The "Magic Fatigue" Effect in AI Products: The Hidden Challenge of User Expectation Management
Why users feel AI is getting dumber — and how teams can manage the ever-rising expectation baseline.
This article explores the "Magic Fatigue" effect in AI products — the phenomenon where users rapidly adapt to AI capabilities and perceive stagnation or regression even as models improve. It examines the cognitive biases behind user feedback, the challenge of distinguishing real performance degradation from expectation escalation, and strategies AI teams can employ including gradual capability release, transparent communication, and systematic evaluation frameworks.
When Users Get Used to Magic
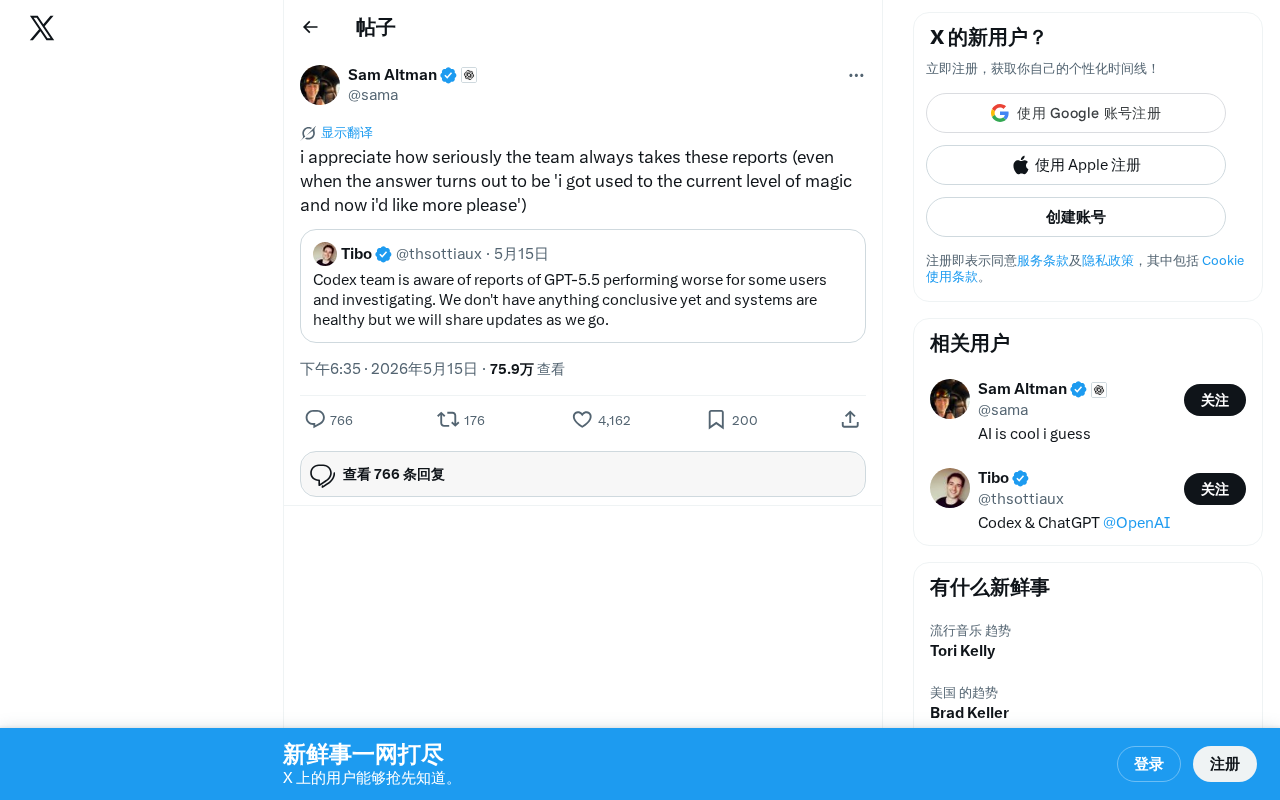
A tweet from an AI practitioner struck a chord across the industry: "I appreciate that the team always takes these feedback reports seriously (even when the ultimate answer is 'I've gotten used to the current level of magic and now I want more')."
This seemingly offhand remark actually reveals a severely underestimated problem in AI product development — Magic Fatigue. When users first experience AI's powerful capabilities, they feel amazed. But that amazement fades rapidly, replaced by higher expectations and growing "dissatisfaction."
What Is "Magic Fatigue" in AI Products?
The Rapid Escalation of the Expectation Ladder
Humans adapt to technology far faster than the technology itself evolves. Think back to late 2022 when ChatGPT first launched — users were stunned that it could write a decent email. Now, if AI can't understand complex context, remember details across multiple conversation turns, and offer personalized suggestions, users feel like "it's gotten dumber."
