The Complete AI Agent Engineering Tech Stack: A Practical Guide to 100x Development Efficiency
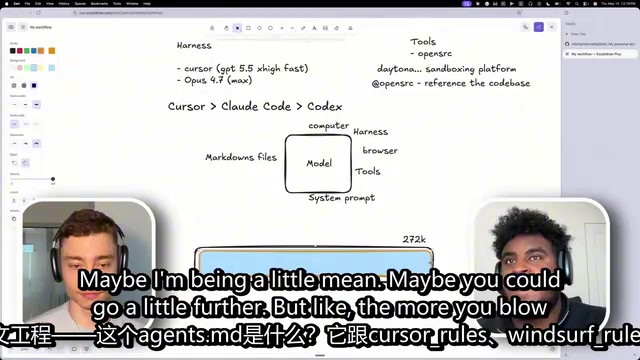
A complete guide to the AI agent engineering stack for achieving 100x development efficiency.
This article breaks down the full AI agent engineering workflow shared by a developer whose code is 95% AI-generated. Covering model selection (GPT 5.5, OPUS 4.7, Gemini 3), the Cursor framework, context engineering tools, Agents MD onboarding files, automated CI review loops with Hermes and GrapLoop, service layer architecture, and tech stack choices — it provides a replicable blueprint for dramatically accelerating software development with AI agents.
From Chat Boxes to Agent Frameworks: A Paradigm Shift
Developers who ship 100x faster aren't typing prompts into chat boxes — they're running multiple agent frameworks in parallel. This is the core insight shared by Mickey, a senior developer whose code is 95% AI-generated, on the David Andre podcast.
As he puts it: "Models aren't perfect yet, but they've reached a stage where they deliver massive productivity gains. Especially when you understand your vertical — a little brainpower plus AI can take you very far."
This workflow doesn't rely on proprietary tools and is entirely replicable. The key lies in understanding the relationship between models, frameworks, and context engineering, and building effective feedback loops.
Frameworks and Models: Understanding the Foundation of AI Development
Models Don't Think — Frameworks Give Them Capabilities
A common misconception is equating the model with AI's full capabilities. In reality, a model is just a "next-token predictor" — you feed it English, it converts it to tokens, maps them onto a graph to predict the next token, then converts it back to English. The model itself can't do anything on its own.
It's worth understanding the nature of tokens here. Tokens are the fundamental units that large language models use to process text. Models don't directly understand human language — they split input text into tokens, which might be a complete word, a subword fragment, or even a single character. For example, "understanding" might be split into "under" and "standing" as two tokens. During training, models learn statistical relationships between tokens from massive text corpora. During inference, they predict the most likely next token based on the existing token sequence. This autoregressive mechanism means models are essentially extremely complex conditional probability calculators, not true "thinkers." Understanding this is crucial for using AI correctly — output quality is highly dependent on the quality and structure of the input.
The framework is what matters. A framework is the wrapper around the model, containing API tools, specific system prompts, Agents MD files, and more. These components guide the model to execute or focus on specific tasks. When you see "read this file" or "searched for this thing" in Cursor or any agent, those are tool-calling capabilities granted by the framework.
Tool Use (also known as Function Calling) is one of the core capabilities of modern AI agent architecture. Traditional LLMs can only generate text, but through the framework layer's tool-calling mechanism, models can "decide" to invoke external tools during inference — such as reading files, executing searches, calling APIs, or running code. Technically, the framework defines available tools' names, parameter formats, and functional descriptions in the system prompt. When the model determines it needs external information during response generation, it outputs a structured tool-call request. The framework captures this request, executes the corresponding operation, and injects the result back into the context for the model to continue reasoning. This "reason-act-observe" loop (the ReAct pattern) is the critical leap from simple chatbots to intelligent agents.
Model Selection Strategy
Mickey's model choices are very deliberate:
- GPT 5.5 Extra High: Primary model, especially strong at understanding large, complex codebases
- OPUS 4.7 Max version: Specifically for UI and frontend modifications
- Gemini 3: Long-context, high-volume, large codebase scenarios
He emphasizes: "If someone asks me whether they can use free models — no. You have to use the best models. The difference is night and day."
Why Cursor Is the Best Agent Framework
Benchmark data shows that Cursor outperforms Cloud Code and Codex in model performance. While Cursor doesn't subsidize users like some competitors, it allows flexible switching between models, and its new agent view is excellent.
