#AI评估
共 24 篇相关文章

·6 分钟
ViBench基准测试:端到端应用创建能力评估揭示AI编程真实水平
ViBench是首个基于真实世界任务的端到端应用创建基准测试,评估AI从零构建完整应用的能力。测试结果显示Claude Opus 4.8在性能和性价比上领先,揭示了传统SWE-bench与实际开发能力的差距。
阅读全文 →
 行业洞察
行业洞察·5 分钟
GPT-5.5在Databricks文档解析中错误率降低46%:实测数据与架构解析
Databricks实测显示GPT-5.5在复杂文档解析中错误率降低46%,成为唯一突破50%准确率的模型。本文详解其在数字解析、多智能体架构中的关键突破及企业落地方案。
阅读全文 →
产品体验
Fabraix:1000+对抗策略,找出AI Agent隐藏缺陷
·6 分钟
Fabraix:1000+对抗策略,找出AI Agent隐藏缺陷
Fabraix是一款由前Meta工程师打造的AI Agent对抗性测试工具,通过1000+自适应攻击策略,以纯黑盒方式零集成发现Agent的幻觉、安全漏洞和逻辑错误,帮助开发者在用户之前定位问题。
阅读全文 →
 产品体验
产品体验·4 分钟
千星项目被自己的AI判定不及格:独立开发者如何评估创业方向
一个GitHub千星、已盈利的AI求职助手项目,在自研评估工具中仅得55分。本文解析55分背后的三重风险预警,以及独立开发者如何用AI工具在早期识别创业方向的隐患,避免踩坑。
阅读全文 →
 教程攻略
教程攻略·5 分钟
AI产品经理简历写Vibe Coding的四大误区与正确写法
AI产品经理求职简历中如何正确呈现Vibe Coding能力?本文梳理四大常见误区:跳过需求分析、不懂技术选型、盲目选工具、不做测试评估,并给出可直接套用的简历写法参考,帮你写出有含金量的AI编程经历。
阅读全文 →
 教程攻略
教程攻略·6 分钟
用AI调试AI:Incident.io的三大实战模式详解
Incident.io分享用AI调试AI的三大实战模式:让编码Agent掌控Eval工作流、将调试UI转化为文件系统、构建AI分析流水线。深入解析复杂AI系统的调试方法论与工程实践。
阅读全文 →
 教程攻略
教程攻略·9 分钟
引导AI自创解决方案的3种提示词策略|附火箭推进器案例
如何用提示词工程让AI跳出常规方案,自创独特解决路径?本文详解排除法、约束驱动法和多轮迭代法三种提示词策略,结合生成式设计火箭推进器的真实案例,帮你解锁AI创造力边界。
阅读全文 →
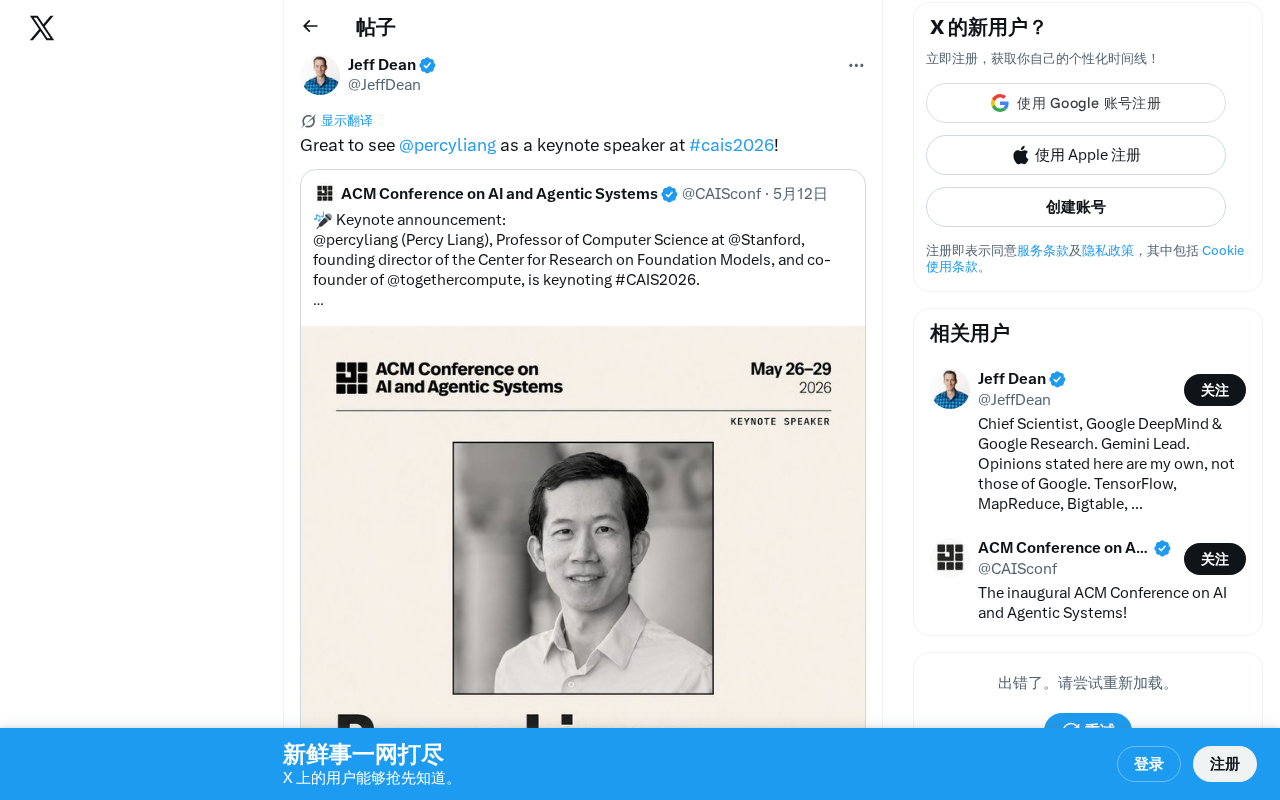 科技前沿
科技前沿·6 分钟
Percy Liang确认出席CAIS 2026:AI安全与大模型评估的前沿对话
斯坦福大学教授Percy Liang将在CAIS 2026发表主题演讲,聚焦HELM大模型评估框架、AI透明度指数等前沿议题。了解这位AI评估领域领军人物的核心贡献及CAIS大会看点。
阅读全文 →
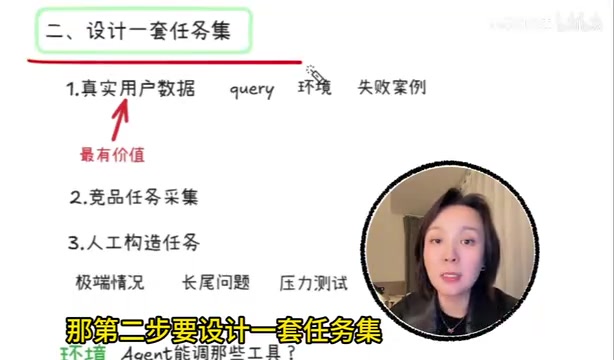 深度解读
深度解读·9 分钟
Agent评估五维体系:AI产品经理面试必考题全解析