This isn't because AI has actually regressed — it's because users' baselines keep shifting upward. The psychological concept of "Hedonic Adaptation" manifests particularly strongly in AI product experiences — yesterday's surprise becomes today's baseline, and today's baseline becomes tomorrow's shortcoming.
The concept of hedonic adaptation was first proposed by psychologists Brickman and Campbell in 1971, describing how human emotional responses to positive or negative life changes tend to return to baseline levels over time. In the technology product domain, this effect forms an interesting parallel with the Kano Model proposed by Japanese scholar Noriaki Kano — the Kano Model categorizes product features into basic (must-have), performance (the more the better), and excitement (unexpected delight) types, where excitement features inevitably degrade over time into performance or even basic features. AI products are especially susceptible to triggering this effect because their capability boundaries are inherently fuzzy — unlike traditional software with clear feature lists, users struggle to establish stable psychological anchoring points for AI expectations, causing expectation drift to occur far faster than with other technology products.
Cognitive Biases in Feedback Reports
When users submit feedback saying "the model has gotten worse," teams face a tricky judgment call: is this genuine performance regression, or the natural escalation of user expectations? The team attitude mentioned in the tweet — taking every report seriously — exemplifies responsible product development. Because within these mixed feedback reports, real technical issues may indeed be hiding.
Multiple cognitive biases compound here: confirmation bias makes users more likely to notice cases where AI "fails" while overlooking successes; recency effect causes one recent bad experience to overwrite memories of dozens of previous good interactions; and negativity bias means one disappointing response carries far more emotional weight than ten satisfactory ones. These psychological mechanisms work together to create significant gaps between users' subjective perceptions and models' objective performance.
Why Magic Fatigue Is an Enormous Challenge for AI Teams
Distinguishing Real Degradation from Perceived Degradation
In AI model updates and iterations, "capability trade-offs" genuinely exist. Improving one aspect (such as safety) may require compromises in another (such as creativity). Teams need to establish systematic evaluation benchmarks rather than relying solely on users' subjective feelings to judge model quality.
This capability trade-off is technically known as the "Alignment Tax." When models enhance safety and helpfulness through alignment methods like RLHF (Reinforcement Learning from Human Feedback) or Constitutional AI, they may exhibit more conservative tendencies in creative writing, humor generation, or edge case handling. Additionally, deployment optimizations like model distillation and weight quantization — performed to reduce inference costs and latency — can also cause subtle capability losses. OpenAI, Anthropic, Google, and others have all faced massive user feedback claiming "the model got dumber," with post-hoc analysis showing that some cases were indeed related to model updates or system prompt adjustments, but a significant proportion was attributable to perceptual bias.
To systematically distinguish between these two scenarios, the industry has developed multi-layered evaluation systems. Beyond standardized academic benchmarks (such as MMLU for knowledge breadth, HumanEval for coding ability, GSM8K for mathematical reasoning, etc.), leading teams also maintain internal "gold standard" test sets — carefully designed collections of test cases covering various real user scenarios, rigorously compared before and after each model update. The ELO scoring system used by LMSYS's Chatbot Arena tracks relative changes in model capability through large-scale anonymous human preference voting. These tools, combined with longitudinal user satisfaction tracking data, form a complete evidence chain for determining whether a model has truly degraded.
However, completely ignoring user sentiment is also dangerous. Even if objective metrics show the model is improving, if users feel the experience has "gotten worse," that itself is a product problem that needs solving. Product quality is ultimately defined by user perception, not by benchmark scores — this is a cognition that AI product teams must internalize.
The Art of User Communication
How do you tell users "actually the model hasn't gotten worse, your expectations have gotten higher" without making them feel dismissed? This requires extremely sophisticated communication skills. The best approach is: acknowledge the validity of their feelings, demonstrate progress with data, and clearly communicate future improvement directions.
This communication strategy is supported by mature methodologies from the customer success management field. First is the "Validate-Explain-Commit" framework: validate the reasonableness of user feelings ("We understand your experience didn't meet expectations"), explain the technical context ("We optimized aspect X, which may have affected performance in scenario Y"), and finally give a clear commitment ("We are conducting targeted optimization for these types of scenarios"). Anthropic frequently employs similar strategies in their product update logs, candidly discussing model capability changes and trade-offs — this transparency actually earns trust from the user community.
Implications of Magic Fatigue for the AI Industry
The Pressure of Continuous Innovation
The magic fatigue effect means AI companies must maintain an extremely high pace of innovation. Not because products are actually regressing, but because user expectations are growing at an exponential rate. This explains why major AI companies release at such a dense cadence — stagnation equals regression.
