The "Worse is Better" Philosophy of Large Model Design: Why Simple and Brutal Beats Refined and Complex
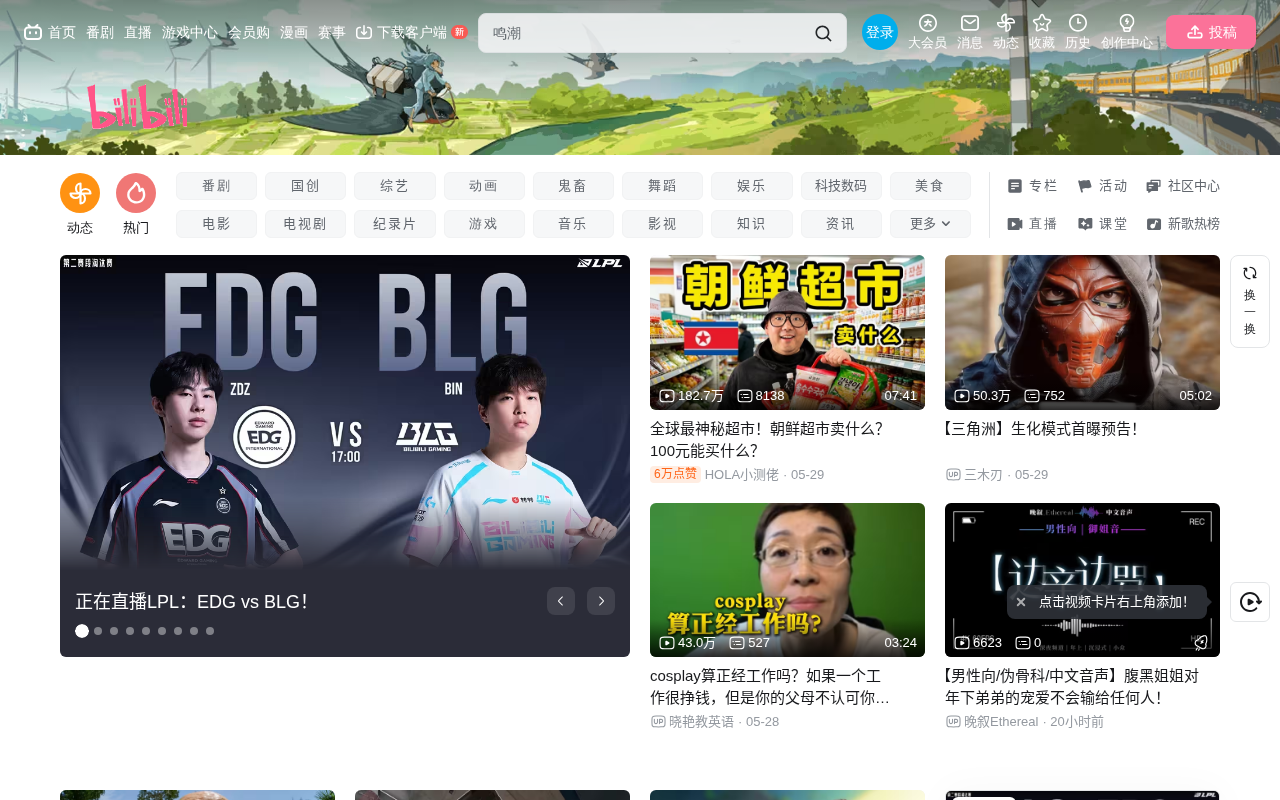
DeepSeek V4 dropped N-gram because in large model architecture, training speed trumps theoretical elegance.
DeepSeek V4's abandonment of N-gram technology embodies the "worse is better" rule in the large model community: simple, runnable, and fast matters more than refined complexity. The article proposes three iron laws — architecture must align with GPU hardware to maximize MFU, rapid iteration matters more than theoretical correctness (powered by Scaling Laws), and unified architecture is more efficient than assembled components. Transformer dominates AI not because it's theoretically optimal, but because matrix multiplication perfectly matches GPUs, making it the fastest to train.
Why Did DeepSeek V4 Abandon N-gram? A Counterintuitive Choice
Many people noticed that DeepSeek V4 chose not to use N-gram technology despite having it available, taking a seemingly "clumsy" path instead. Behind this lies an unspoken rule in the large model community — worse is better.
