Anthropic's 400,000 AI Coding Sessions Reveal: Domain Expertise Is What Really Matters

Anthropic's 400K-session study proves domain expertise, not coding skill, drives AI coding success.
Anthropic analyzed 400,000 Claude Code sessions across 235,000 users over 7 months and found that domain expertise — not programming ability — is the key factor in AI coding effectiveness. Humans make 70% of planning decisions while AI handles 80% of execution. Expert users generate 5x more output than novices, and the biggest productivity leap comes from moving from novice to basic competence. Non-technical professions like management, sales, and legal are the fastest-growing user segments.
Anthropic has just released a large-scale research report based on Claude Code, covering 400,000 interaction sessions, 235,000 users, and a full 7 months of data. The conclusion directly overturns a deeply entrenched assumption — you need to know how to code to use AI effectively. What truly determines whether you can use AI coding tools well has never been coding ability — it's the depth of your domain understanding of the problem you're solving.
AI Coding Has Become a Productivity Norm
The data in this study spans from October 2024 to April 2025. The number of projects with Coding Agent activity on GitHub has more than doubled since the end of last year, and Claude Code users average 20 hours of use per week — this isn't occasional experimentation, but full adoption as a core productivity tool.
It's important to understand the fundamental difference between Claude Code and traditional code completion tools. Claude Code is Anthropic's command-line AI coding tool where users interact with the Claude model through natural language in the terminal to write, debug, and refactor code. Unlike GitHub Copilot's Tab completion, Claude Code is a Coding Agent with autonomous action capabilities — it can read files, execute commands, run tests, and modify multiple files on its own, forming a complete workflow loop. A Coding Agent refers to an AI system that can autonomously plan steps, invoke tools, and iteratively execute after being given a goal, rather than merely responding passively to individual requests.
The research team categorized each interaction session into 9 work modes: writing new code, fixing bugs, running tests, orchestrating pipelines, deployment and operations, understanding existing systems, planning changes, analyzing data, and writing documentation. The data shows that 56% of sessions involve pure code-related work (writing new features, fixing bugs, running tests), operations account for 17%, planning and exploration 14%, and analysis and documentation 13%.
What you might not have noticed is that nearly 1% of sessions produce outputs that aren't code at all. Claude Code is evolving from a coding tool into a general-purpose knowledge work platform.
The Truth About Human-AI Division of Labor: Humans Decide, AI Executes
One of the most central findings in the research concerns the decision-making division between humans and AI. The team built a Decision Attribution Classifier that categorizes all decisions in each session into two types:
- Planning decisions: What to do, which approach to use, what counts as done
- Execution decisions: Which file to modify, what code to write, which command to run
This classification method draws on the "locus of control analysis" approach from Human-Computer Interaction (HCI): during a collaborative process, whenever a directional choice (such as which technical approach to use, whether refactoring is needed) or an operational choice (such as which file to modify, which API to use) arises, the classifier determines the initiator of that decision based on context. The distinction between planning and execution decisions essentially corresponds to the classic division between "strategic" and "tactical" levels in management theory.

The answer is crystal clear: humans make 70% of planning decisions, while Claude makes 80% of execution decisions. A typical session involves about four rounds of interaction, where the user sends one prompt per round, and Claude triggers an average of 10 actions (sometimes over 100), producing approximately 2,400 English words per round. This is why such high action counts appear in the study — each action is an autonomous tool invocation by the Agent, including reading files, searching the codebase, executing terminal commands, writing files, and more.
What's even more interesting is that this number directly correlates with control. When humans retain execution control, Claude performs about 8 actions per round; when Claude takes over planning, it performs 16 per round.