From a business competition perspective, this dynamic creates a "Red Queen Effect" — derived from the Red Queen's famous line in Through the Looking-Glass: "Here, you must run as fast as you can just to stay in place." OpenAI's iteration cycles from GPT-3.5 to GPT-4 to GPT-4o have continuously shortened, Anthropic's Claude version update frequency has also accelerated, and Google's Gemini series follows suit. This arms race-style pace not only consumes enormous computational resources and R&D investment but also poses severe challenges to team sustainability. The industry is exploring whether a more sustainable innovation cadence exists, rather than being held hostage by the infinite escalation of user expectations.
Expectation Management as a Core Product Strategy
Smart AI product teams incorporate expectation management into their product strategy:
- Gradual capability release: Rather than showcasing all capabilities at once, roll out new features at a measured pace
- Transparent capability boundaries: Clearly inform users of current model limitations
- User education: Help users understand how AI works and establish reasonable expectations
The gradual capability release strategy draws from "Flow Theory" in game design (proposed by psychologist Csikszentmihalyi) and the "Peak-End Rule" from behavioral economics. Flow theory emphasizes that the dynamic balance between challenge and ability produces optimal experiences, while the Peak-End Rule shows that people's memories of experiences are primarily determined by peak moments and ending moments. Apple has long employed a similar strategy — even when technology is ready, features are rolled out in phases to maintain user freshness and media attention. In the AI domain, after GPT-4's release, OpenAI gradually opened up the plugin system, code interpreter, DALL-E integration, multimodal input, and other capabilities; Anthropic's Claude also adopted a phased release strategy for Artifacts, Computer Use, MCP protocol, and other features. These are all essentially careful management of users' magic fatigue curves, ensuring each new capability release reactivates users' sense of wonder.
Conclusion
The value of this tweet lies in how it gently and humorously highlights the most human challenge in AI product development: technology is advancing, but human satisfaction is a forever-moving target. Truly excellent AI teams must pursue technical breakthroughs while understanding the human need behind "wanting more magic" — and treat every voice with respect and seriousness.
From a broader perspective, the magic fatigue effect is actually a microcosm of human civilization's progress. It is precisely because we are never satisfied with the current "level of magic" that technology continues to evolve. The mission of AI teams is not to eliminate this dissatisfaction, but to transform it into fuel for product improvement — while ensuring the team itself doesn't burn out in this endless pursuit of ever-rising expectations.
Related articles
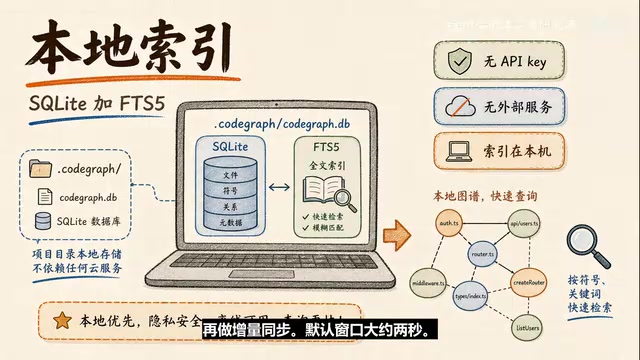
CodeGraph: Give Your Coding Agent a Code Map, Save 47% Tokens
CodeGraph is an open-source project with ~40K GitHub stars that uses Tree-sitter to build a local queryable code map, helping Claude Code and Cursor reduce 47% token usage and 58% tool calls.
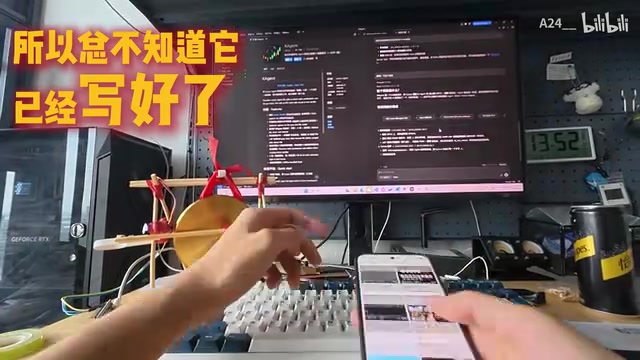
AI Finishes Writing Code, Automatically Strikes a Gong to Alert You: Open-Source Physical Feedback Tool DAgent
A developer built a physical feedback device with chopsticks and a small gong that auto-strikes when AI finishes coding. Now open-sourced as DAgent, it also simulates IPO bell-ringing when creating new files.

Level Up Claude Code: Building an Enhanced Plan Mode with Grill Me
Learn how to install and use the Grill Me Skill for Claude Code, replacing AI guesswork with structured questioning to clarify requirements before generating execution plans.