Context Engineering: The Decisive Factor in Agent Performance
Context engineering is the core element that determines whether an AI agent performs well or poorly. When agents underperform, the issue is usually not insufficient model capability — it's insufficient context.
Open Source Tools: Giving Agents Complete Code Context
Open Source (a repository tool developed by Verso) fetches the source code of whatever packages or libraries you're using and dumps it into your codebase. This gives the agent complete context when executing tasks.
Key techniques:
- Place downloaded source code in a folder like
/open_source - Use
.gitignoreto exclude these files from your repository - Add an instruction file telling the agent: "When in doubt, reference the code in the open_source folder"
Repo Prompt: Building Context from GitHub Links
Repo Prompt takes GitHub links and helps you build structured prompts. It quickly transforms the code structure of open-source projects into context information that agents can understand.
Yak: Codebase Knowledge Graphs
Yak chunks your codebase into a knowledge graph, scanning the entire codebase's tree structure and providing file set summaries and key dependency relationships, helping the model make better decisions.
Core Principles of Context Engineering
Keep context highly relevant — only include what's needed. Many people think more context is better, but in practice, too much context is just noise. Give the model a brief description; you don't need to describe every variable. Good frameworks perform multiple searches on queries, rank and re-rank results — essentially a mini RAG pipeline.
RAG (Retrieval-Augmented Generation) is a technical architecture that combines external knowledge bases with large language models. A standard RAG pipeline works as follows: first, documents are chunked and converted into vectors via embedding models, stored in a vector database. When a user submits a query, the system converts the query into a vector as well, using similarity search to find the most relevant document chunks. Finally, these chunks are injected as context into the model's prompt, allowing the model to generate answers based on retrieved information. The "multiple searches, ranking, and re-ranking" mentioned here are typical features of advanced RAG pipelines — using multi-path retrieval and cross-encoder re-ranking to improve retrieval precision, ensuring the context injected into the model is highly relevant rather than redundant noise.
Agents MD: Onboarding Your Agent
Agents MD is a file placed in the root directory of your codebase that the agent reads every time it opens a new conversation. Mickey includes:
- Key design patterns
- Languages used
- File structure and where to find things
- Architectural decisions
"It's like onboarding a new junior developer — you're onboarding the agent."
He recommends splitting by topic: one for backend patterns, one for frontend, one for specific package dependencies. This makes maintenance easier, and the agent learns from them far more effectively.
Automated Review Loops: Building a Quality Assurance Feedback Loop
CI Agent Hermes
Mickey uses Hermes as a CI agent, automatically triggering reviews via GitHub Actions when a PR is created. Hermes doesn't merge PRs, but it sets labels and performs initial reviews — essentially a PR review assistant that doesn't require a human.
CI (Continuous Integration) is a core practice in software engineering where developers frequently merge code changes into the main branch, with each merge verified through automated builds and tests. GitHub Actions is GitHub's CI/CD automation platform, allowing developers to define workflows that execute automatically on specific events (such as creating a PR or pushing code). Traditional PR (Pull Request) reviews require team members to manually read code changes, check for logic errors and style issues — often a bottleneck in the development process. Introducing AI agents into the CI pipeline means every code submission receives instant automated review feedback, dramatically shortening the cycle from submission to merge while maintaining consistent code quality.
He's pushing Hermes to go beyond PR reviews — also checking whether tests need updating, whether there are broken references, security issues, and more.
GrapLoop: Automated Fix Cycles
GrapTile provides a confidence score for code reviews (on a 5-point scale). GrapLoop works as follows:
- The agent reads the PR and review feedback
- Fixes the issues
- Waits for new review results
- If it hasn't reached 5/5, continues fixing
- Only stops when it hits a perfect score
"I've had sessions lasting 20-30 minutes where the agent in Cursor tells me I made a mistake, GrapTile catches it, fixes it, pushes to GitHub, and automatically stops when the new review hits 5/5."
Code Structuring: Service Layers and Continuous Refactoring
Why Structure Matters
A common problem with agents is that they won't reuse existing functions — they'll write a new one instead. This causes the codebase to grow endlessly, with too many moving parts, making it difficult for even the agent itself to debug.
