#开源模型
共 405 篇相关文章
 产品体验
产品体验·7 分钟
AI API中转平台推荐:一个密钥调用所有主流大模型
详解AI API中转平台的核心功能与使用体验,一个密钥即可调用GPT、Claude等主流大模型,比官方价格便宜20%。涵盖注册流程、Cursor配置方法、费用追踪及数据安全注意事项。
阅读全文 →
 产品体验
产品体验·5 分钟
GLM 5.1满血旗舰模型实测400 TPS,两分钟从草图到完整应用
实测智谱GLM 5.1 High Speed API,满血旗舰模型输出速度达400 Token/s。从草图还原页面到零基础生成完整解谜游戏,验证速度与能力兼得的AI编程新体验。
阅读全文 →
 产品体验
产品体验·5 分钟
Alex AI开发助手:Maya艺术家用自然语言生成插件代码
Alex AI开发助手让Maya艺术家无需编程基础,通过自然语言描述需求即可生成可执行的Maya插件代码。支持DeepSeek等大模型接入,一键执行、保存到菜单,大幅降低3D工具开发门槛。
阅读全文 →
 产品体验
产品体验·5 分钟
Trae下载安装教程:字节AI编程IDE完整体验评测
详细介绍字节跳动AI编程工具Trae的下载安装、界面功能及实际编程体验,支持Claude 3.7 Sonnet和DeepSeek R1满血版,免费使用的Cursor国产平替方案。
阅读全文 →
 行业洞察
行业洞察·4 分钟
NVIDIA验证Agent技能框架:AI代理能力治理新标准
NVIDIA发布验证代理技能框架,为AI Agent提供系统化能力治理方案。深入解析该框架如何通过技能认证、权限控制与MCP协议集成,解决企业级AI代理部署中的安全性与可控性难题。
阅读全文 →
 产品体验
产品体验·6 分钟
ccusage:一行命令算清AI编程真实花费
ccusage是一款开源CLI工具,帮助开发者分析Claude Code、Cursor等AI编程助手的Token消耗和成本。支持按项目、模型、时间维度生成消费报告,让AI编程开销一目了然。
阅读全文 →
 教程攻略
教程攻略·5 分钟
普通人玩AI编程必看:模型选择、工具上手、实战应用三大核心问题
普通人入门AI编程最关心哪些问题?本文从模型选择(GPT vs DeepSeek)、工具使用(Cursor/Codex/Claude Code)、实际应用三个维度,帮你理清AI编程的学习路径和避坑指南。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Claude Code接入DeepSeek V4:省99%成本的完整配置教程
详细教程:通过CC Switch工具将Claude Code接入DeepSeek V4,实现1%成本的AI编程方案。包含安装配置步骤、多模型协作实操演示、模型选择框架及OpenRouter免费方案。
阅读全文 →
 行业洞察
行业洞察·5 分钟
日本AI大模型困境:为何依赖中国DeepSeek?
