Claude Fable User Guide: Four Core Tips to Boost AI Development Efficiency
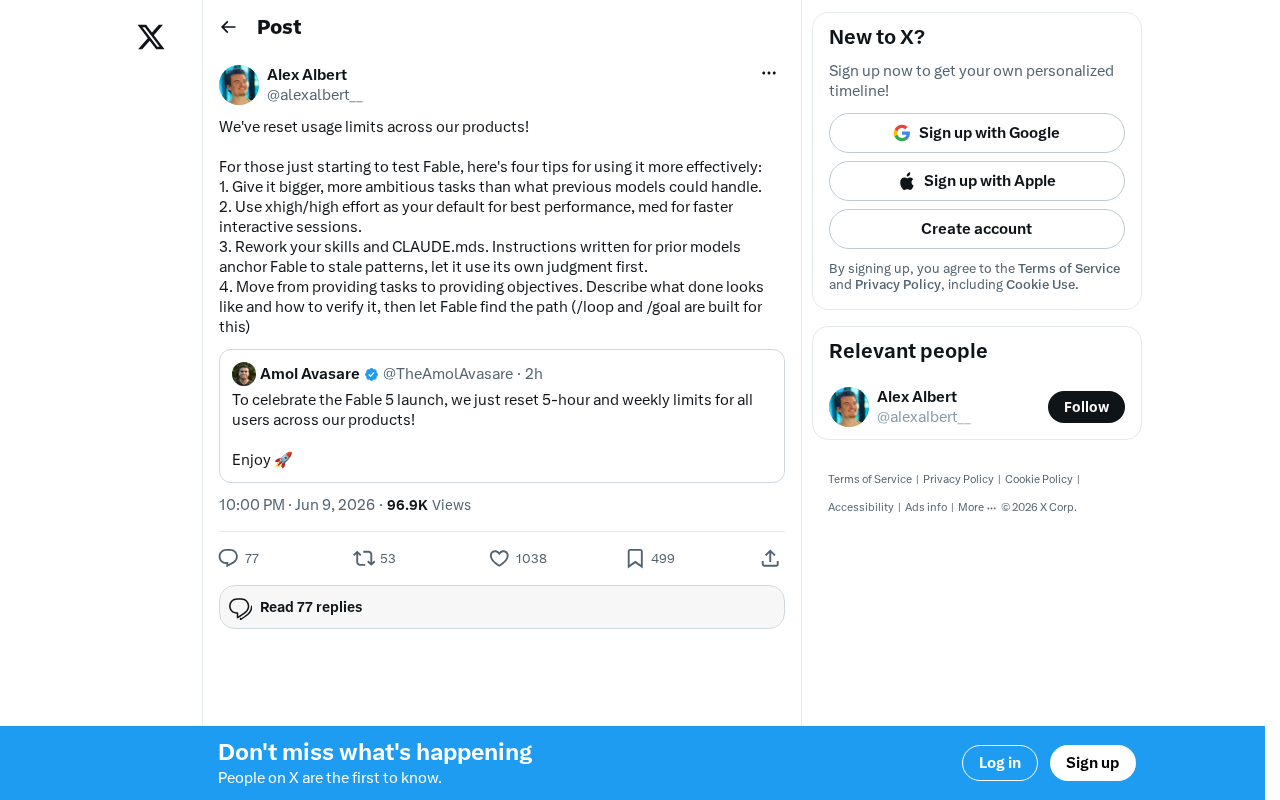
Four official tips from Anthropic to unlock Claude Fable's full development potential.
Anthropic reset usage limits and shared four core tips for Claude Fable: assign bigger and more ambitious tasks, choose the right effort level for performance-speed balance, rewrite old Skills and CLAUDE.md configs to avoid anchoring the model to outdated patterns, and shift from task-oriented to goal-oriented prompting using /goal and /loop commands. These tips signal a fundamental paradigm shift in AI-assisted development.
Anthropic Resets Usage Limits, Sparking a New Wave of Fable Model Testing
Anthropic recently announced a reset of its usage limits, opening the door for more users to test its latest model, Claude Fable. At the same time, the company shared four key usage recommendations to help developers get the most out of Fable's capabilities. These tips go beyond simple operational tricks — they reveal a fundamental shift in how the next generation of AI models should be used.
