Agent Harness: The Paradigm Leap from Prompt Engineering to Harness Engineering

How Agent Harness introduces loop-based execution to solve context loss and transform AI coding agents.
This article traces the evolution from Prompt Engineering through Context Engineering to the emerging paradigm of Harness Engineering. It explains how iterative loop architectures with fresh context per cycle fundamentally solve the context summarization and information loss problems that plague long-running AI coding agents, enabling a shift from manual oversight to fully automated software development workflows.
Introduction: A Confusing Yet Crucial Concept
"Agent Harness" — since this term was formally introduced, the confusion surrounding it has yet to dissipate. Many people simply interpret it as "the runtime environment for agents," but that falls far short of explaining its true nature. From Prompt Engineering to Context Engineering, and now to Harness Engineering, the AI programming field is undergoing a profound paradigm shift.
Based on an in-depth analysis by Bilibili creator Caleb Wright, this article systematically traces this evolutionary trajectory to help you truly understand why Agent Harness is considered something that will "change everything."
From 4,000 Tokens to Infinite Possibilities: The Evolution of Three Engineering Paradigms
First Generation: The Limitations of Prompt Engineering
When ChatGPT launched in 2022, we were dealing with a context window of just 4,000 tokens. To understand this, you need to grasp a fundamental concept: tokens are the basic units that large language models use to process text — one English word typically corresponds to 1–2 tokens, while one Chinese character usually maps to 1–2 tokens. The context window is the maximum total number of tokens a model can "see" and process in a single interaction. GPT-3.5 launched with support for only 4,096 tokens (roughly 3,000 English words), meaning the model's "working memory" was extremely limited — equivalent to an engineer who can only see two or three pages of content at a time. By 2024, mainstream models had expanded their context windows to 128K or even 200K tokens, but even so, context space remains a scarce resource for complex software engineering tasks.
Within this extremely limited space, simple prompt engineering could only accomplish very basic tasks — like asking AI to generate a webpage, which would typically result in an "embarrassingly crude" page, because the model could only produce a one-shot response and couldn't handle any complex logic.
This limitation gave rise to a core question: How can we more efficiently utilize and manage the limited context window?
Second Generation: The Rise and Bottleneck of Context Engineering
To break through the ceiling of prompt engineering, the industry rapidly developed Context Engineering, built on three core pillars:
- Tool Calling: Enables the model to explore code repositories, read only files relevant to the current task, and execute operations externally
- MCP (Model Context Protocol): Allows vendor-specific capabilities to be layered on top of the model. MCP is an open protocol standard released by Anthropic in late 2024, designed to establish a unified communication interface between AI models and external data sources and tools. Before MCP, every AI application needed custom integration code for different data sources and tools, resulting in massive duplication of effort and compatibility issues. MCP uses a client-server architecture communicating via the standardized JSON-RPC protocol, enabling any MCP-compatible AI application to plug-and-play with various external services — similar to how the USB protocol unified hardware device connections.
- RAG (Retrieval-Augmented Generation): Connects to custom databases, making on-demand data readily available. RAG's core idea is to retrieve the most relevant document fragments from an external knowledge base before the model generates an answer, then inject those fragments as context into the model's prompt. This process typically relies on vector databases (such as Pinecone, Weaviate) and embedding models to achieve semantic-level similarity matching. RAG's advantage is that it lets models access the latest information beyond their training data while significantly reducing the probability of model "hallucinations" (generating false information).

Early coding agents like Cursor, Windsurf, Kline, Roo, and Aider all adopted tool calling to implement context engineering, and they were genuinely "good tools that get the job done." As underlying models evolved and context windows grew, coding agents began handling longer-running tasks, and people started demanding they complete increasingly large-scale feature development and bug fixes.
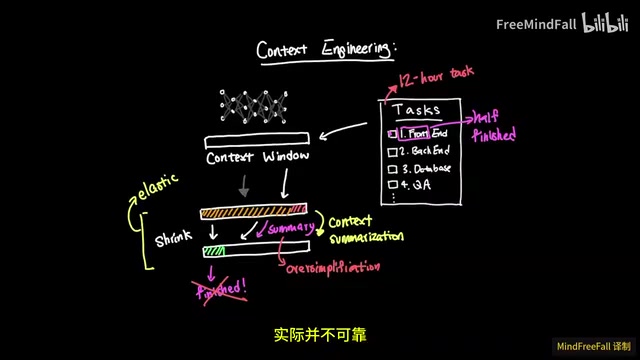
But problems followed. When task complexity and duration exceeded a certain threshold, context engineering revealed a fatal flaw: information loss caused by context summarization.