日本最大AI模型Rakuten AI基于中国DeepSeek微调开发,揭示日本在大语言模型竞赛中的结构性困境。从算力投入、人才流失到语言数据局限,分析全球AI竞争格局中"中国不创新"叙事如何被现实击碎。
阅读全文 →
 教程攻略
教程攻略·5 分钟
2026年AI大模型开发学习路线:零基础到企业级落地实战指南
详解2026年AI大模型开发完整学习路径,涵盖Prompt工程、RAG检索增强、Agent智能体开发、模型微调四大核心技术栈,附零基础分阶段学习计划,助你快速掌握企业级AI应用开发落地能力。
阅读全文 →
 行业洞察
行业洞察·4 分钟
Anthropic中美AI竞争白皮书解读:美国如何保持前沿AI领先优势
Anthropic发布中美AI竞争白皮书,分析美国在前沿AI领域的领先地位、面临的关键挑战及维持优势的战略路径。本文深度解读白皮书核心观点,涵盖技术扩散、芯片管控、联盟合作等关键议题。
阅读全文 →
 科技前沿
科技前沿·5 分钟
OpenAI双重标记AI图片:C2PA与SynthID如何识别AI生成内容
OpenAI为AI生成图片引入C2PA元数据与SynthID隐形水印双重标记机制,并开放公开验证工具。本文解析两种技术的工作原理、互补优势及行业影响,探讨AI内容溯源面临的挑战与未来方向。
阅读全文 →
 行业洞察
行业洞察·3 分钟
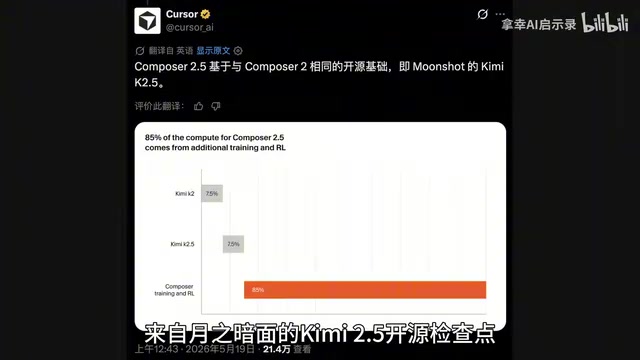
Cursor Composer 2.5深度解析:开源模型1/10成本叫板Claude 4.7
Cursor发布Composer 2.5,基于开源模型Kimi K2.5实现与Claude 4.7 Opus持平的编程能力,成本仅为十分之一。深度解析三大技术突破、AI自主学会逆向工程的安全隐患,以及与SpaceX AI百万H100算力合作的战略布局。
阅读全文 →
 产品体验
产品体验·6 分钟
Gemini 3.5 Flash实测对比Qwen3.6:排行榜高分与真实体验差多远?
深度实测Gemini 3.5 Flash在UI生成、编程、Agent能力等维度的真实表现,与Qwen3.6-27B横向对比,揭示大模型排行榜分数与实际体验之间的落差,帮你理性选择AI模型。
阅读全文 →
 产品体验
产品体验·6 分钟
pi-plugin-cc:让Claude Code一秒接入任意大模型
