Complete Guide to LangChain 0.3: Module Architecture & Core Development in Practice
A comprehensive guide to LangChain 0.3's architecture, core modules, and development patterns.
This article provides a complete walkthrough of LangChain 0.3, covering its ecosystem modules (Core, Community, LangServe, LangSmith, LangGraph), message abstraction system, prompt templates, output parsers, and LCEL chain invocations. It explains how LangChain unifies different LLM APIs through adapter patterns, enables elegant pipeline composition via the Runnable interface, and supports production observability through LangSmith tracing.
Introduction
As the most mainstream framework for building LLM-powered applications, LangChain has now evolved to version 0.3. For engineers looking to systematically master AI application development, understanding LangChain's module architecture, core concepts, and development paradigms is essential. This article takes a panoramic view of the framework, diving deep into LangChain's module composition, message abstraction mechanisms, prompt templates, output parsers, and chain invocations — helping developers build a complete mental model.
LangChain Ecosystem Overview & Module Architecture
Core Module Composition
LangChain's ecosystem is not a single Python package but rather a complete system composed of multiple collaborating sub-modules:
- LangChain Core: The core library, containing LCEL (LangChain Expression Language) — an expression language that supports chain invocations, Callbacks, async processing, Streaming, and Batches. LCEL is a declarative programming paradigm officially introduced in LangChain 0.2, drawing design inspiration from Unix pipes and the combinator pattern in functional programming. Before LCEL, LangChain's chain invocations relied on explicit Chain classes (such as LLMChain and SequentialChain), resulting in verbose code with poor extensibility. LCEL overloads Python's
|operator (the__or__magic method), allowing developers to freely compose components like Prompt, Model, and Parser as if assembling building blocks. Every component participating in the pipeline must implement the Runnable interface, which defines standard methods like invoke, stream, batch, and ainvoke, ensuring interoperability between components. - LangChain Main Package: Contains application-layer logic including Chains, Agent (intelligent agents), and Retriever (retrieval augmentation).
- LangChain Community: A community plugin library integrating numerous third-party components such as Output Parsers, Document Loaders, vector stores, text splitters, Embeddings, and more.
- LangServe: A deployment module that wraps LangChain applications as REST APIs using FastAPI — similar to deploying a Java application to Tomcat.
- LangSmith: A tracing and observability platform, analogous to SkyWalking or Zipkin in Java microservices.
- LangGraph: A graph-based enhanced Agent implementation suited for complex multi-step decision-making scenarios. Unlike traditional LangChain Agents that follow the linear "think-act-observe" loop of the ReAct (Reasoning + Acting) paradigm, LangGraph introduces the concept of Directed Graphs, modeling each Agent decision step as a Node in the graph and the transition logic between steps as Edges. It supports conditional routing, loops, parallel branches, and other complex control flows. It also has a built-in state management mechanism where each node can read and write shared state, similar to a Finite State Machine (FSM). This enables developers to build advanced applications such as multi-Agent collaboration, complex workflow orchestration, and Human-in-the-loop systems.
The Value of LangSmith Tracing
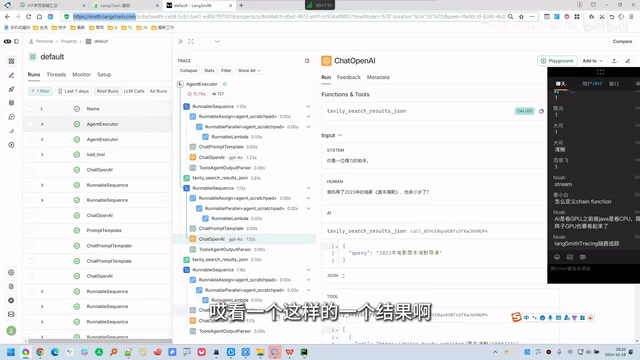
In complex LangChain applications, a single request may involve dozens of trace spans across multiple LLM calls, tool executions, and Agent decisions. LangSmith provides visual tracing capabilities that clearly show execution time and data flow at each step.
