ARS Framework from Shanghai Jiao Tong University: Enabling Automated AI Research with Trustworthy Conclusions
Shanghai Jiao Tong University's ARS framework makes autonomous AI research trustworthy and verifiable.
Shanghai Jiao Tong University's ARS (Auto Research in Sleep) framework addresses two critical flaws in autonomous AI research: self-evaluation bias from shared generation-review models, and trustworthiness issues in prolonged unsupervised operation. By separating generation from verification, building evidence chain traceability, and supporting auditable autonomous runs, ARS enables reliable human-AI collaboration. Papers completed using ARS have already been accepted at academic conferences.
When AI Agents can already run the entire pipeline from inspiration to paper, a more critical question emerges: How do we know the AI isn't quietly fabricating its conclusions? The ARS (Auto Research in Sleep) framework proposed by the Shanghai Jiao Tong University team was born precisely to solve this trust problem.
Two Fatal Flaws in Autonomous AI Research
The capabilities of autonomous research Agents are already impressive — a researcher can go to sleep and wake up to find the AI has finished running experiments and even produced a decent-looking paper. But beneath this polished surface, current Agent systems still suffer from two critical problems.
First, the problem of shared origins between generation and review. In many systems, content generation and content review are performed by the same model architecture. It's like having a student write the exam questions, answer them, and grade them all by themselves — many systematic errors are therefore difficult to expose internally. The model's inherent biases and hallucinations get continuously reinforced rather than corrected within this closed generation-review loop.
This problem is known in the AI safety field as "self-evaluation bias," rooted in the inherent consistency of large language models' training data and reasoning patterns. When the same model both generates and reviews content, it tends to consider its own output reasonable — because generation and review share the same knowledge representations and reasoning pathways. This aligns with the software engineering principle that "code reviews should not be conducted solely by the original author." In traditional research, the core value of the peer review system is precisely to introduce external perspectives to break this cognitive closed loop. The "hallucination" mentioned here refers to large language models generating content that appears plausible but is actually incorrect or lacks factual basis. This phenomenon stems from the model's fundamental nature — it is a probability-based text generator whose optimization objective is to produce "the most likely next token" rather than "the most correct next token." In research contexts, hallucinations are especially dangerous: models may fabricate nonexistent references, invent experimental data, or produce incorrect but plausible-looking numbers in statistical analyses.
Second, the trustworthiness problem of prolonged unsupervised operation. When an Agent works continuously for days with virtually no human oversight, its final conclusions are often difficult to assess for adequate evidential support. The longer the intermediate reasoning chain, the greater the risk of error accumulation, and the final paper may appear logically coherent while actually being built on fabricated experimental results.
This error accumulation phenomenon is known in complex systems theory as "cascading failure." In traditional software systems, long-chain automated processes typically include multiple checkpoints and assertions to prevent error propagation. But in an AI Agent's reasoning chain, since each step's output is natural language rather than structured data, error detection and interception become particularly difficult — a seemingly reasonable intermediate conclusion may have already deviated from the facts, yet gets unconditionally accepted by subsequent steps due to the fluency of its language expression.
Both problems point in the same direction: The bottleneck in AI research isn't speed — it's verifiability.
Core Design of the ARS Framework: The Focus Isn't Speed, but Reliability
To address these issues, the Shanghai Jiao Tong University team proposed "Auto Research in Sleep" (ARS), an open-source research harness for automated scientific research.
The design philosophy of this work is crystal clear: The focus isn't on making AI write papers faster, but on making the papers AI writes more resilient to scrutiny. This philosophy stands out as particularly clear-headed amid the current wave of AI research tools universally pursuing "end-to-end automation."
The core design principles of ARS can be understood from several dimensions:
-
Separating generation and verification: By introducing independent review mechanisms, the system avoids the problem of a single model "talking to itself," making systematic errors easier to expose. This design draws on the concept of adversarial verification — by introducing review models with different bias characteristics from the generation model, blind spots of any single model become easier to detect. A similar idea appears in game theory: when participants' interests are not perfectly aligned, the system is more likely to converge toward a truthful equilibrium.