The solution is a service layer — creating functions that can be reused repeatedly. The Service Layer is a classic design pattern in software architecture, originating from Domain-Driven Design (DDD) principles. It establishes a clear boundary layer between business logic and the presentation layer, encapsulating reusable business operations as independent service functions. For example, operations like "create user," "send notification," and "process payment" are each encapsulated in corresponding service modules, and any part of the system that needs that functionality calls the same function rather than reimplementing it. This pattern is especially important for AI agent development because current LLMs tend to "solve problems in place" when generating code — reimplementing functionality in the current context rather than searching for and reusing existing implementations. A service layer reduces the probability of agents producing duplicate code by providing a clear function directory.
Workflow:
- Build features with GPT 5.5 + Cursor
- Test locally until passing
- Run structuring passes to find duplicate code and refactor
"When code structure is cleaner, agents find it easier to continue working in new sessions. If a human finds it hard, the agent probably does too."
The Logic Behind Tech Stack Choices
-
Svelte over React for frontend: Svelte stays close to core HTML and TypeScript principles, which agents handle better. React is currently the most widely used UI framework in frontend development, using a virtual DOM and JSX syntax to build user interfaces through a declarative component model. Svelte takes a fundamentally different compile-time approach — it compiles components into efficient native JavaScript during the build phase, eliminating the need for virtual DOM diffing at runtime. Svelte's syntax is closer to native HTML, CSS, and JavaScript, with intuitive component file structures and state management triggered by simple variable assignment. This "what you see is what you get" quality makes it easier for AI agents to understand and generate Svelte code, since models don't need to handle React's hooks rules, closure pitfalls, useEffect dependency arrays, and other error-prone abstractions. For AI-assisted development, a framework's cognitive complexity directly impacts agent code generation quality.
-
Convex for backend: Everything is code, giving agents complete backend context without needing to screenshot dashboards. Convex is a full-stack backend platform whose core design philosophy is "everything as code." Unlike traditional backend services, Convex expresses database schema definitions, server functions, permission rules, and scheduled tasks entirely in TypeScript code rather than managing them through web consoles or configuration files. This means agents can fully understand the backend's data models, API endpoints, and business logic by reading code files, without relying on screenshots or documentation. Convex also provides real-time data synchronization, ACID transactions, and automatic caching. This "code as infrastructure" philosophy aligns perfectly with how AI agents work — agents excel at processing structured code text, not parsing unstructured documents or GUI screenshots.
-
Code is the best context: Documentation is the worst context source
Investment and Mindset: The Hidden Barriers of Agent Engineering
Financial Investment Is Necessary
Mickey is blunt: "This is going to be a money game. We're being subsidized right now, but one day the subsidies will end." A $200/month subscription may seem expensive, but he used AI to review a contract and secured triple the originally offered compensation. He used Cloud Code to complete accounting work in two hours that would have otherwise cost five or six thousand dollars.
Hackathon Mentality
Every engineer should participate in hackathons because they:
- Force you to deliver within 48 hours
- Train your prioritization skills
- Build AI usage intuition on low-risk projects
Shipping Beats Perfection
"Competitors will move fast, burn more tokens, and their app might not be as good as yours — but they'll win." San Francisco founders have an almost delusional belief — ship when the product barely works, build hype, raise funding, then iterate. Overthinking a simple feature without shipping is the biggest trap.
Security Awareness: A Required Course in the Agent Era
While heavily leveraging AI agents, security cannot be overlooked:
- Two-factor authentication is a must — never use SMS verification
- Tell agents not to install packages published less than 14 days ago
- Set up a family code word to guard against AI voice-cloning scams
- Use a password manager and distribute keys to trusted family members
- When you discover a security vulnerability, paste the information into an agent and have it analyze whether you've been exposed
The Complete Agent Engineering Formula
Stringing all these elements together gives you a complete AI agent engineering workflow:
- Cursor as the framework + the best models (GPT 5.5 / OPUS 4.7)
- Open Source to download package/library source code for complete agent context
- Structure after every feature to keep code clean
- Run GrapLoop after creating PRs for automated fixes until perfect score
- Give agents just enough tools and context to let them work in loops
The essence of agent engineering isn't letting agents think for you — it's giving them sufficient information, guardrails, and feedback loops. Human approval and human thinking remain critically important. As Mickey says: "Caring matters, being thoughtful matters, taking time matters."