Anthropic's usage limits are a common quota management mechanism across its API and consumer products. For API users, limits are typically measured in requests per minute (RPM) and token consumption per minute or per day. For Claude Pro subscribers, they manifest as periodic caps on conversation or message counts. This reset means all users' quotas have returned to their initial state — something that typically happens during new model launches or major updates. The goal is to give as many users as possible a level playing field to experience new features, while also allowing Anthropic to collect broader real-world usage data.
Give It Bigger Tasks: Stop Limiting the New Model with Old Thinking
The first piece of official advice is straightforward: Assign Fable bigger, more ambitious tasks than you would with previous models.
This signals a significant leap in Fable's capability ceiling. When using earlier Claude models, users often developed the habit of breaking complex tasks into small steps and feeding them to the model one at a time, because older models tended to lose context or drift when handling long-chain, multi-step tasks. Fable has clearly been optimized in this regard — it's designed to handle more complex end-to-end tasks.
The tendency of older models to "lose context" is directly related to the size of the context window and the model's long-range dependency capabilities. The context window refers to the maximum number of tokens a model can process in a single inference pass. Early GPT-3.5 supported only 4K tokens, while the Claude 3 series expanded this to 200K tokens. But window size is only a necessary condition — the model's ability to accurately retrieve and correlate information within a long context (the so-called "needle in a haystack" capability) is equally critical. Fable's optimizations in this area likely involve more efficient attention mechanisms, improved positional encoding schemes, and specialized training data for long-chain reasoning. These underlying improvements enable the model to truly "remember" and "understand" the complete thread of a complex task from start to finish.
For developers, this is an important signal: don't self-impose limitations based on past experience. Try handing entire feature modules or even project-level tasks to Fable and see where its performance ceiling lies.
Choose the Right Effort Level: Balancing Performance and Speed
The second recommendation involves Fable's effort parameter settings — a key configuration for getting the most out of the model:
- xhigh/high effort: The default option, suitable for scenarios requiring the best output quality
- med effort: Suitable for fast interactive sessions, trading some quality for response speed
This tiered mechanism is fundamentally a trade-off between reasoning depth and response latency. The underlying mechanism of the effort parameter is closely tied to Chain-of-Thought (CoT) reasoning. When set to high/xhigh, the model generates more internal reasoning tokens (thinking tokens) — these aren't directly shown to the user but guide the model through deeper, step-by-step reasoning. This mechanism stems from the "inference-time compute scaling" concept popularized by OpenAI's o1 model: investing more computational resources during inference can significantly improve accuracy on complex tasks. Anthropic first introduced extended thinking in Claude 3.5 Sonnet, and Fable's effort tiers represent a further productization of this approach, giving users fine-grained control over the trade-off between reasoning depth and latency.
For tasks requiring deep thought — such as code generation, architecture design, and complex analysis — high effort allows the model to invest more "thinking time" and produce more precise results. For everyday conversations and rapid prototype validation, medium effort provides a smoother interactive experience.
Developers should flexibly switch effort levels based on the nature of the task, rather than using a one-size-fits-all setting.
Rewrite Your Skills and CLAUDE.md: Don't Let Old Instructions Hold You Back
This may be the most easily overlooked yet most critical of the four recommendations. The official guidance is clear: Instructions written for older models will anchor Fable to outdated patterns.
Many developers have accumulated extensive custom skills files and CLAUDE.md configurations while using Claude products. CLAUDE.md is a project-level configuration file designed by Anthropic for its coding assistant Claude Code, similar to Cursor's .cursorrules or GitHub Copilot's instruction files. Developers can define project tech stacks, coding standards, architectural constraints, and other contextual information within it, which the model references during every interaction. Skills are more granular capability modules that define the model's behavior patterns for specific tasks (such as code review or test generation). These configurations are essentially structured extensions of the system prompt.
These instructions may have worked well with older models, but for Fable they become constraints. The reason is that Fable has stronger autonomous judgment capabilities, and overly detailed step-by-step instructions create an "over-constraining" problem — the model is forced to follow suboptimal preset paths instead of leveraging its stronger internal reasoning abilities to find better solutions. It's like sending a detailed operations manual to a senior engineer — it actually limits their ability to make better judgments based on experience.