-
Building evidence chain traceability: Ensuring that every step leading to the final conclusion has traceable experimental evidence, rather than relying solely on the model's "confidence." This mechanism borrows the concept of "auditability" from software engineering. In traditional research, the lab notebook serves a similar function — every conclusion must be traceable to specific experimental data and procedural steps. In the context of AI research Agents, this means the system needs to record every API call, every code execution's inputs and outputs, and every literature search result, forming a complete decision log. This shares common ground with the blockchain concept of "immutable records," with the core goal of making post-hoc auditing possible.
-
Supporting prolonged autonomous operation: During a researcher's sleep, the Agent can continue working, but its output maintains post-hoc auditability. This means that when researchers wake up, they can not only see the final results but also trace back through every critical decision node in the entire research process, judging where the AI made correct choices and where biases may have crept in.
This approach of "trustworthy automation" is far more pragmatic than simply pursuing full-pipeline automation. After all, a paper that looks perfect but has unreliable conclusions may cause far more harm than no paper at all.
Community Validation: Papers Already Accepted at Academic Conferences
Notably, ARS hasn't remained at the conceptual stage. In community case studies, researchers have used ARS to complete the full pipeline of their respective papers, which were then accepted at academic conferences.
This point is crucial. The AI research tools space is flooded with demos and proofs of concept, but only results that have withstood peer review scrutiny are truly convincing. Peer review at academic conferences is the core quality control mechanism for research output — a paper being accepted at a conference typically means it has undergone independent review by 2-4 domain experts, who evaluate it across multiple dimensions including research motivation, methodological rigor, experimental design, reproducibility, and writing quality. Top AI conferences (such as NeurIPS, ICML, ICLR, etc.) typically have acceptance rates between 20%-30%, meaning most submitted papers are rejected. Therefore, the fact that papers completed with ARS assistance can pass through this selection mechanism is strong evidence of its output quality.
Being accepted at a conference means:
- Research produced with ARS assistance is methodologically sound enough to withstand reviewer scrutiny
- Experimental results are reproducible and credible
- Overall paper quality meets the threshold for academic publication
This provides the most powerful endorsement of ARS's practical utility.
A Look at the Full-Pipeline AI Research Tool Ecosystem
Beyond ARS, the current ecosystem of autonomous AI research tools is already quite rich. Multiple projects from top global institutions including Microsoft, ByteDance, Alibaba, and Stanford cover various stages of the research process.
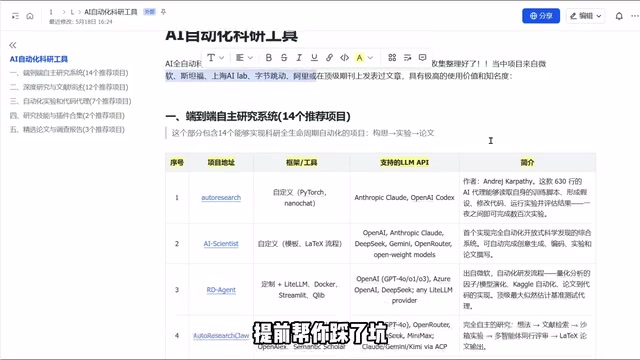
The current tech stack for AI research tools is typically built on several key components: large language models (such as GPT-4, Claude, etc.) provide natural language understanding and generation capabilities; Retrieval-Augmented Generation (RAG) technology enables models to access up-to-date academic literature databases (such as Semantic Scholar, arXiv), effectively mitigating the model's knowledge cutoff limitations; Code Interpreters allow models to write and execute Python code for data analysis and experiments; and Agent frameworks (such as LangChain, AutoGen, etc.) orchestrate these capabilities into autonomously executable workflows. The maturity of these components directly determines the capability ceiling of AI research tools.