Specifically, when a task takes 12 hours to complete, the context window keeps filling up. To continue working, the agent summarizes and compresses existing context. Context summarization is essentially lossy compression — the model must judge which information is "important" and which can be discarded, and these judgments are often inaccurate. In software development scenarios especially, a seemingly unimportant variable naming convention or API call detail might be critical in subsequent steps, and once discarded through summarization, it can trigger cascading errors. During this process, the agent might:
- Summarize midway through a task, then incorrectly conclude the task is already complete
- Over-simplify the task description, assuming certain features have been completed and verified when they haven't
- Produce a half-finished website — with some buttons not working and features not fully tested
This approach of an "elastic self-managing context window" appears to give agents the ability to handle long-running tasks, but the actual results fall far short of expectations.
The Birth of Harness Engineering: The Power of Loops
The Critical Step from Chaos to Order
Facing the bottleneck of context engineering, the industry was already spontaneously exploring solutions: some implemented hierarchical context management with sub-agents, others deployed multi-agent swarms, each with its own independent context window. The concept of multi-agent swarms originates from distributed systems and swarm intelligence theory. OpenAI released an experimental framework called Swarm in 2024, demonstrating the possibility of multiple AI agents working collaboratively. In a Swarm architecture, each agent has its own independent context window, independent system prompt, and independent toolset, passing tasks between agents through a "handoff" mechanism. This design draws inspiration from microservices architecture — rather than building a monolithic application that does everything, multiple small services focused on specific responsibilities collaborate to complete complex tasks.
All these attempts were converging in the same direction — building better orchestration layers, execution environments, and context management mechanisms for underlying agents.
The formal introduction of the term "Agent Harness" marked the moment this direction got a unified name. While some dismiss it as just another industry buzzword, it genuinely captures a transformative essence of what's happening in the AI industry.
Core Mechanism: Iterative Loops + Fresh Context
The most critical innovation of Harness Engineering is the introduction of loops. Here's how it works:
- Planning Phase: Break down a large requirement into a structured task document (such as a PRD — Product Requirements Document), then refine it into a JSON-formatted task list. A PRD is a standard document in software engineering used to describe product features, user stories, and acceptance criteria. In the context of Harness Engineering, the PRD serves as the agent's "North Star" — providing a global view and clear completion criteria for the entire development task. Further refining the PRD into a JSON-formatted task list enables machines to precisely parse each subtask's dependencies, priorities, and completion conditions. This approach borrows from the agile development concepts of "user story splitting" and "Sprint Backlog," but hands the role of human project manager over to an AI planner.
- Loop Execution: In each iteration, the agent selects only one task from the document to complete
- Fresh Context: At the start of each iteration, the agent receives a completely new prompt and fresh context, rather than continuing to work on an ever-expanding old context
- Testing and Documentation: After each step is completed, testing and documentation are performed
- Continuous Looping: Until all tasks are fully completed
The elegance of this architecture lies in how it fundamentally solves the information loss problem caused by context summarization — because each iteration starts from a clean slate, the agent no longer needs to "remember" all previous work details; it only needs to know which specific task to complete right now. This mirrors the "Stateless Service" design philosophy in computer science: externalize state storage (in this case, task documents and code repositories), keeping each execution lightweight and predictable.
Roo's Successful Validation
Roo is the most representative success story of this architecture, having "swept across the entire internet" — not just because of its impressive results, but because of the extreme simplicity of its underlying architecture. Looking at Roo's documentation, the entire workflow is: create a PRD → output a JSON task file → loop through feature implementation. When you examine its code repository, you'll be surprised by how small the entire project is.
Anthropic's simple demonstration of Harness follows the same pattern — a lightweight, clean environment. The simpler the architecture, the more powerful the results — and this itself speaks to the power of a paradigm shift.
Harness and Its Predecessors: Layering, Not Replacing
A common misconception is that Harness Engineering will replace prompt engineering and context engineering. The truth is exactly the opposite.
