Xiaomi Open-Sources MiMo Code: Can an Infinite Memory Mechanism Solve AI Coding's Biggest Pain Point?
Xiaomi's open-source MiMo Code tackles AI coding's context forgetting problem with infinite memory and multi-Agent collaboration.
Xiaomi has open-sourced MiMo Code, an AI coding tool designed to solve the critical context forgetting problem that plagues current AI programming assistants. It features an infinite memory mechanism using a distill-compress-recall pipeline based on optimized RAG, a multi-Agent architecture splitting coding, review, and testing into specialized roles, and full compatibility with the Claude Code ecosystem. Accessible without a VPN in China, it offers a practical alternative for domestic developers.
Xiaomi recently open-sourced an AI coding tool called MiMo Code, targeting the most frustrating pain point in AI-assisted programming — context forgetting. With its infinite memory mechanism, multi-Agent collaboration architecture, and seamless compatibility with the Claude Code ecosystem, MiMo Code has attracted widespread attention from the domestic developer community since its release.
AI Coding Tools' Fatal Flaw: Context Forgetting
Today's mainstream AI coding tools — whether Claude Code, Cursor, or others — all face a common structural challenge when handling large projects: as conversation turns increase and codebases grow, the model's context window gradually fills up, pushing out critical earlier information and causing a sharp decline in generation quality.
The symptoms are clear: AI writes code quickly and well at the start of a project, but as the codebase grows to thousands or even tens of thousands of lines, the model starts "losing its memory" — forgetting previously defined interface specifications, overlooking existing utility functions, reinventing the wheel, or even generating code that contradicts existing logic. This problem is especially pronounced in real engineering projects, where codebases routinely span hundreds of thousands of lines, far exceeding the context window limits of any current model.
This isn't a flaw specific to any one model — it's a fundamental limitation of Transformer-based large language models when it comes to long-context processing. The Transformer is the underlying architecture behind virtually all current LLMs, introduced by Google in the 2017 paper Attention Is All You Need. Its core mechanism — Self-Attention — has computational complexity that scales quadratically with sequence length, meaning that longer context windows lead to exponentially higher resource consumption. Although various long-context techniques in recent years (such as ALiBi positional encoding, Ring Attention, and sparse attention) have expanded windows from a few thousand tokens to the million-token range, models still suffer from "attention decay" over ultra-long contexts. Academics call this the "Lost in the Middle" phenomenon — models tend to focus more on the beginning and end of input sequences while neglecting information in the middle. This is the deep technical reason why AI coding tools frequently "forget" in large projects.
MiMo Code's Core Solution: How the Infinite Memory Mechanism Works
To address context forgetting, MiMo Code proposes a systematic solution — the infinite memory mechanism. Rather than simply expanding the context window, its core approach builds an intelligent knowledge management system.
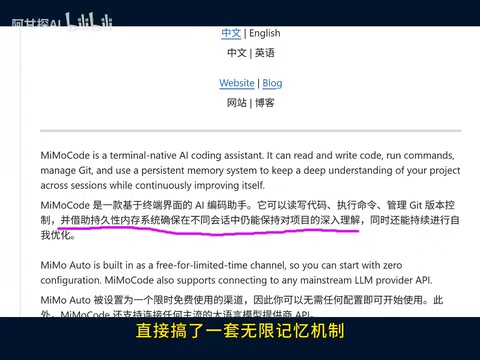
The mechanism's workflow can be summarized in three steps:
Step 1: Automatically Distill Key Knowledge
During the coding process, MiMo Code automatically identifies and extracts critical knowledge points from the project, including but not limited to: core architectural designs, interface definitions, data models, and business logic rules. This isn't simple text extraction — it's structured distillation based on semantic understanding.
Step 2: Compress and Archive to an External Memory Store
The distilled knowledge is compressed into high-density structured summaries and stored in an independent memory store. The benefit is that critical information is no longer constrained by the model's context window size — instead, it's persistently saved as external storage.
Step 3: Context-Aware Precision Recall
When historical knowledge is needed, the system performs semantic matching based on the current coding context and precisely recalls the most relevant memory fragments to inject into the current conversation. According to the developers, MiMo Code can maintain context coherence even when dealing with codebases of hundreds of thousands or even millions of lines.
This "distill-compress-recall" paradigm essentially applies the RAG (Retrieval-Augmented Generation) approach to solve long-term memory problems in coding scenarios, with deep optimizations for code-specific use cases. RAG is a technical paradigm proposed by Meta AI in 2020 that combines information retrieval with text generation. Its core idea is to avoid relying solely on the model's parametric memory to store all knowledge, instead dynamically retrieving relevant information from external knowledge bases during generation. A typical RAG pipeline involves three stages: first, documents are chunked and converted into vectors via an Embedding Model and stored in a vector database; then, at query time, the user input is similarly vectorized and the most relevant document fragments are found through similarity search; finally, the retrieved results are concatenated with the original query and fed into the LLM for generation. In code scenarios, RAG needs to be specifically optimized for code's structural characteristics — such as function call relationships, module dependency graphs, and type definition hierarchies — to achieve precise semantic matching rather than simple text similarity comparison. MiMo Code's memory mechanism is an engineering implementation in exactly this direction.
Multi-Agent Collaboration Architecture: Development, Review, and Testing in One Pipeline
Beyond the memory mechanism, another major highlight of MiMo Code is its built-in multi-Agent collaboration architecture.

