Why Are AI Product Waitlists Getting Longer? The Waiting Dilemma from Siri to Large Language Models
AI product waitlists are growing longer, driven by compute bottlenecks and outpacing user patience.
From Apple's Siri AI upgrade to various LLM API queues, waitlists have become standard in AI product launches. This article analyzes the GPU compute bottlenecks, potential marketing strategies, and user experience impacts behind these growing wait times, exploring the path from waiting to availability as AI infrastructure matures.
When Waiting Becomes the New Normal in the AI Era
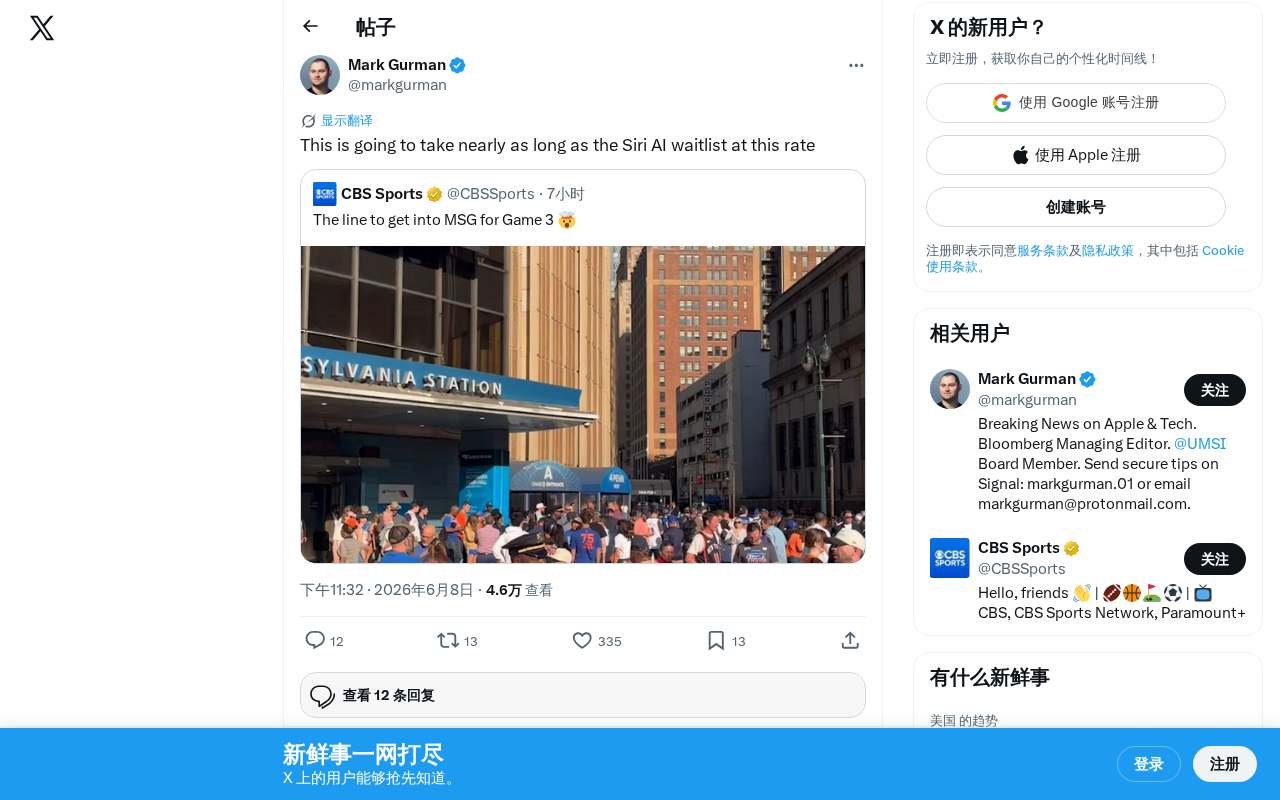
Recently, a Twitter user posted a complaint: "At this rate, the wait time is about to rival the Siri AI waitlist." This seemingly simple gripe actually reflects a widespread and frustrating phenomenon in the AI product space—users are experiencing increasingly longer wait cycles.
From Apple Intelligence's upgraded Siri to the queuing mechanisms of various LLM APIs, the "waitlist" has become a standard strategy for AI product launches. Users' patience is being tested time and again.
The Siri AI Waitlist: An Iconic Symbol of Endless Waiting
Apple announced its Apple Intelligence initiative at WWDC, which included a major AI upgrade to Siri. However, this highly anticipated feature didn't roll out broadly as expected. A large number of users were placed on a waitlist, and the wait has become so prolonged that it's turned into a widely circulated meme in the tech community.
Apple's strategy has its merits: large-scale AI inference requires enormous computational resources, and a phased rollout ensures service quality and system stability. But for users who've already purchased the latest hardware, this waiting game is undeniably anxiety-inducing. When other AI products' wait times are compared to the Siri waitlist, it's clear that this wait has become synonymous with "forever."
The Industry Logic Behind AI Waitlists
Compute Bottlenecks Are the Core Issue
The fundamental reason AI products widely adopt waitlist mechanisms is the severe supply-demand imbalance in GPU compute power. Whether it's OpenAI, Google, or Apple, deploying AI services at scale faces hard infrastructure constraints. Every user request consumes significant computational resources—a fundamental difference from traditional software services.
Hunger Marketing or Genuine Necessity?
Some argue that waitlists themselves serve as a marketing strategy—creating scarcity to boost perceived product value. But more objectively, most AI companies genuinely face real capacity limitations. Take OpenAI as an example: its GPT-4 API waitlist stretched for months after launch, backed by very real server costs and supply chain pressures.
