Tsinghua and Zhipu Release Full-Stack Web Dev Benchmark: Top AI Models Fail Spectacularly
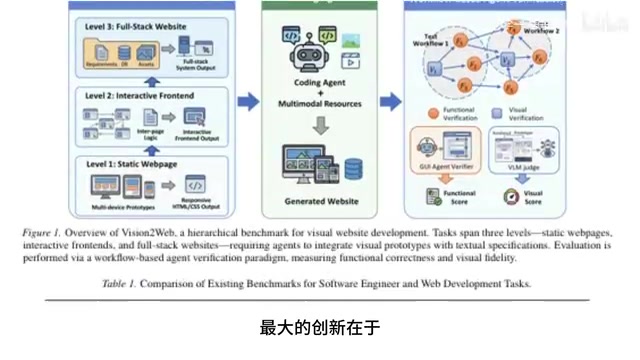
Top AI models score well on static pages but collapse on full-stack web development benchmarks.
Tsinghua University and Zhipu AI jointly released a full-stack web development benchmark with three progressive difficulty levels. While top models like Gemini 2.5 Pro score 63 on static pages, their visual fidelity drops to just 11.7 on full-stack tasks. The benchmark uses automated dual-dimension evaluation covering functionality and visual fidelity, revealing that current AI models still have a significant capability gap in complex engineering tasks requiring global planning and multi-module coordination.
AI Can Write Web Pages, But Can It Build Full Websites?
Ask AI to whip up a static web page, and it can deliver in minutes. But what happens when you ask it to build a complete full-stack website from scratch — including requirements documents, wireframes, database design, and state management?
Full-stack web development refers to the complete software development process encompassing the frontend (user interface), backend (server logic), database (data storage and querying), and the communication protocols between them. Unlike simple static page generation, full-stack development requires understanding the coordinated workings of multiple technology layers — HTTP request lifecycles, RESTful API design, ORM mapping, session management, authentication (such as OAuth and JWT), and more. A typical full-stack project might use React or Vue as the frontend framework, Node.js or Python as the backend runtime, PostgreSQL or MongoDB as the database, plus middleware like Redis caching and message queues. The coupling relationships and data flow logic between these components create engineering complexity far beyond single-file code generation.
The latest benchmark released jointly by Tsinghua University and Zhipu AI delivers a jaw-dropping answer: even today's most powerful large language models collectively stumble on full-stack web development tasks. Gemini 2.5 Pro can score 63 on static web pages, but when it comes to full-site tasks, its visual score plummets to just 11.7, with a functionality score of only 22.6.
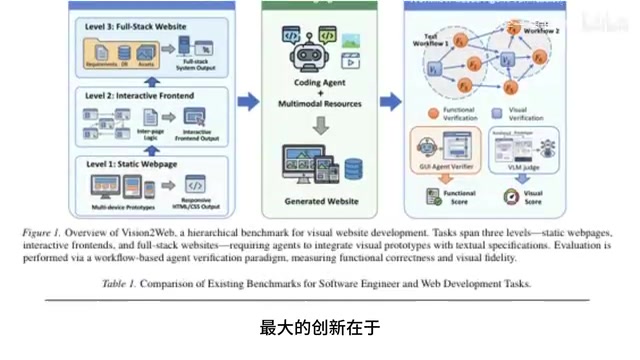
Three Difficulty Levels: From Static Pages to Full-Stack Systems
The biggest innovation of this benchmark lies in its progressively escalating difficulty design. Rather than testing only static pages or isolated code snippets as previous benchmarks did, it features three increasingly challenging levels:
Level 1: Responsive Static Web Pages
This is the most basic task, requiring AI to generate static pages that adapt to different screen sizes. The core technologies behind Responsive Design include CSS Media Queries, Flexbox, CSS Grid, relative units (rem, vw, vh), and Breakpoints design. Behind seemingly simple adaptation lies adaptive image cropping, mobile navigation collapse logic, differences between touch and mouse event handling, and cross-browser rendering engine compatibility. When handling these tasks, AI models can often generate reasonable desktop layouts but tend to make mistakes with element reflow during breakpoint transitions, hide/show logic, and interaction mode changes. At this level, top models perform reasonably well — Gemini 2.5 Pro scores around 63.
Level 2: Interactive Frontend Applications
The difficulty ramps up to frontend applications with page navigation and user interaction logic. Models need to handle routing, event binding, component communication, and other frontend engineering challenges. Modern frontend routing systems (such as React Router and Vue Router) must handle nested routes, dynamic parameters, route guards, lazy loading, and other complex scenarios. Component communication involves choosing appropriately among multiple patterns including props passing, event buses, Context/Provide-Inject, and state lifting.
Level 3: Full-Stack System Development
This is the true "nightmare mode" — requirements documents, wireframes, database design, state management, and frontend-backend integration are all required. This level directly exposes the shortcomings of current AI models on complex engineering tasks.