Traditional AI coding tools typically use a single model to handle everything end-to-end — acting as both coder and reviewer. This is like having the same person write and review their own code — it's hard to spot your own blind spots. MiMo Code instead breaks the programming workflow into multiple specialized Agent roles:
- Coding Agent: Responsible for generating code based on requirements
- Review Agent: Performs quality reviews on generated code, checking for potential bugs and standards violations
- Testing Agent: Automatically generates test cases and runs verification
These Agents form a complete closed loop, simulating the "develop-review-test" workflow of a real software development team. This mechanism effectively reduces the rate of low-level errors in AI-generated code and improves overall code quality.
Multi-Agent Systems are an important research direction in AI, with roots in distributed artificial intelligence. In the era of large language models, the core idea of multi-Agent architecture is to decompose complex tasks among multiple AI agents with different roles and capabilities, completing tasks through their collaboration, dialogue, and feedback. Representative frameworks in this paradigm include Microsoft's AutoGen, Stanford's Generative Agents, and CrewAI. Compared to single-Agent approaches, multi-Agent architecture offers advantages on three levels: first, specialization allows each Agent to focus on optimizing a specific domain — for example, a review Agent can perform deep checks specifically targeting security vulnerabilities and performance bottlenecks; second, multi-perspective review effectively reduces the "self-confirmation bias" of a single model — the tendency for a model to assume its own generated code is correct; finally, the pipeline-style workflow also aligns more closely with the DevOps philosophy in real software engineering practice, upgrading AI-assisted programming from "writing code" to "doing engineering."
Ecosystem Compatibility and Developer-Friendliness in China
From a practical deployment perspective, MiMo Code made two very pragmatic decisions.

Compatible with the Claude Code ecosystem, with zero migration cost. Claude Code is a command-line AI coding tool released by Anthropic, based on its Claude series of large language models. It allows developers to interact with AI directly in the terminal to write, debug, and refactor code, with support for system-level operations like reading/writing files and executing commands. Claude Code has built up a large user base in the overseas developer community, forming a rich ecosystem that includes custom System Prompts, CLAUDE.md project configuration files, and MCP (Model Context Protocol) tool extensions. For developers already using Claude Code, switching to MiMo Code requires virtually no additional learning. Existing workflows, prompt templates, and project configurations can all be directly reused, significantly lowering the migration barrier. This is a classic "leverage the existing" strategy — rapidly acquiring existing users by reducing migration costs while accelerating the maturation of its own toolchain by leveraging the established ecosystem.
Supports China's domestic network environment, no VPN required. MiMo Code supports various domestic and international advanced coding models, with some models available for free for a limited time, all accessible without circumventing the Great Firewall. This is hugely significant for developers in China — previously, using overseas tools like Claude Code meant network access itself was a considerable hurdle, affecting not only the user experience but also raising compliance concerns. MiMo Code's native support in China's network environment means developers can seamlessly incorporate AI coding tools into their formal development workflows in daily work, rather than treating them merely as personal experimental aids.
A Rational Perspective: MiMo Code Still Needs Time to Prove Itself
Of course, we need to stay rational. MiMo Code has just been open-sourced, and the performance of its infinite memory mechanism in large-scale real-world projects remains to be validated. Whether the knowledge distillation is precise enough, whether recall introduces noise, and what the latency and cost implications of multi-Agent collaboration are — these are all questions that the community will need to gradually verify through actual use.
The precision of memory recall deserves particular attention. A common challenge in RAG systems is "semantic drift" — where retrieved content appears superficially relevant to the query but isn't actually applicable in the specific code context, and may even mislead the model into generating incorrect code. For example, a project might contain multiple functions with the same name but different functionalities distributed across different modules. Whether the memory system can accurately distinguish and recall the correct one will directly determine the tool's practical value. Additionally, while multi-Agent collaboration improves code quality, it inevitably increases the number of inference calls and response latency — a trade-off that efficiency-focused developers will need to weigh.
That said, Xiaomi's open-sourcing of MiMo Code clearly demonstrates the technical ambition of major Chinese tech companies in the AI coding tools space. Starting from real pain points and using engineering solutions to compensate for model-level limitations — this approach itself deserves recognition. For developers in China, having one more high-quality open-source option is always a good thing.
Key Takeaways
Related articles

Five Common Claude Code Mistakes — How Many Are You Making?
Five common Claude Code mistakes developers make: copy-pasting code, skipping CLAUDE.md, inefficient prompting, ignoring docs, and poor context management — with fixes.

Andrew Ng's New Course Explained: A Practical Guide to Using OpenAI's O1 Reasoning Model
Deep dive into Andrew Ng and OpenAI's Reasoning with O1 course covering test-time scaling, new prompting paradigms, multi-model orchestration, and practical applications for developers.

Learning AI After College Entrance Exams: A Complete Path from Zero to Freelancing
How to efficiently learn AI skills during summer break after exams? A complete path from mastering prompts and hands-on projects to freelancing on platforms.