pi-plugin-cc是一款开源Claude Code插件,通过Pi编码Agent实现模型自由切换,支持DeepSeek、OpenAI、Ollama等任意大模型接入,帮助开发者降低成本、灵活调配AI编程资源。
阅读全文 →
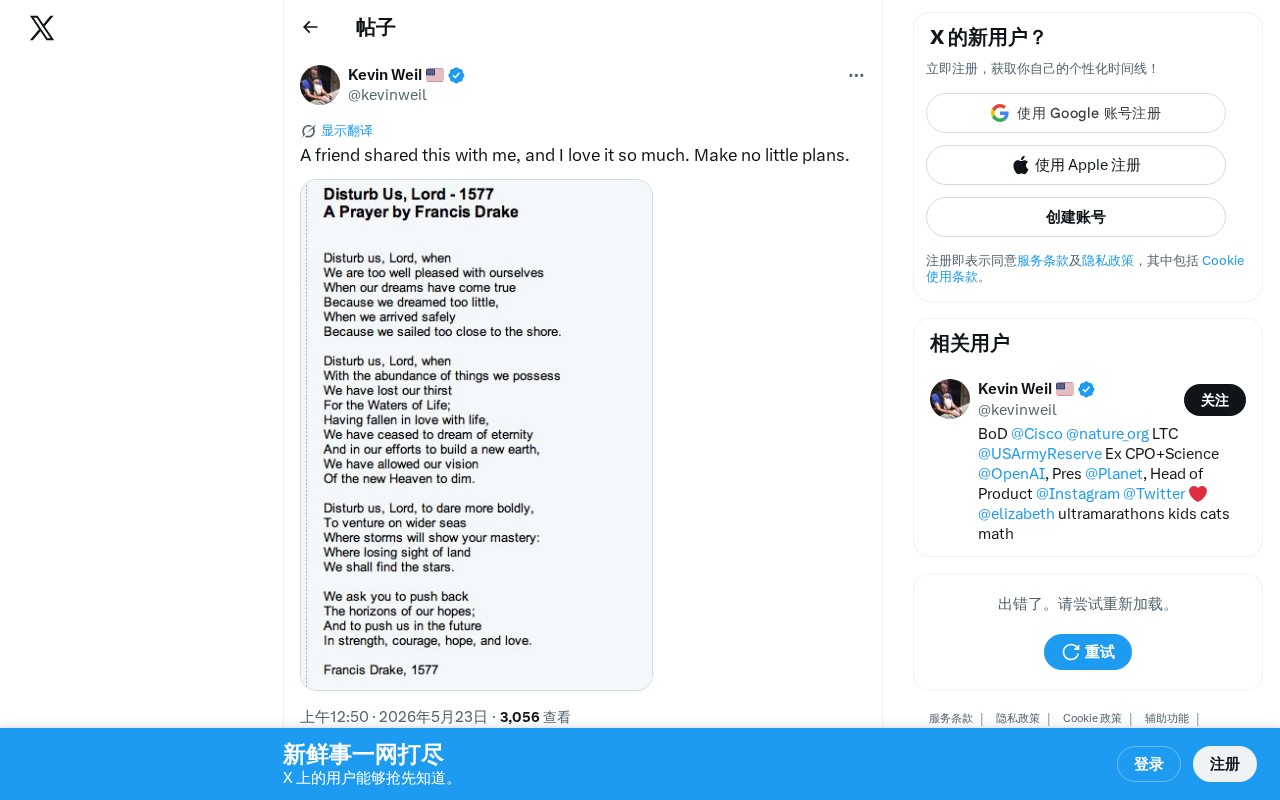 观点碰撞
观点碰撞·4 分钟
Make No Little Plans:AI时代为什么要敢做大计划
AI时代技术杠杆让宏大计划的门槛大幅降低。本文从丹尼尔·伯纳姆的经典名言出发,解析为什么小计划反而难以实现,以及如何利用AI工具放大个人能力、用终局思维规划颠覆性愿景,在技术拐点抢占先机。
阅读全文 →
 行业洞察
行业洞察·5 分钟
Kimi K2.6一周登顶OpenRouter榜首:1.88T Token背后的开发者迁移逻辑
Kimi K2.6上线OpenRouter仅一周,以1.88T Token调用量登顶平台第一,周环比暴涨7683%。本文分析开发者选择迁移的核心原因:256K上下文、Agent稳定性与价格优势如何形成三角匹配,以及AI模型竞争从发布竞赛转向留存竞赛的趋势。
阅读全文 →
 教程攻略
教程攻略·4 分钟
Claude Max被封后OpenCode替代方案全解析
Anthropic封锁第三方工具访问Claude Code接口后,开发者如何继续使用OpenCode?本文详解GitHub Copilot官方支持、Anti-Gravity免费方案、ChatGPT直连等替代方案,附价格对比与风险评估。
阅读全文 →
 科技前沿
科技前沿·4 分钟
AI周报:Codex子代理、MiniMax M2.7、英伟达GTC与Claude百万token窗口
本周AI重磅更新汇总:OpenAI Codex推出子代理并行编码功能,MiniMax M2.7开源模型即将发布,英伟达GTC发布Neutron Ultra与DLSS 5,Claude Code升级至百万token上下文窗口,全面解读行业最新动态。
阅读全文 →
 产品体验
产品体验·5 分钟
DeepSeek V4深度解析:混合注意力+流形约束+MOM优化器三大创新全解读
深度解析DeepSeek V4三大底层技术创新:混合注意力架构实现百万Token上下文、流形约束超连接稳定极深网络训练、MOM优化器加速收敛。V4 Pro性能对标Claude Opus 4.6,成本仅为其七分之一,附编程实测与部署方案。
阅读全文 →