N-gram is a classic statistical method in natural language processing. Its core idea is to model local dependencies in language using sequences of N consecutive words (or tokens). For example, bigrams (N=2) focus on the co-occurrence probability of two adjacent words, while trigrams (N=3) consider combinations of three words. In modern large models, N-gram techniques are often used in scenarios like Speculative Decoding to accelerate inference — a lightweight N-gram model quickly predicts candidate tokens, which are then verified by the main model, reducing the latency of autoregressive generation. DeepSeek previously explored Multi-token Prediction (MTP) combined with N-gram in V3/R1, but V4 ultimately abandoned this approach. The reasoning behind this decision is exactly what this article discusses.
This doesn't mean the technology is actually bad. Rather, in the world of large models, compared to refined and complex designs, simple, runnable, and fast is the core pursuit. Once you understand this logic, you can make sense of virtually all mainstream large model architecture choices today.
Two Schools of Thought in Large Model Architecture Design
Teams building large models can roughly be divided into two schools:
- The Academic School: Pursues elegant plating, where every design choice must have theoretical backing, striving for optimal parameter efficiency
- The Beast School: Pursues getting food out of the kitchen fast, with simple unified structures that fully utilize hardware compute

There was once a PhD who built a very elaborate model, claiming it could achieve the same results with only one-tenth of the parameters others used. But when asked how much of an A100 GPU's power this model could actually harness, the answer was — about 5%.
This involves a key metric: MFU (Model FLOPs Utilization), which measures the ratio of actual compute consumed during model training to the GPU's theoretical peak compute capacity. Take the NVIDIA A100 as an example — it has 6,912 CUDA cores and 432 Tensor Cores, with a theoretical peak of 312 TFLOPS (BF16). Top industry teams typically optimize MFU to 50%-65%, while poorly designed models might only achieve single digits. For a training cluster with thousands of GPUs, improving MFU from 5% to 60% means a 12x speedup with the same hardware investment, or reducing a one-year training cycle to one month. Given that GPU rental costs for large model training easily reach tens or even hundreds of millions of dollars, MFU differences directly determine a project's economic viability.
It's like having a top-tier industrial wok but only daring to put in a tiny bit of ingredients each time, cooking painfully slowly. The Beast School's approach is to use 65% of the GPU's compute power, digesting several terabytes of data per day. The Academic School's elegance becomes a fatal flaw in the face of "running fast" — if you can't feed data in fast enough, no amount of perfect design matters.
Three Iron Laws of "Worse is Better"
Iron Law #1: Simple Doesn't Mean Crude — It Means Alignment with GPU Hardware
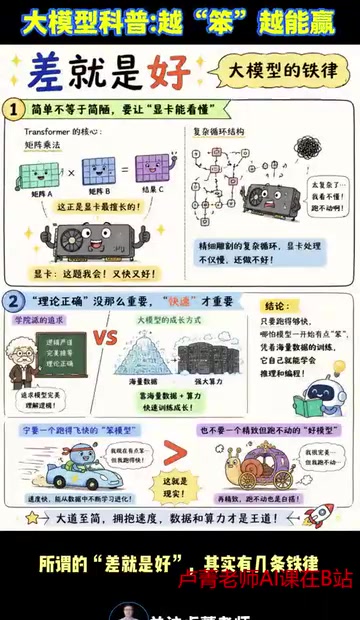
The core computation of Transformer is matrix multiplication, which happens to be exactly what GPUs excel at. The reason GPUs became the core hardware for deep learning lies in their massively parallel computing architecture. Take the A100's Tensor Cores as an example — they can complete a 4×4 matrix multiply-accumulate operation in a single clock cycle. The self-attention mechanism and feed-forward networks in Transformers are essentially large-scale matrix multiplications (GEMM), which perfectly match GPU hardware characteristics. In contrast, structures with complex conditional branches, recursive dependencies, or irregular memory access patterns (like the step-by-step recurrence in traditional RNNs) cause massive GPU core idling, with actual utilization potentially dropping to single-digit percentages.
If you design an intricately carved complex recurrent structure, GPUs not only process it slowly but also poorly. Good architecture design is essentially about alignment with hardware. It's not about theoretical elegance — it's about making every GPU run at full capacity.
Iron Law #2: Theoretical Correctness Matters Less Than Rapid Iteration
The Academic School pursues models that perfectly understand logic, but large models grow through massive data and compute. The theoretical foundation for this view is the Scaling Law. Research published by OpenAI in 2020 showed that large language model performance (measured by cross-entropy loss) follows a power-law relationship with model parameter count, training data volume, and training compute — and this relationship remains stable across multiple orders of magnitude. This means that as long as you can continuously increase compute and data, model performance will improve predictably. Under this framework, the "elegance" of model architecture contributes far less to final performance than scaling up training.