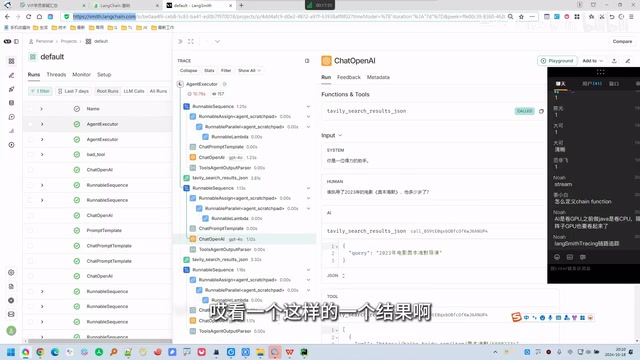
For example, LangSmith can reveal that a particular search tool call took 3.81 seconds, enabling precise identification of performance bottlenecks. This is critical for troubleshooting in production environments. LangSmith offers a free tier (approximately 1,000 calls per month), and developers can sign up with a Google account.
Version Selection Recommendations
The latest LangChain version is 0.3.x, though version 0.1 is still widely used. Version 0.3 is compatible with most of 0.2's content, primarily fixing compatibility issues in certain modules. New projects should use version 0.3 directly, while existing projects can evaluate upgrading based on their specific circumstances.
Guide to Reading the Official Documentation
Documentation Structure
The official LangChain English documentation (python.langchain.com) is well-structured and includes the following sections:
- Introduction: Framework overview and architecture summary
- Tutorials: Hands-on tutorials including RAG application building, text generation, and other use cases. RAG (Retrieval-Augmented Generation) is one of the most important architectural patterns in current LLM applications, proposed by Meta AI in 2020. Its core idea is: before the LLM generates an answer, first retrieve document fragments relevant to the user's question from an external knowledge base, inject these fragments as context into the prompt, and let the model generate answers based on real data. This approach effectively addresses two major pain points of LLMs — outdated information due to knowledge cutoff dates, and factual errors caused by model "hallucination." In LangChain, implementing RAG involves the collaboration of multiple components: Document Loader handles loading raw documents, Text Splitter breaks long documents into appropriately sized chunks, Embeddings models convert text into vector representations, Vector Stores (such as FAISS, Chroma, Pinecone) store and retrieve vectors, Retriever encapsulates retrieval logic, and finally a Chain connects the retrieval results with the LLM call.
- How-to Guides: Development manuals covering LCEL syntax, Runnable interface, Stream usage, and more
- API Reference: Detailed definitions of packages and methods, similar to Java API documentation
- Integrations: A list of integration services showing LangChain's integration packages with various models and databases
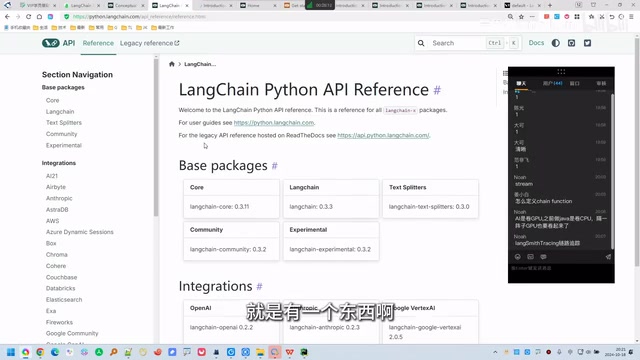
You may not have noticed that langchain-openai and openai are two different packages. The former is LangChain's wrapper around the OpenAI SDK, similar to Spring's integration with MyBatis (Spring-MyBatis). LangChain also integrates with AWS, HuggingFace, Anthropic (Claude), MongoDB, and many other components. Developers can find the integration solutions they need on the Integrations page.