详解AI Agent评估的五维体系——诚、快、省、稳、安全,涵盖任务集设计、过程与结果评估、对照实验等核心方法,帮助AI产品经理在面试和实际工作中系统化评估Agent产品质量。
阅读全文 →
 教程攻略
教程攻略·11 分钟
Agent可观测性完整方案:追踪、评估与Red Teaming实战指南
深入解析Microsoft Foundry的Agent可观测性方案,涵盖多Agent追踪、AI质量评估、Red Teaming安全测试及Prompt自动优化,帮助开发者弥合Agent预期行为与实际表现的差距。
阅读全文 →
 前沿研究
前沿研究·5 分钟
英国AISI评估报告:GPT-5.5网络安全能力比肩Claude Mythos
英国AI安全研究所(AISI)发布GPT-5.5网络安全能力评估报告,结果显示其漏洞发现能力与Claude Mythos相当,但GPT-5.5已公开可用,带来更大安全影响。本文解读评估结果及行业启示。
阅读全文 →
 深度解读
深度解读·8 分钟
AI Agent测试难在哪?模拟测试破解无限输入空间
AI Agent面临无限输入空间和非确定性输出,传统测试方法难以应对。本文深入解析模拟测试如何通过场景生成、环境模拟和行为评估,系统性地验证AI Agent的可靠性与安全性,帮助开发团队构建可信赖的AI系统。
阅读全文 →
科技前沿
英国AI安全研究所评估GPT-5.5:网络安全能力比肩Claude Mythos
·6 分钟
英国AI安全研究所评估GPT-5.5:网络安全能力比肩Claude Mythos
英国AI安全研究所(AISI)发布GPT-5.5网络安全能力评估报告,结果显示其漏洞发现能力与Claude Mythos相当,但GPT-5.5已公开可用。本文解读评估核心发现及其对AI安全治理的深远影响。
阅读全文 →
 前沿研究
前沿研究·7 分钟
英国AISI评估GPT-5.5网络安全能力:与Claude Mythos相当但已公开可用
英国AI安全研究所(AISI)发布GPT-5.5网络安全能力评估报告,结果显示其漏洞发现能力与Claude Mythos相当。关键区别在于GPT-5.5已面向公众开放,对AI安全治理提出更紧迫要求。
阅读全文 →
 前沿研究
前沿研究·9 分钟
英国AISI评估报告:GPT-5.5网络安全能力与Claude Mythos相当
英国AI安全研究所(AISI)发布GPT-5.5网络安全能力评估报告,结果显示其漏洞发现能力与Claude Mythos相当,但关键区别在于GPT-5.5已向公众开放。本文解读评估核心发现及对AI安全治理的影响。
阅读全文 →
 前沿研究
前沿研究·6 分钟
英国AI安全研究所评估GPT-5.5:网络安全能力比肩Claude Mythos
英国AI安全研究所(AISI)发布GPT-5.5网络安全能力评估报告,结果显示其漏洞发现能力与Claude Mythos相当,但GPT-5.5已面向公众开放。本文解读评估结果及其对AI安全行业的深远影响。
阅读全文 →
 科技前沿
科技前沿·2 分钟
英国AI安全研究所评估GPT-5.5网络安全能力
阅读全文 →
科技前沿
英国AI安全研究所评估GPT-5.5网络安全能力
·2 分钟
英国AI安全研究所评估GPT-5.5网络安全能力
阅读全文 →