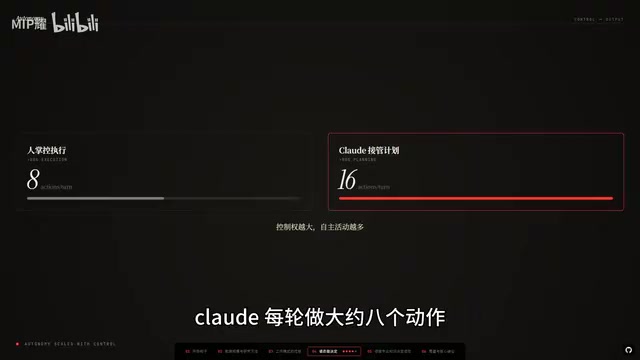
More control means more autonomous activity. You decide what to do, AI decides how to do it — this is the most efficient human-AI collaboration model today. This finding provides data-backed proof of an important conclusion: optimal human-AI collaboration isn't "humans write pseudocode, AI translates it into real code," but rather "humans define the problem and acceptance criteria, AI autonomously handles all implementation details."
Significant Shifts in User Work Composition Over 7 Months
Over these 7 months, user work composition changed significantly:
- Bug fixing dropped from 33% to 19%, nearly halving
- Operations rose from 14% to 21%
- Documentation and data analysis grew from 10% to 20%, nearly doubling
The research team also estimated the economic value of each task by comparing it with task pricing on freelance marketplaces (such as Upwork, Fiverr, and similar platforms). This method is known as "market replacement" — if the same task would cost a certain amount to have a freelancer complete, then AI-assisted completion of that task creates corresponding economic value. While this estimation framework doesn't account for quality differences and iteration costs, it provides a quantifiable reference benchmark.
The average value per task increased by 27%, with build tasks up 43%, operations tasks up 34%, and bug-fixing tasks up 32%.
People are shifting from "patching things up" to "end-to-end delivery" — deploying, running pipelines, writing reports. The work completed with AI is becoming increasingly complete and valuable. The 27% increase in task value is particularly noteworthy — it shows that users aren't simply using AI to do more homogeneous simple tasks, but are gradually taking on more complex, more complete, and higher-value work.
Expertise Is Task-Level, Not Person-Level
This is the most paradigm-shifting part of the entire study. The team scored each user's expertise level (five tiers), but the scoring criteria weren't based on job titles — they looked at actual capability on specific tasks. Scoring was based on three signals:
- How precise your instructions are
- What you ask Claude to verify
- Whether you correct Claude, or Claude corrects you
Two examples: A senior engineer asking about REST APIs for the first time is a novice on the REST task. REST API (Representational State Transfer Application Programming Interface) is the most mainstream interface design style for today's web services, proposed by Roy Fielding in his 2000 doctoral dissertation. It operates on resources through standard HTTP methods like GET, POST, PUT, and DELETE. Even experienced developers exhibit novice characteristics when facing unfamiliar technical domains — vague instructions, inability to effectively verify AI output, and susceptibility to being misled by AI's incorrect responses.
Another example: An accountant who has never written Python, but who clearly knows exactly which reconciliation rules the script must execute — on this task, they're the expert.
This aligns closely with the cognitive science theory of "domain specificity of expertise": chess grandmasters' memory advantage only exists for meaningful board positions — when faced with randomly placed pieces, their performance is no different from novices. Similarly, in the context of AI coding, your expertise doesn't depend on how many programming languages you know, but on the depth of your understanding of the domain the current task belongs to.
Expertise is task-level, not person-level. You might be an expert in one domain and a complete novice in another.
The data gap is staggering: expert users trigger more than twice as many Claude actions per instruction as novices, with five times the output (12 actions vs. 5, 3,200 words vs. 600). And after controlling for work mode, task value, month, occupation, and model family, this gap remains significant.
Who's Using AI Coding? Non-Technical Professions Are Growing Fastest
The research team used a clever method to infer user occupations — rather than labeling anyone who writes code as a programmer, they examined project context, file structure, referenced materials, and terminology used.
Computer and mathematical occupations are indeed the largest group, but the second-largest group is business and financial operations, followed by arts, design, and media, then management. The fastest-growing occupation categories are: management, sales, and legal. Adoption among non-software professions is accelerating.
The logic behind this trend is clear: when AI Agents can autonomously handle all the details of code implementation, "whether you can write code" is no longer the barrier to entry. The real barrier becomes "can you clearly describe the problem you want to solve." A lawyer understands contract review logic better than any programmer, and a sales manager knows how CRM data should be analyzed for business insights better than any data engineer. AI coding tools are essentially converting "domain knowledge" directly into "executable software" — programming languages are no longer a required intermediate layer.