If you dig into the source code of open-source coding agents like Kline, you'll find that their system prompts are still driven by carefully crafted prompt text. The relationship between the three engineering layers is:
- Prompt Engineering: Tells the agent "who you are" — assigns it the role and behavioral guidelines of a coding agent; this is the foundational component
- Context Engineering: Manages "what the agent knows" — controls information flow through tool calling, MCP, RAG, and other technologies
- Harness Engineering: Defines "how the agent works" — builds the loop execution environment, orchestrates task workflows, and manages iteration cadence
Harness Engineering is a higher-level abstraction built on top of the first two. It effectively leverages the capabilities of prompt engineering and context engineering, but shifts the focus from "how to write a good prompt" or "how to manage context well" to "how to build the optimal execution environment for agents." This layered architecture is highly consistent with classic patterns in software engineering — just as an operating system doesn't replace the CPU instruction set, but provides more efficient resource management and task scheduling on top of it.
Practical Application: The Evolution from Manual to Fully Automated
Using Cursor as an example, we can see the gradual embodiment of Harness thinking in real products:
- Local Agent: Launch Cursor locally and have the agent update website information
- Concurrent Agents: Spawn multiple agents simultaneously, each with independent context, concurrently fixing different features
- Cloud Agent: Push tasks to the cloud for execution; after closing local Cursor, tasks continue running and automatically create a Pull Request upon completion. A Pull Request (PR) is a collaboration mechanism in modern software development based on the Git version control system — after a developer completes code changes on an independent branch, they create a PR requesting the code be merged into the main branch, where other team members can conduct code reviews. When a cloud agent automatically creates a PR, it effectively simulates a complete developer workflow: creating a branch, writing code, running tests, committing changes, and initiating a merge request. Combined with CI/CD (Continuous Integration/Continuous Deployment) pipelines, AI-generated code can go through the same quality gates as human-written code, including automated testing, code style checks, and security scanning.
- Integrated Automation: Send feature requests via Slack, and cloud agents automatically execute and notify upon completion
- Fully Automated Operation: Set up cloud automation tasks to check for new model releases daily and automatically keep website information up to date
This progression from manual to fully automated is a quintessential scenario empowered by Harness Engineering — the agent is no longer a tool you need to watch over while it works, but a "digital employee" that can autonomously operate within a structured environment.
Why Harness Will Change Everything
Today, an increasing number of coding agent companies have directly integrated the Harness layer into their products, though implementations vary across vendors. Behind this trend lies a simple yet profound truth: When you stop trying to make a single agent complete everything within one massive context, and instead build a structured loop execution environment for it, the results improve by an order of magnitude.
The true value of Harness Engineering lies not in any specific technical breakthrough, but in the mindset shift it represents — from "how to make AI smarter" to "how to build a better working environment for AI." This parallels the logic of human engineering management: an excellent engineer will perform mediocrely in a chaotic environment, while a well-designed workflow can enable an average engineer to produce excellent results. This insight also echoes a classic observation from software engineering — Fred Brooks argued in The Mythical Man-Month that the core difficulty of software development lies not in coding itself, but in conceptual integrity and system architecture design. Harness Engineering applies this wisdom to the management of AI agents.
For AI practitioners, understanding and mastering Harness Engineering may be one of the most worthwhile skills to invest in right now.
Key Takeaways
Related articles
Trae Hands-On Tutorial: Build a Full-Stack Website with Just 3 Prompts
Learn how to use ByteDance's AI coding tool Trae to build a full-stack website with just 3 prompts—covering frontend, backend API, and admin panel.
AI Progress Demands a More Nuanced Examination: A Rational Framework Beyond Hype and Panic
Current AI discourse is trapped in polarization. This article explores how to rationally assess AI's real progress, analyzes the gap between benchmarks and actual capabilities, and offers a pragmatic evaluation framework.
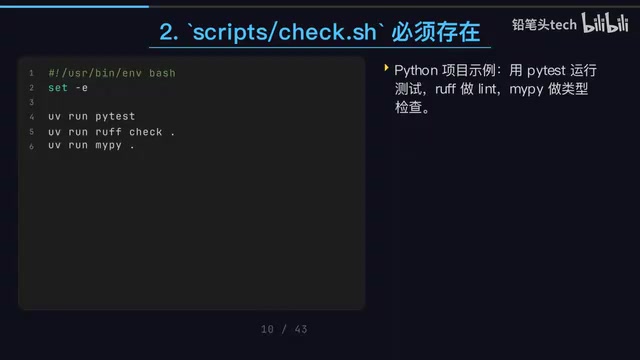
Codex + Claude Code Dual-AI Collaboration: An Engineering Approach to Write-and-Review
A detailed guide to Codex CLI and Claude Code collaboration: write-and-review pattern, file-driven workflows, unified check scripts, and Git Worktree parallelism.