The official recommendation is: Let Fable use its own judgment to handle tasks first, then make targeted adjustments based on actual output. This "let go first, tighten later" strategy better unlocks the new model's potential.
From Assigning Tasks to Setting Goals: A Fundamental Paradigm Shift
The fourth recommendation represents a significant paradigm shift in AI-assisted development: Move from providing specific tasks to providing objectives.
This shift also reflects the evolution of Prompt Engineering as a discipline. Early prompt engineering emphasized precise instruction design — few-shot examples, format constraints, step decomposition, and other techniques. But as model capabilities have grown, the industry has gradually shifted toward an "intent alignment" approach: rather than telling the model how to do something, clearly communicate what you want. This parallels the transition from imperative to declarative programming in software engineering — SQL tells the database "what data I want" rather than "how to find the data," and React tells the browser "what the interface should look like" rather than "how to manipulate the DOM."
The specific approach involves three steps:
- Describe what "done" looks like — clearly define the desired state of the final deliverable
- Explain how to verify — provide criteria for judging whether the task was successful
- Let Fable find its own path — don't prescribe specific implementation steps
The official guidance also specifically mentions two built-in commands: /loop and /goal, designed for this goal-oriented workflow. /goal lets you set high-level objectives, while /loop allows the model to autonomously explore optimal paths through iteration. These two commands represent an important step in the evolution of AI tools from "single-turn Q&A" to "autonomous Agent." In the Agent paradigm, AI no longer passively waits for step-by-step instructions. Instead, it receives high-level goals and autonomously plans task decomposition, executes steps, evaluates results, and iterates corrections. This aligns with the ReAct (Reasoning + Acting) framework: the model alternates between reasoning and action, continuously adjusting its strategy based on environmental feedback. /goal sets the target state, while /loop implements the core Agent loop — observe, think, act, evaluate. In software engineering, this pattern is similar to setting OKRs (Objectives and Key Results) for a team rather than assigning specific work tickets, requiring the AI to have stronger planning and self-correction capabilities.
The essence of this shift is: developers go from being "commanders" to being "product managers" — you define requirements and acceptance criteria, and the AI handles planning the implementation path. For developers accustomed to hand-holding AI through every step, this requires a mental adjustment.
Summary: New Models Require New Thinking
The four usage recommendations for Claude Fable all convey the same core message: The capability boundaries of next-generation models have expanded, and users' approaches need to evolve accordingly. Don't drive a sports car the way you'd ride a bicycle — give it more room, greater autonomy, and broader objectives to truly unleash Fable's power.
From a broader perspective, these four recommendations reflect a critical inflection point the AI industry is experiencing: the pace of model capability improvement has outstripped the pace at which user habits are updating. When models evolve from "executors requiring precise instructions" to "collaborators capable of autonomous planning," the human-AI collaboration interface must be redesigned accordingly. This is not just a technical issue — it's a transformation at the organizational and workflow level.
For developers who are evaluating or just starting to use Fable, the recommendation is to begin with a real project of moderate complexity, test according to the four principles outlined above, and gradually build intuitive understanding of the new model's capability boundaries.
Related articles

Xiaomi MIMO vs. Huawei Pangu AI Strategy Comparison: The Android vs. iOS Battle of the Agent Era
Xiaomi releases open-source MIMO Code while Huawei enters the Agent era with Pangu. Compare their AI strategies: Xiaomi's Android-like open ecosystem vs. Huawei's iOS-like vertical integration.

What Is Google WebMCP? A Deep Dive into the New Standard for AI Agents to Directly Invoke Web Functionality
A deep dive into Google WebMCP (Web Model Context Protocol): how it works, its technical implementation, and use cases. Learn how WebMCP lets AI Agents directly invoke web tools.
AI Can't Kill Old-School Programming: Why Fundamentals Are Still a Developer's Moat
Vibe Coding is trending, but can it replace solid fundamentals? A deep analysis of why core principles, systems thinking, and knowledge frameworks remain a developer's moat in the AI era.