From Novice to Beginner: The Highest-Return Leap
The study defined two success metrics:
- Strict success: Hard evidence that the task was completed (e.g., tests passed, program ran successfully, verifiable results produced)
- At least partial success: The session produced something useful (e.g., generated referenceable code snippets, provided valuable analytical insights)
Results:
| Expertise Level | Strict Success Rate | At Least Partial Success Rate |
|---|---|---|
| Novice | 15% | 77% |
| Intermediate and above | 28%-33% | 91%-92% |
The gap widens when difficulties arise: only 4% of novices ultimately succeed, compared to 15% for experts — nearly a 4x difference. Even more sobering is the abandonment rate — 19% of novices give up after encountering difficulties, while only 5%-7% of others do. Novices are far more likely to abandon ship during struggles.
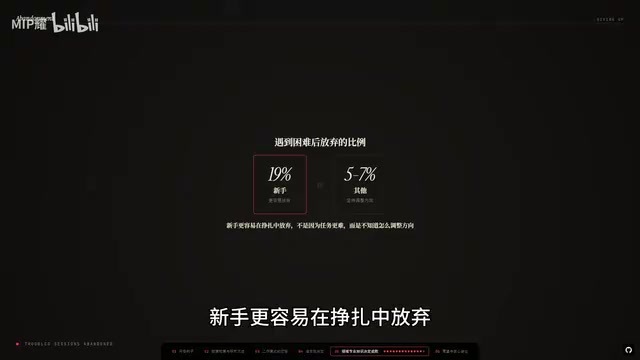
The highest-return leap is from novice to beginner. This is the most critical step. You don't need mastery — you need competence. Having a basic grasp of the domain is enough to capture most of the benefits. "Competence" here means you can at least do three things: give instructions specific enough for AI to understand your intent, know which key points to verify to ensure output quality, and identify and correct AI mistakes when they occur. All three capabilities come from domain knowledge, not programming skills.
Core Takeaway: Future Competitiveness Lies in Domain Understanding
The core conclusions of this research can be summarized as follows:
- AI coding tools are making programming backgrounds less important. The ability to direct AI Agents comes from domain expertise, not coding ability.
- A lawyer who understands contract law can now build tools they never could before, and an accountant who knows reconciliation rules can now write scripts that actually work.
- Most of the gains come from "competence" rather than "mastery." You don't need to be world-class — you just need to know what you're doing.
Of course, it's important to stay clear-eyed. The research team themselves pointed out limitations: they cannot observe real-world outcomes (whether the code written was actually used or discarded), and this data only covers interactive usage — non-interactive headless mode was entirely excluded from the statistics. Headless mode refers to scenarios where Claude Code runs autonomously without real-time human participation. Typical applications include automated code review in CI/CD (Continuous Integration/Continuous Deployment) pipelines, automatic handling of GitHub Issues, and automatic generation of Pull Requests. In this mode, the AI Agent independently completes tasks based on preset trigger conditions and instruction templates, with humans only intervening at the final review stage. This means the report's data may underestimate the actual usage scale and impact of AI coding tools.
But the trend is already crystal clear: the future of knowledge work competition isn't about who can write code, but about who truly understands the problem they're solving. If you have solid understanding in a domain, AI is your most powerful lever.
Related articles

Costco's Business Model Explained: You Serve Whoever Pays You
Deep dive into Costco's business flywheel: only 14% gross margin yet profitable through membership fees, streamlined SKUs for lower prices, and a 92% renewal rate as a built-in braking system.
Japan's Ride-Hailing Platform Go Completes ¥88.6 Billion IPO, Betting on Robotaxis to Tackle Driver Shortage
Japan's ride-hailing app Go completed the country's largest IPO this year, raising ¥88.6 billion. Facing a severe driver shortage, Go is investing in Robotaxis and industry M&A to reshape Japan's mobility future.

Claude Code + Firecrawl MCP Tutorial: One-Click Install with No Registration or API Key
Complete guide to connecting Firecrawl MCP to Claude Code with no registration or API Key. Get 1,000 free monthly searches to boost your coding productivity.