Deep Dive into LangChain's Message Abstraction System
Message Types & Role Mapping
LangChain provides a unified abstraction over the message formats of different LLMs. Developers don't need to worry about whether the underlying model is GPT, ERNIE Bot, or Qwen — they only need to understand the following message types:
| LangChain Message Type | Corresponding OpenAI Role | Description |
|---|---|---|
| HumanMessage | user | Message sent by the user |
| AIMessage | assistant | Message returned by the AI model |
| SystemMessage | system | System prompt defining model behavior/persona |
| FunctionMessage | - | Message for simple function calls |
| ToolMessage | - | Result message after a tool call |
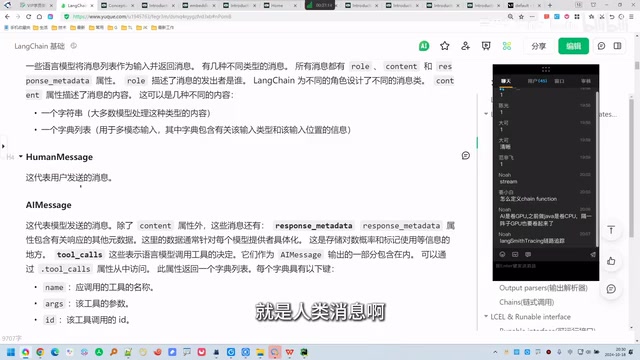
AIMessage also contains response_metadata, which encapsulates information such as token usage. ToolCall is used in Agent scenarios for tool invocations, requiring the tool name, parameters, and ID.
The core value of this abstraction design is: switching the underlying model requires no changes to the upper-layer code. This is essentially a classic application of the Adapter Pattern. Different LLM providers have significant differences in their API message formats: OpenAI uses a role/content dictionary structure, Anthropic (Claude) uses a unique messages array format with a separate system parameter, Google Gemini uses a nested parts/role structure, and domestic providers like ERNIE Bot and Qwen each have their own request formats. If developers directly integrate with each provider's SDK, switching models means extensive code rewrites. LangChain encapsulates model differences within their respective ChatModel implementations by defining a unified BaseMessage abstract base class and its subclasses. Developers only need to change the model instantiation code (e.g., switching from ChatOpenAI to ChatAnthropic), while the upper-layer Prompt, Chain, and Agent code remains completely unchanged. This design is especially important in enterprise applications, where model selection often needs to be dynamically adjusted based on cost, performance, and compliance factors.
Token Metering & Cost Control
The token usage information contained in AIMessage's response_metadata is critical for production environments. LLM APIs are billed per token — one token corresponds to roughly 4 characters in English or 1-2 Chinese characters. Each API call incurs costs for both prompt_tokens (input consumption) and completion_tokens (output consumption). Taking GPT-4o as an example, the input price is approximately $2.5 per million tokens, and the output price is approximately $10 per million tokens. In RAG applications, since a large amount of retrieved context documents is injected with each request, prompt_tokens can be very high. Therefore, monitoring token usage, optimizing prompt length, and selecting the appropriate model tier are key to controlling operational costs. LangSmith's tracing can precisely record the token consumption of each call, helping developers perform cost analysis and optimization.
Prompt Template Development in Practice
String Prompt Templates
The most basic template approach, suitable for simple variable substitution scenarios:
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template("Tell me a joke about {topic}")
result = prompt.invoke({"topic": "cats"})
By passing a variable dictionary through the invoke method, you can generate the complete prompt text.
Chat Prompt Templates
Designed specifically for conversational scenarios, supporting templated multi-role messages:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的翻译助手"),
("user", "请将 {text} 翻译成中文")
])
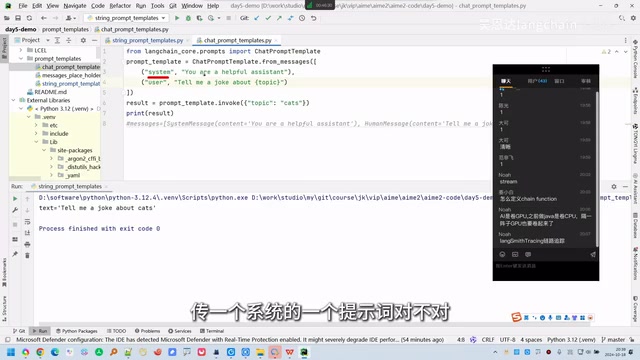
When invoked, LangChain automatically wraps the content of different roles into their corresponding Message objects — the system role generates a SystemMessage, the user role generates a HumanMessage, and each message's content field contains the actual text.