From a functional perspective, these tools can already cover the complete research chain:
- Research direction exploration: Automatically discovering research gaps and potential directions based on literature analysis. This typically relies on semantic analysis and knowledge graph construction from large volumes of papers, identifying unexplored research questions by detecting "structural holes" in the literature network.
- Literature review: Automatically searching, filtering, and summarizing relevant literature. Modern literature review tools typically combine keyword search and semantic search — the former is precise but may miss related work, while the latter has broader coverage but may introduce noise; using both complementarily yields the best results.
- Code generation and experiment execution: Automatically writing and running experimental code. The key challenge in this stage is environment configuration and dependency management — the AI needs not only to write correct code but also to handle various library version conflicts, GPU resource allocation, and other engineering issues.
- Paper writing: Generating complete articles with citations, supporting LaTeX formatting.
However, it's important to note that tool abundance doesn't mean they can be used mindlessly. When choosing AI research tools, several key indicators deserve attention: whether there is real community usage feedback, whether it is open-source and auditable, and whether there are mechanisms to ensure result trustworthiness. This is precisely where ARS differentiates itself from many similar tools.
A Sober Perspective: Where Are the Boundaries of AI Research Capabilities?
Despite ARS's important improvements in trustworthiness, we still need to maintain a rational understanding of autonomous AI research.
What AI excels at: Large-scale literature retrieval, experimental parameter search, code implementation, formatted writing, and other highly structured tasks. In these areas, AI's efficiency advantage is hard for humans to match. Take experimental parameter search as an example: a researcher might need weeks to manually adjust hyperparameter combinations, while an AI Agent can systematically traverse hundreds of configurations and record results within hours — this "brute-force search" capability is AI's most direct value proposition.
Where AI remains weak: Proposing truly original research questions, providing deep causal explanations of experimental results, and judging the social significance and ethical boundaries of research. These capabilities requiring domain intuition and value judgment remain the irreplaceable core competencies of human researchers. Research in cognitive science shows that human creative thinking often stems from cross-domain analogical reasoning and keen sensitivity to "anomalous phenomena" — abilities that depend on researchers' long-accumulated tacit knowledge rather than explicit knowledge that can be directly extracted from literature. While current large language models excel at pattern matching and knowledge combination, they still have clear limitations in genuine "zero-to-one" innovation.
The value of ARS lies in the fact that it doesn't attempt to completely replace researchers with AI. Instead, it builds a trustworthy human-AI collaboration framework — AI handles execution and preliminary verification, while humans handle direction-setting and final review. This model is known in academia as "Human-in-the-Loop" (HITL), with theoretical foundations traceable to the concept of "complementary intelligence" in cognitive science. Research shows that humans and AI have significantly complementary cognitive capabilities: AI excels at processing large-scale data, maintaining consistency, and tirelessly executing repetitive tasks, while humans excel at abstract reasoning, creative thinking, and value judgment. The optimal human-AI collaboration model isn't simply "AI generates, humans review," but rather dynamically adjusting the human-AI division of labor at different research stages — granting AI greater autonomy during literature retrieval and experiment execution, while requiring deep human involvement during problem definition and result interpretation.
This division of labor may be the right way to approach AI research tools.
For researchers looking to try AI-assisted research, ARS offers a starting point worth paying attention to: it can not only help advance your research while you sleep, but more importantly, when you wake up, you can trust the results it delivers.
Related articles

CodeGraph: The 50K-Star Open-Source Tool That Cuts AI Coding Token Usage in Half
CodeGraph is a 50K-star open-source tool that builds a code knowledge graph so AI coding assistants can locate code instantly—cutting Token usage by 47%, boosting speed by 22%, all running 100% locally.

VibeCoding Beginner's Guide: A Complete Guide to Building Software with Natural Language from Scratch
VibeCoding lets anyone build software through natural language conversations with AI. Learn the core concepts, learning path, and practical methods to get started.
Using UU Accelerator to Speed Up Cursor: A Compliant Solution for Stable AI Coding in China
Learn how to use NetEase UU Accelerator to speed up Cursor AI coding tool in China, with step-by-step setup including node selection and launch configuration.