#training efficiency
11 related articles
Trae + Claude Code + DeepSeek: A Low-C…
·2 min
Trae + Claude Code + DeepSeek: A Low-Cost AI Programming Combo Explained
A detailed guide to the Trae, Claude Code, and DeepSeek AI programming combo — just 20 RMB/week in API costs. Covers setup steps, practical tips, and layered collaboration strategies.
Read more →
AI Large Language Model Learning Roadm…
·4 min
AI Large Language Model Learning Roadmap: A Complete Guide from Zero to Project Implementation
A systematic AI LLM learning roadmap covering prompt engineering, RAG, AI Agent development, and fine-tuning — with beginner-friendly paths and practical tips.
Read more →
AI Agent Development Learning Roadmap:…
·4 min
AI Agent Development Learning Roadmap: A Complete Four-Stage Plan from Zero to Production
A systematic AI Agent development learning roadmap covering LLM API calls, ReAct framework, memory mechanisms, and multi-agent collaboration across four stages with timeline and project suggestions.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
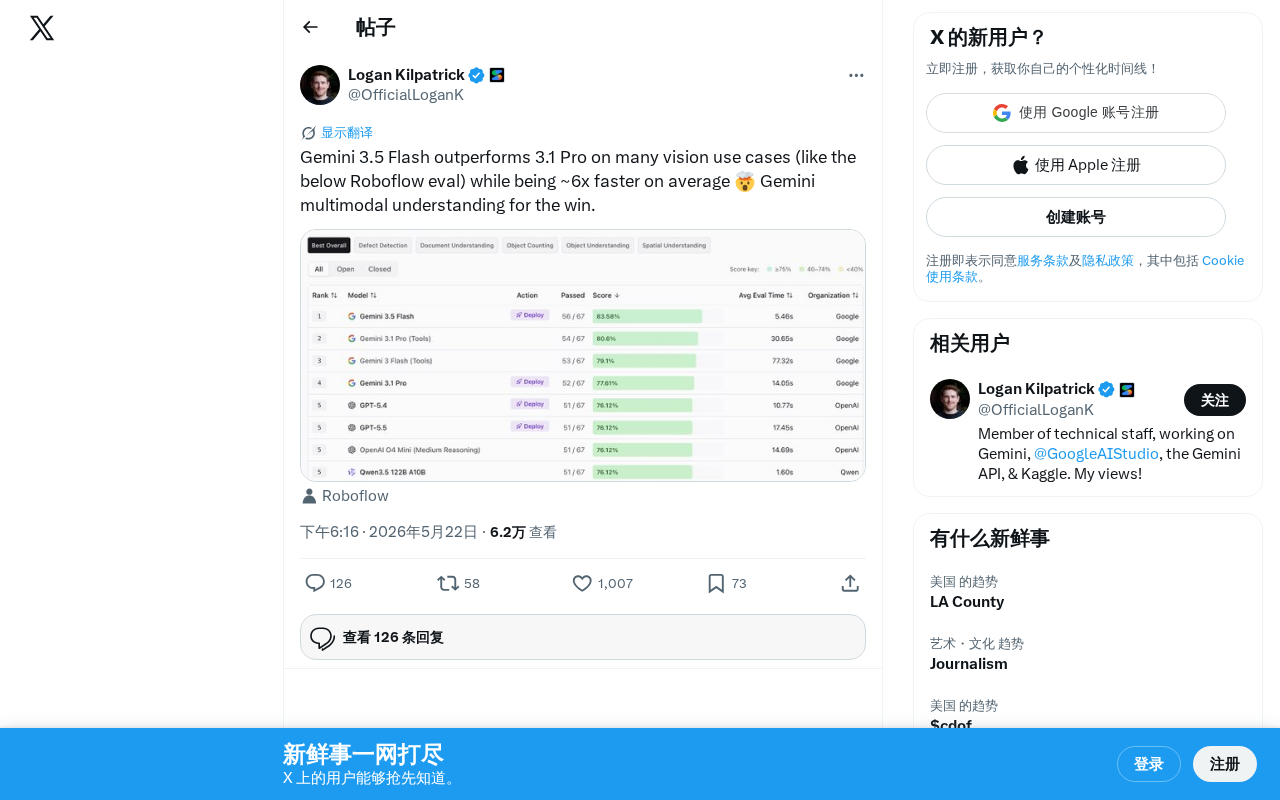
Gemini 3.5 Flash Surpasses Pro in Vision Capabilities, 6x Faster Inference
Roboflow benchmarks show Google Gemini 3.5 Flash outperforms the flagship Gemini 3.1 Pro on multiple vision tasks with ~6x faster inference, delivering a cost-effective multimodal AI solution.
Read more →
 Deep Dives
Deep Dives·2 min
The "Worse is Better" Philosophy of Large Model Design: Why Simple and Brutal Beats Refined and Complex
Analyzing the "worse is better" philosophy in large model architecture: why DeepSeek V4 dropped N-gram, why Transformer dominates AI, and three iron laws of simple, efficient model design.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
GPT-5.6 First Leak: How Self-Training Loops Enable OpenAI's Three-Week Iteration Cycle
OpenAI's GPT-5.6 has entered internal testing, just three weeks after GPT-5.5. The key accelerator is the self-training loop introduced in GPT-5.3, enabling exponential iteration speed.