MessagesPlaceholder
When you need to dynamically inject a list of messages, use MessagesPlaceholder:
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个AI助手"),
MessagesPlaceholder("messages")
])
result = prompt.invoke({
"messages": [HumanMessage(content="你好"), HumanMessage(content="今天天气怎么样")]
})
Unlike single string substitution, MessagesPlaceholder supports passing in a list of messages (dictionaries/arrays), making it ideal for injecting multi-turn conversation history.
Output Parsers & LCEL Chain Invocations
The Role of Output Parsers
When calling an LLM, the raw response contains extensive information including content, response_metadata, token usage, and more. If you only need the core text content, use StrOutputParser:
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()
# Raw response: AIMessage(content="苹果", response_metadata={...})
# After parsing: "苹果"
The essence of output parsers is extracting key content from the complex response payload returned by the AI, similar to a JSON Parser in Java.
LCEL Chain Invocation in Practice
LangChain Expression Language (LCEL) is the framework's core programming paradigm, using the | pipe operator to chain multiple components together:
chain = model | parser
result = chain.invoke("将Apple翻译成中文")
This syntax is similar to Java's Stream API chaining. model | parser generates a Chain object, and when invoke is called, it executes sequentially: first calling the LLM to get a response, then extracting the text content through the parser. The final result is identical to calling each step separately, but the code is much more concise and elegant.
LCEL also provides the Runnable Interface specification, supporting streaming, async processing, batch execution, and other advanced capabilities — forming the foundation for building complex Agent applications. Runnable is the cornerstone interface of LCEL, defining the standard contract for all executable components in LangChain. It specifies five core methods: invoke (synchronous single call), ainvoke (asynchronous single call), stream (synchronous streaming output), astream (asynchronous streaming output), and batch (batch call). Streaming is particularly important for user experience — when an LLM generates long text, streaming allows users to see the generation process character by character rather than waiting several seconds for the entire content to appear at once. This is exactly how ChatGPT's web interface achieves its "typewriter effect." Batch calls are suited for scenarios requiring simultaneous processing of multiple requests, where LangChain automatically optimizes concurrency. The Runnable interface also supports utility classes like RunnablePassthrough (pass-through), RunnableParallel (parallel execution), and RunnableLambda (custom function wrapper), enabling developers to build arbitrarily complex data processing pipelines.
Debugging & Observability
LangChain's debugging mechanism is similar to Java's logging frameworks (such as Logback), allowing configuration of different log levels (debug, verbose, etc.) to output detailed execution information. Combined with LangSmith's tracing, developers can quickly pinpoint problem areas and performance bottlenecks in complex applications.
Conclusion
LangChain 0.3 has built a comprehensive development system for LLM-powered applications: message abstraction shields developers from underlying model differences, prompt templates boost development efficiency, LCEL enables elegant chain orchestration, and LangSmith ensures production observability. For developers with a Java/Spring background, LangChain's design principles (dependency injection, template pattern, chain invocation) will feel familiar — the key lies in understanding its core abstractions and applying them flexibly in practice.
Key Takeaways
Related articles
DeepMind TacticAI Lands at Palmeiras: AI Predicts Match Dynamics 8 Seconds in Advance
Google DeepMind partners with Palmeiras to deploy TacticAI, the first AI tactical system in professional football, predicting open-play dynamics 8 seconds ahead.

Local Deployment of Claude Code: Principles and Practical Guide for Three Approaches
A detailed guide to locally deploying Claude Code with three approaches (LM Studio, Ollama, vLLM), covering architecture, protocol translation, hardware selection, and model recommendations.
Kuaima Client Tutorial: A Detailed Guide to Pay-Per-Use Pricing for Cursor's Premium Models
A detailed guide to downloading, installing, configuring, and using the Kuaima client for pay-per-use access to Cursor's premium AI models, with troubleshooting tips and security advice.