From Tokens to Agents: A Deep Dive into the Core Logic Behind AI's Key Concepts
Tracing the evolution from Tokens to Agents: a clear framework for understanding core AI concepts.
This article systematically deconstructs the underlying logic and evolutionary relationships among core AI concepts including Token, RAG, Agent, MCP, and Function Call. Starting from the probabilistic nature of LLMs, it traces a clear progression from basic conversation to memory systems, retrieval-augmented generation, tool invocation, standardized protocols, workflows, and ultimately autonomous multi-agent systems, providing a coherent framework for understanding AI technology.
Introduction: AI Buzzwords Are Everywhere, but the Underlying Logic Is One Continuous Thread
Token, RAG, Agent, MCP, Function Call, Scale… New concepts in AI emerge endlessly, with fresh buzzwords flooding our feeds every few weeks. For practitioners and learners alike, the relationships and hierarchy among these concepts can be utterly bewildering.
But if we start from the underlying logic, a clear evolutionary path emerges — these concepts aren't isolated from one another. They form a complete chain of evolution from "word prediction games" to "autonomous agents." This article systematically traces that evolutionary path to help you build a clear cognitive framework for AI technology.
The Essence of Large Language Models: A Probabilistic Word Game
From Probability Prediction to Two Model Styles
The core principle of large language models (LLMs) is actually quite simple — probabilistic next-token prediction. When you input "What is the capital of China," the model outputs "Beijing" with extremely high probability. But this isn't a deterministic output — it's the result of probabilistic sampling. For questions like "What's the best Chinese movie" where there's no standard answer, the model outputs various answers with different probabilities.
This probabilistic nature is a double-edged sword: in creative writing scenarios, the divergence from low-probability sampling is an advantage; but in agent scenarios requiring precise execution, this uncertainty becomes the root cause of "hallucinations."
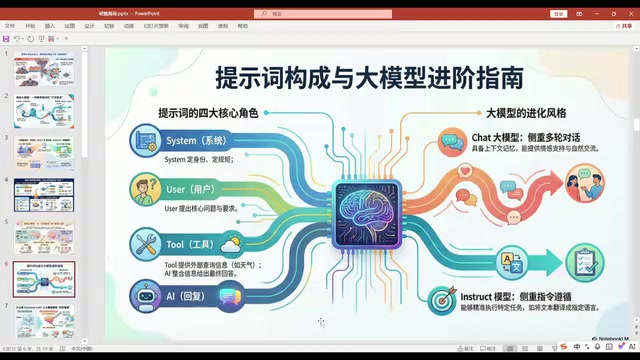
Based on different application needs, LLMs are fine-tuned from base models into two styles:
- Conversational models: Back-and-forth dialogue, suitable for chat and Q&A scenarios — the dominant application form when ChatGPT first went viral
- Instruction-following models: Explicitly executing tasks like translation, summarization, code generation, etc.
In practice, modern LLMs can flexibly switch between these two styles through prompt engineering, without needing two separate models.
Token: The Universal Language of LLMs
LLMs don't process text directly. Instead, they convert all input into Tokens — individual numeric IDs. You can roughly think of Tokens as English morphemes or individual Chinese characters, but the reality is more complex: two words might merge into one Token, and one word might be split into multiple Tokens.
It's precisely because of the Token mechanism that LLMs inherently possess powerful cross-language capabilities. All languages are uniformly mapped into Token space and processed on a level playing field — no need to build separate models for Chinese, English, or Japanese.
Four Core Role Identities
In practical development, the industry has distilled four commonly used prompt roles:
- System: Defines the system identity and behavioral guidelines
- User: Represents the user's input
- Tool: Represents results returned by tools
- Assistant: Represents the LLM's response
These four aren't the only options — theoretically, you could define an unlimited number of role identities. But these four have proven most universal in production practice, so LLMs are specifically optimized for these four roles during base model training.
Function Call: Connecting LLMs to the Real World
Breaking Through the Knowledge Freshness Bottleneck
LLMs have an inherent limitation — knowledge staleness. Once training is complete, the model can't possibly know about events that occurred after its training cutoff date. For example, asking "Who is the U.S. President" might yield an outdated answer from the model's training data.
To solve this problem, Function Call was born. Here's how it works:
- The user inputs a question
- The LLM determines it needs to call an external tool (e.g., a search engine)
- It calls the tool function via an API interface
- The tool returns execution results
- The LLM integrates the results and outputs a final answer
Function Call is the foundational capability behind all current agents (including various AI products). It transforms the LLM from a static knowledge base into a dynamic system that can interact with the external world.
MCP: A Unified Standard Protocol for Tool Invocation
From Interface Chaos to Industry Standardization
Function Call introduced a new problem: LLM providers are on one side, and tool providers (search engines, maps, payment systems, etc.) are on the other, each with different interface specifications. In the early days, LLM providers had to write custom adapter code for each tool, making maintenance costs extremely high.