Read more →
 Industry Insights
Industry Insights·4 min
In-Depth Analysis of the AI Large Model Job Market: Two Core Directions and Future Trends
In-depth analysis of the AI large model job market, breaking down the two core directions—algorithm research and engineering deployment—covering requirements, barriers, and career prospects.
Read more →
 Deep Dives
Deep Dives·4 min
Core Principles of the Transformer Architecture: A Deep Dive into Self-Attention Mechanisms and Engineering Optimizations
Deep dive into Transformer architecture covering self-attention QKV mechanics, Encoder-Decoder structure, Flash Attention memory optimization, RoPE positional encoding, and GQA inference acceleration.
Read more →
 Research
Research·2 min
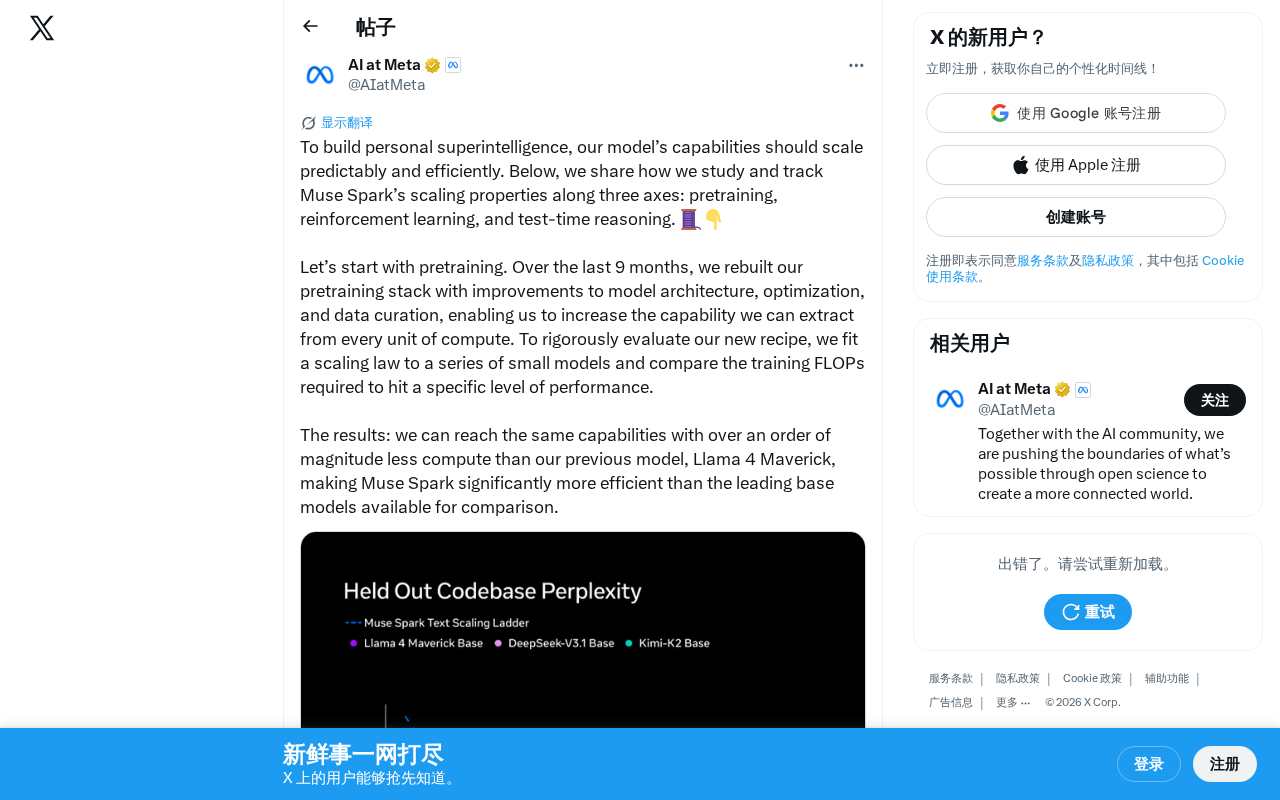
Meta Muse Spark Technical Deep Dive: How Three-Dimensional Scaling Achieves 10x Compute Reduction
Meta reveals Muse Spark technical details: three-dimensional scaling across pre-training, RL, and test-time inference achieves over 10x compute reduction versus Llama 4 Maverick.
Read more →
 Product Reviews
Product Reviews·2 min
How to Choose an AI Coding Plan? Comparing Cursor, ChatGPT, GLM, and Other Top Options
Compare top AI coding plans including Cursor Max, ChatGPT Pro, GLM Coding Plan, and DeepSeek API — with pricing, performance, and use-case recommendations to help you choose.
Read more →
Product Reviews
Running Qwen3.6-27B Locally on Mac: 4 …
·3 min
Running Qwen3.6-27B Locally on Mac: 4 Solutions Benchmarked
Benchmarking 4 solutions for running Qwen3.6-27B locally on Mac: GGUF, MLX Diflash, and MTP-LX. MTP-LX 4bit leads at 43.6 tok/s with solid coding, writing, and reasoning quality.
Read more →