team's understanding of requirements is always at its shallowest, deepening only as development progresses. Self-prompting loops allow agents to continuously deepen their understanding of the task during execution, rather than being locked into the human's initial — and potentially incomplete — cognitive framework.
-
Loops produce emergent capabilities: When agents can review their own output, identify problems, and self-correct, the system's capability ceiling far exceeds what a single manual prompt can achieve. Emergent capabilities are a core concept in complex systems theory, referring to abilities the system as a whole exhibits that individual components don't possess. In self-prompting loops, emergence manifests as: an agent reviewing its own code might discover potential edge case issues that were never mentioned in the original human prompt. This is similar to "rubber duck debugging" in software engineering — the process of explaining code itself can expose problems. The difference is that AI agents can not only find problems but immediately generate fixes and verify their correctness, all within seconds.
-
The key to scaling: Manually writing every prompt doesn't scale. Once you've designed the loop mechanism, agents can continue working at high quality with minimal human intervention — this is the truly scalable approach to AI programming. From an economics perspective, the marginal cost of manual prompting is nearly constant — each new task requires roughly the same human time and effort. The marginal cost of self-prompting loops, however, decreases as the system matures, because once the loop mechanism is well-designed, it can be reused across a large number of similar tasks.
Practical Implications: From Prompt Engineer to Agent System Designer
The implications of this trend for AI programming practitioners are profound. The developer's role is shifting from "prompt engineer" to "agent system designer."
Prompt engineering quickly became a prominent discipline after ChatGPT's release in 2022, evolving from zero-shot prompting and few-shot prompting to Chain-of-Thought and Tree-of-Thought techniques. However, these methods are fundamentally still "single-turn optimization" — attempting to maximize output quality in a single interaction. Agent system design is a fundamentally different approach, borrowing from distributed systems and microservices architecture: decomposing complex tasks into multiple collaborating agents, each with clear responsibility boundaries, coordinated through message passing and state management. This is why frameworks like LangGraph, CrewAI, and AutoGen are emerging in the industry — they provide exactly the infrastructure needed to build these loop systems.
The core work is no longer about writing the perfect prompt, but rather:
- Designing effective feedback loops — enabling agents to self-check and self-correct, forming a closed loop of continuous improvement. This requires clearly defining evaluation criteria for each iteration: what counts as "pass," what needs to be "redone," and how to quantify improvements in code quality.
- Building context acquisition mechanisms — enabling agents to proactively understand task context rather than passively waiting for humans to feed them information. This involves codebase indexing, document parsing, API specification extraction, and other engineering work — essentially building a structured "project memory" for agents.
- Establishing quality gates — setting reasonable checkpoints and exit conditions within the loop to prevent infinite loops. This includes setting maximum iteration counts, defining convergence conditions (e.g., two consecutive reviews with no new issues), and automatically escalating to human intervention when the agent is detected to be "going in circles."
- Managing error propagation — using layered verification mechanisms to avoid the error rate spikes seen in early loops. Specific strategies include: running automated test suites after each modification, using diff comparisons to ensure changes remain within a controlled scope, and introducing an independent "arbitration agent" to make final judgments when the generating agent and reviewing agent disagree.
This methodology has already been used to deliver substantial amounts of code in real projects, with rich practical experience accumulated. This isn't theoretical speculation — it's a proven path to productivity improvement.
Conclusion
From manual prompting to automated loops, AI programming is undergoing a quiet paradigm shift. Developers who still spend significant time meticulously crafting individual prompts may need to reassess their workflow.
The essence of this shift is consistent with multiple paradigm leaps throughout software engineering history: from assembly language to high-level languages, from manual memory management to garbage collection, from imperative programming to declarative programming — the core of every advancement has been abstracting away low-level repetitive labor so humans can focus on higher-level system design. Self-prompting loops are the latest manifestation of this trend in the AI programming era: we no longer need to manually orchestrate every step — instead, we design the rules and mechanisms and let the system run on its own.
The future belongs to those who can design efficient agent loop systems — letting AI not only execute your instructions but think for itself about what to do next. Rather than becoming a better prompt writer, become a better system designer.
Related articles
What Is Cursor? A Complete Guide to the AI-Native Programming IDE's Core Features and Use Cases
An in-depth look at Cursor, the AI-native programming IDE, covering intelligent code generation, multi-model support, context awareness, and how it compares to traditional IDEs across six key dimensions.
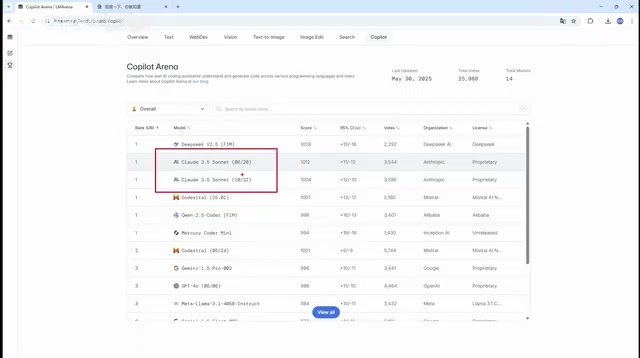
Cursor Composer 2.5: The Secret Behind an Open-Source Model's Reinforcement Training to a Top-3 Coding Benchmark Ranking
Cursor built Composer 2.5 on Kimi K2 open-source model, ranking 3rd on coding benchmarks and surpassing K2.6. Deep dive into Cursor's data flywheel, product architecture, and pricing.

Behind SpaceX's Acquisition of Cursor: Musk's True $60 Billion Ambition
SpaceX acquires Cursor parent Anysphere in a $60B all-stock deal. Musk's real play: an AI-driven software production line and invaluable real workflow data.