Key Takeaways
Related articles
The Decline of Tokenmaxxing: Why Selling Outcomes Matters More Than Selling Tokens
The Tokenmaxxing craze is fading as enterprise AI procurement shifts from chasing Token counts to focusing on actual business outcomes. Learn why outcome-based AI evaluation is the right approach.
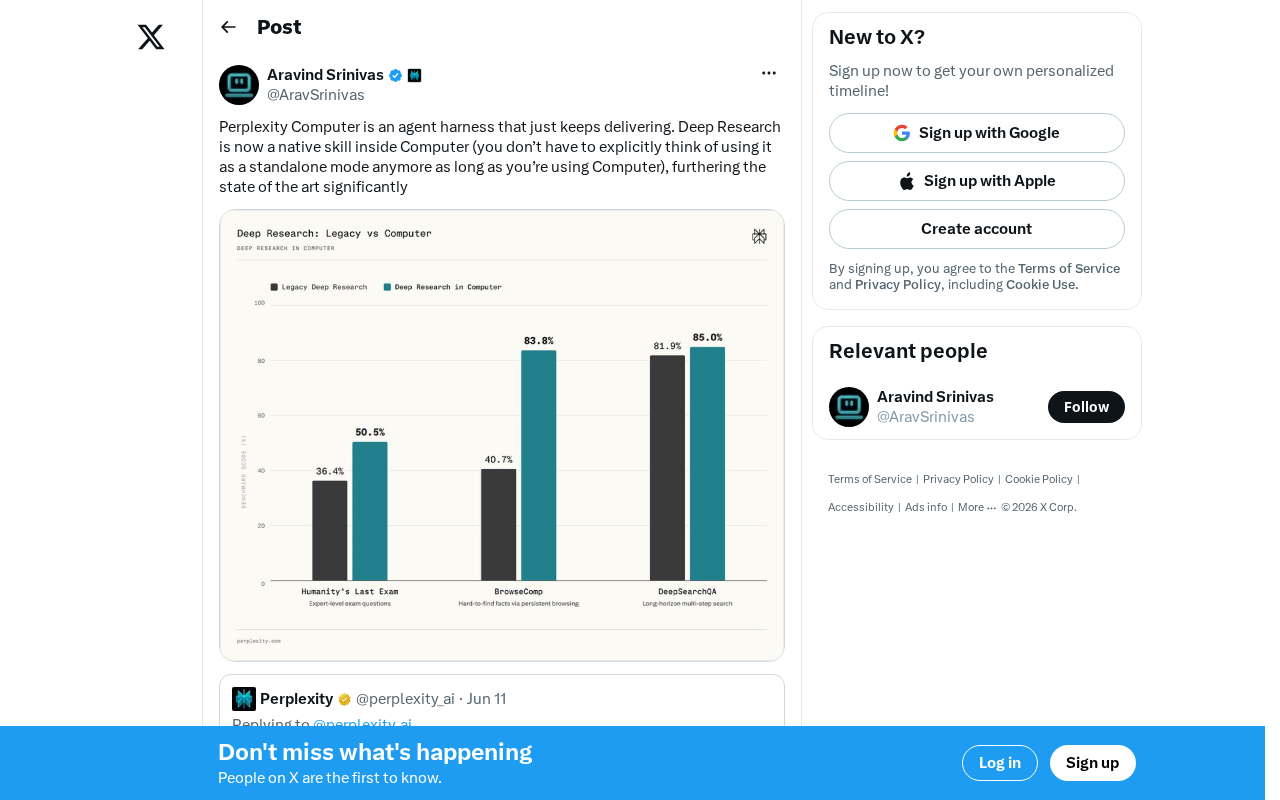
Perplexity Computer Integrates Deep Research as a Native Skill: A New Paradigm for AI Agent Capability Fusion
Perplexity integrates Deep Research as a native skill in Computer, enabling automatic invocation without manual mode switching. Analyzing the Agent Harness design philosophy and AI capability fusion trends.

Key Takeaways from Andrew Ng × OpenAI's Prompt Engineering Course: Two Core Principles Explained
Deep dive into Andrew Ng & OpenAI's ChatGPT Prompt Engineering course: Base LLM vs instruction-tuned models, two core prompting principles, and API-first development thinking for developers.