As long as it runs fast enough, even if the model starts out a bit "dumb," with massive data training, it will learn to reason on its own. Therefore, a "simple" architecture that can digest more data at higher throughput will ultimately surpass a slow-training but theoretically more elegant complex architecture, powered by Scaling Laws.
Better to have a blazing-fast "dumb" model than an elegant model that can't run. This is the practical logic of large model training.
Iron Law #3: Unified Architecture is More Efficient Than Assembled Components

Don't always think about piecing together various advanced small structures. That's like assembling a car from parts of different brands — looks like all premium components, but they're fundamentally incompatible.
The Beast School insists on unified standards, with all computation following the same logic — like mass-produced cars that are simple to assemble and run fast and stable. And the Beast School is pragmatic: covering 80% of scenarios is enough. The remaining 20% will naturally be solved when hardware upgrades and more compute become available.
DeepSeek V4's architecture choices embody this philosophy. Its core innovations include continued optimization of the MoE (Mixture of Experts) architecture and deep engineering tuning of the training pipeline. The MoE architecture sets up multiple "expert" sub-networks at each layer, activating only a subset during each inference pass, thereby dramatically expanding model parameter count without significantly increasing computation. V4's abandonment of N-gram and other auxiliary modules is precisely to maintain the purity of the MoE backbone architecture and the efficiency of the training pipeline — any additional branch structure could break the carefully optimized computation graph, leading to increased communication overhead and pipeline bubbles, ultimately dragging down overall training speed.
The Essence: Large Models' Absolute Worship of Training Efficiency
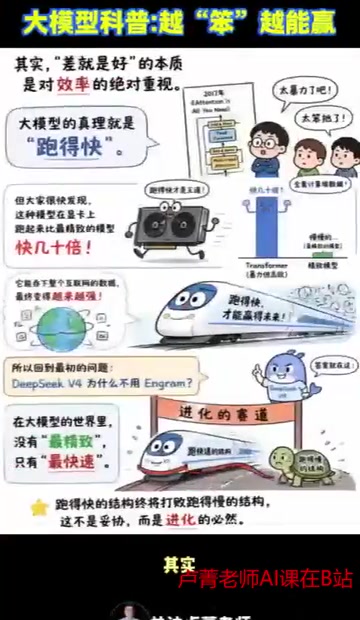
The essence of "worse is better" is an absolute emphasis on efficiency. The creed of large models is running fast.
Looking back at the epoch-making 2017 paper Attention Is All You Need, many people thought it was too brute-force and too clumsy when it was first published — relying entirely on computation to process data. Before this, the mainstream approach for sequence modeling was recurrent neural networks like LSTM and GRU. While they could theoretically capture long-range dependencies, their serial dependency between time steps prevented them from fully utilizing GPU parallel computing capabilities. Transformer replaced recurrent structures with the Self-Attention mechanism, allowing computation at all positions in a sequence to happen simultaneously. Although self-attention has O(n²) computational complexity, seemingly "brute-force," because its operations are essentially matrix multiplications, its actual throughput on GPUs far exceeds theoretically more "efficient" recurrent structures.
But the facts proved that Transformer runs dozens of times faster on GPUs than the most refined models. It can swallow the entire internet's data and ultimately becomes increasingly powerful. This architecture later gave birth to a series of milestone models including GPT, BERT, and LLaMA, becoming the foundational backbone of virtually all large language models today.
This is why Transformer dominates the entire AI field — not because it's theoretically the most elegant, but because it's the fastest.
Conclusion: The Fastest Architecture Will Ultimately Win
Returning to the original question: Why doesn't DeepSeek V4 use N-gram?
The answer is clear: Although N-gram is clever, as long as it drags down training speed, it doesn't comply with the survival rule of "running fast." In the world of large models, there is no "most refined" — only "fastest." The fastest structure will ultimately beat the slower structure — this isn't a compromise, but an evolutionary inevitability.
For students learning AI, this insight is crucial: don't be obsessed with the flashy tricks in papers. Focus on which designs can actually run at scale in large-scale training. Engineering capability and systems thinking often determine a model's success or failure more than theoretical innovation.
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.