Test Results: SOTA Models Collectively Exposed
The tests covered today's leading models, including Claude, GPT series, and Gemini. The results revealed several key findings:
Cliff-Like Score Drops on Full-Stack Tasks
Gemini 2.5 Pro went from 63 on static web pages to just 11.7 for visual scores and 22.6 for functionality on full-site tasks — a drop exceeding 60%. This demonstrates that current models are severely lacking when handling long-process, multi-module collaborative engineering tasks.
Mobile Adaptation Is Universally Poor
All models scored 10% to 20% lower on tablet and mobile adaptation compared to desktop. Responsive design may seem like a frontend fundamental, but AI still struggles with the details of multi-device adaptation. Mobile challenges extend beyond layout adjustments to include touch gesture recognition, viewport changes when virtual keyboards appear, rendering differences between iOS and Android browsers, and a host of platform-specific issues like performance optimization for mobile networks.
Complex Business Scenarios Are the Hardest Hit
AI performance deteriorates even further on websites with complex business logic, such as transaction platforms and SaaS applications. SaaS (Software as a Service) applications typically require multi-tenant architecture (data isolation between different customers), fine-grained role-based access control (RBAC), subscription billing and payment integration, data import/export, audit logging, Webhook callbacks, and other enterprise-grade features. Additionally, they must account for performance optimization under high concurrency, data security compliance (such as GDPR), and complex business workflow engines. These requirements interweave to form an extremely complex system dependency graph, posing severe challenges to AI models' global planning capabilities — far beyond their current "comfort zone."

Innovation in Evaluation: Fully Automated Scoring
Another major highlight of this benchmark is its innovative evaluation approach. Traditional code evaluation relies either on manual review or simple unit testing, but this system employs fully automated dual-dimension assessment:
Functional Testing Dimension: AI Agents autonomously execute preset functional test cases to verify whether page navigation, form submission, data persistence, and other features work correctly. These AI Agents are typically built on browser automation frameworks (such as Playwright or Puppeteer), capable of simulating real user actions like clicking, typing, and scrolling, then verifying whether DOM state changes, network request responses, and local storage data meet expectations.
Visual Fidelity Dimension: Vision-Language Models (VLMs) compare screenshots of generated pages against prototype designs to assess visual fidelity. VLMs are a class of multimodal AI models that can understand both images and text simultaneously. The system captures multi-resolution screenshots of generated web pages, then feeds these screenshots alongside the original design mockups into the VLM, which scores them across multiple dimensions including layout structure, color matching, typography, spacing proportions, and component alignment. Compared to traditional pixel-level comparison methods (such as SSIM — Structural Similarity Index), this approach more closely mirrors human visual perception, tolerating reasonable implementation differences while catching obvious design deviations.
This approach is not only fair and reproducible but can also run at scale automatically, providing a reliable evaluation foundation for future model iterations.

Deeper Implications: Where Are the Real Boundaries of AI Development Capabilities?
The core value of this research lies in stripping away the "filter" on AI development capabilities. The AI coding demos we typically see are carefully selected simple scenarios — writing a component, fixing a bug, generating a function. But real software engineering goes far beyond that.
A complete web application development involves:
- Architecture Design: Technology selection, module decomposition, interface design. This requires developers to make forward-looking judgments early in the project about system scalability, maintainability, and performance bottlenecks — for example, choosing between microservices and monolithic architecture, adopting event-driven versus request-response patterns, and how to design API versioning strategies.
- State Management: Cross-page data synchronization, caching strategies. In complex single-page applications, application state includes user login information, shopping cart data, form inputs, API response caches, UI interaction states, and more. The real difficulty lies in maintaining data consistency across multiple components, handling race conditions from asynchronous operations, designing appropriate state granularity to avoid unnecessary re-renders, and correctly restoring state during page refreshes or route transitions.
- Exception Handling: Edge cases, error recovery, graceful degradation. Exception handling in production environments is far more complex than try-catch — it requires considering network timeout retry strategies, eventual consistency in distributed transactions, circuit breaking and service degradation, and user-friendly error messages with recovery guidance.
- Engineering Standards: Code organization, maintainability, performance optimization. This includes sensible directory structures, code splitting and lazy loading, Tree Shaking, CDN deployment strategies, and CI/CD pipeline configuration.
Current models shine on individual tasks, but there remains a clear capability gap when it comes to complex engineering tasks requiring global planning and long-range dependency management. This also points the way forward for AI-assisted development tools — it's not about simply generating more code, but about developing genuine engineering thinking and system design capabilities.
Conclusion
This work from Tsinghua and Zhipu provides a more realistic evaluation standard for the AI code generation field. It reminds us that while celebrating AI's programming capabilities, we must also soberly recognize that there's still a long road between "can write code" and "can do engineering." For developers, AI currently serves better as a productivity tool rather than a replacement, especially in complex full-stack projects. Future breakthroughs will likely come from giving AI models stronger long-context reasoning abilities, multi-step planning capabilities, and deep internalization of software engineering best practices — rather than merely pursuing higher accuracy rates on single code generation tasks.
Related articles
DiffusionGemma: Google's Open-Source Diffusion Language Model Exceeding 500 Tokens/s
Google releases DiffusionGemma, an open-source diffusion language model with Apache 2.0 license. The 26B-parameter MoE model achieves over 500 tokens/s in real-world tests.
Reviving a 28-Year-Old Quake 2 Custom …
Reviving a 28-Year-Old Quake 2 Custom Map with AI: New Possibilities in Digital Archaeology
A developer used AI tools to revive a 28-year-old Quake 2 custom map as a browser game, showcasing AI's new role in digital heritage restoration and game preservation.
Replit's Revenue Incentive Policy Explained: Earn Money on the Platform, Get Free Credits
Replit's new revenue incentive policy gives developers free credits when they earn money on the platform. A deep dive into its impact on indie developers and the AI platform landscape.