A Double-Edged Sword for User Experience
While waitlist mechanisms can ensure quality of experience for onboarded users, they also bring undeniable negative effects:
- Declining user enthusiasm: The longer the wait, the more easily anticipation transforms into disappointment or abandonment
- Opportunity windows for competitors: While one company makes users queue, another may already be offering a viable alternative
- Brand trust erosion: Repeated delays and waiting gradually consume users' trust and goodwill toward a brand
From Waiting to Availability: The Maturation Path for AI Products
Looking back at tech industry history, similar waiting periods aren't without precedent. Gmail used an invitation system when it launched in 2004, requiring users to obtain invite codes to register; cloud computing services similarly went through phases of insufficient capacity in their early days.
But waiting in the AI space has its unique characteristics: users aren't just waiting for access—they're waiting for features to gradually mature. Many AI products, even after opening access, may still have core features in a "coming soon" state. Siri's AI upgrade is a textbook case—even for users who've gained access, many promised advanced features remain under active development.
The current AI waitlist phenomenon fundamentally reflects the time gap between the pace of industry development and infrastructure buildout. As inference chip production capacity increases, model efficiency continues to improve, and edge computing gradually becomes widespread, these waits will eventually shorten. But until then, patience may be the most essential "skill" users need in the AI era.
Conclusion: Waiting Shouldn't Be the First Step in Experiencing AI
A brief complaint tweet voices what countless AI product users feel. When "queuing up" becomes the first step in experiencing AI, the industry needs to think beyond just technical problems—it must consider how to manage user expectations and how to maximize user satisfaction under limited capacity. After all, no matter how powerful an AI is, if users lose interest while waiting, it loses the very meaning it was meant to have.
Related articles
Getting Started with Claude Code: An AI Programming Tool Anyone Can Learn Quickly
A complete guide to Claude Code: installation, setup, natural language programming, CLAUDE.md configuration, real-world use cases, and pricing plans for beginners.

5 Ways to Deploy LLMs Locally: From Getting Started to Production
A complete guide to 5 local LLM deployment methods: LlamaCPP, Ollama, LM Studio, vLLM/SGLang, and MLX-LM — from personal dev to production environments.
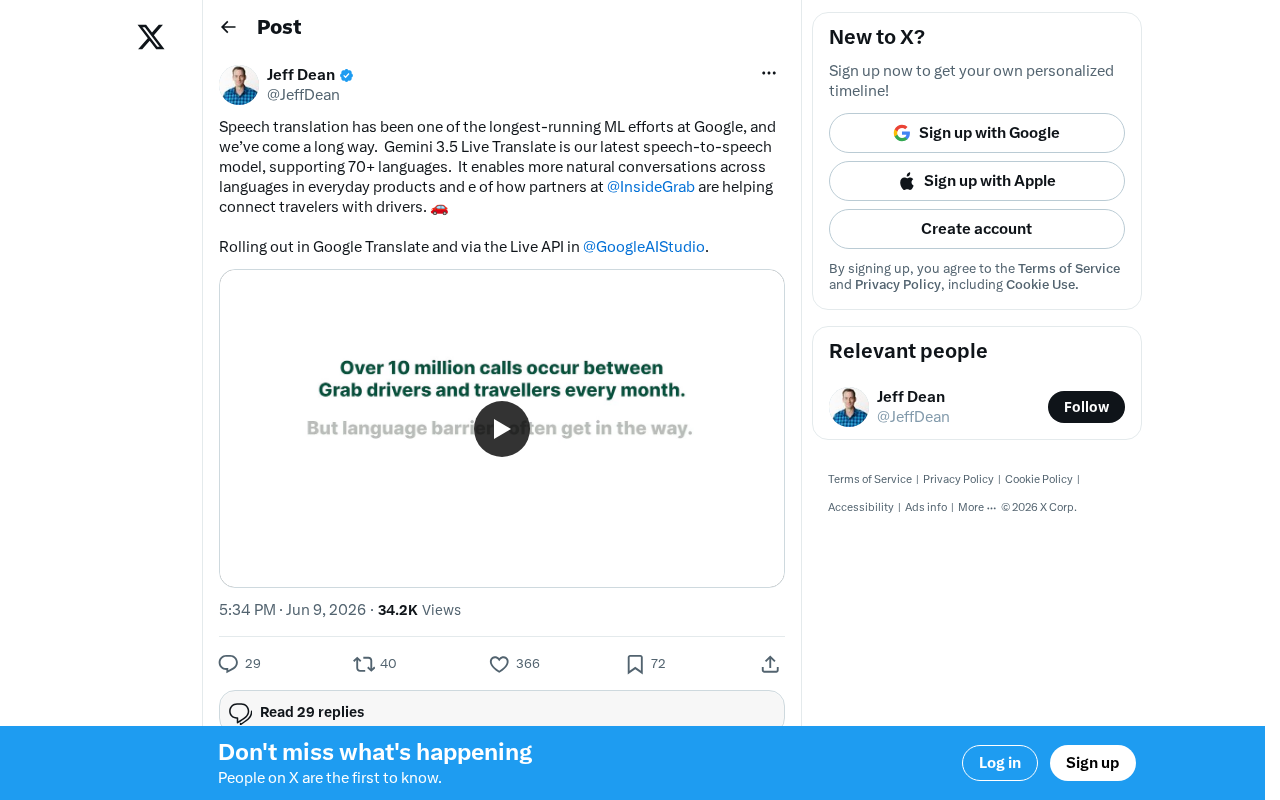
Gemini 3.5 Live Translate Launch: A Deep Dive into the Speech-to-Speech Translation Model Supporting 70+ Languages
Google launches Gemini 3.5 Live Translate, a speech-to-speech translation model supporting 70+ languages. Learn about its end-to-end architecture, Grab partnership, and developer access via Live API.