MCP (Model Context Protocol) is essentially not a new technology, but a standardized interface for tool packaging. It mandates that all tools be packaged in a unified format and that LLMs call them in a unified format.
This is like what the HTTP protocol is to the internet — it's precisely because websites uniformly follow the HTTP standard that users can access all websites with a single browser. The emergence of MCP signals that the AI industry is moving toward standardization and normalization — an important sign of industry maturation.
RAG: Enabling LLMs to Understand Your Private Knowledge
When you need to answer questions based on internal company policies, legal documents, or other private data, general-purpose LLMs clearly fall short. RAG (Retrieval-Augmented Generation) works as follows:
- The user's question is used to search a document repository
- Relevant retrieved content is injected into the LLM's context
- The LLM generates answers based on these documents
The core value of RAG is that it allows LLMs to "learn" domain-specific knowledge without retraining the model. It's one of the most common technical approaches in enterprise AI applications.
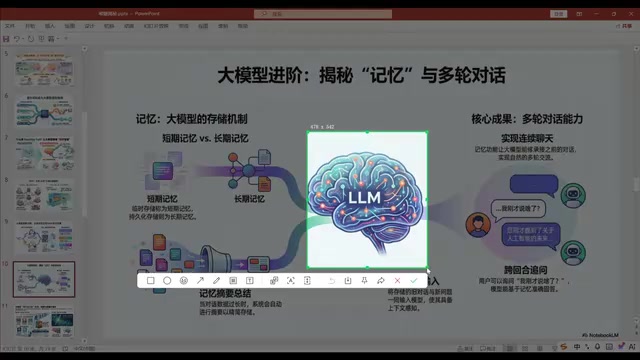
Memory Systems: Adding "RAM" to Stateless LLMs
LLMs are fundamentally stateless systems — they don't remember previous conversations. To achieve coherent multi-turn dialogue, external memory systems are needed:
- Short-term memory: Stores previous conversation history and sends it along with each new query to the LLM, enabling coherent multi-turn dialogue
- Long-term memory: Persists important information to disk, similar to the relationship between RAM and hard drives
- Memory summarization: When conversation history becomes too long, it's summarized and compressed, saving Token consumption while retaining key information (such as user profiles and preferences)
This is like how a CPU itself has no memory capability and relies on RAM and hard drives for data storage and retrieval. An LLM's memory capability is entirely dependent on external systems.
From Workflows to Agents: Two Levels of Automation
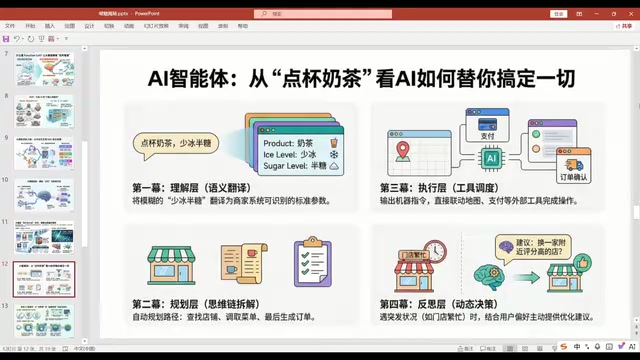
Workflows: Semi-Autonomous Driving
Take "AI ordering bubble tea" as an example. The entire process is pre-planned into four steps:
- Intent understanding: Parse user requirements (bubble tea, less ice, half sugar)
- Chain-of-thought decomposition: Find a shop → pull up the menu → generate an order
- Tool invocation: Call tools like Alipay to complete payment
- Exception reflection: Automatically switch to alternatives when a shop is out of stock
This is a Workflow — the steps are pre-planned by humans, and the LLM only serves as the semantic understanding and execution engine at each step. It's like how the path through school (elementary → middle → high school) is predetermined, but how you learn at each stage is up to the LLM. The vast majority of "agents" currently used in enterprises are essentially workflows.
Agent: True Autonomous Driving
A true Agent is completely different — you only need to provide the final goal (e.g., "I want to get into college"), and the agent autonomously plans the path, executes tasks, evaluates results, and adjusts strategies. Its core capabilities can be abstracted into four steps:
- Understand: Comprehend user requirements
- Plan: Decompose requirements into executable steps
- Execute: Call tools to complete each step
- Reflect: Evaluate results and decide on next actions
Agents represent the ideal state of AI applications, but they currently face trust challenges — you need to trust the model's capabilities, security, and permission management, which remains a significant challenge for today's LLMs.
Multi-Agent Systems and Scale: Advanced Solutions for Collaboration and Cost Reduction
Multi-Agent: Team Collaboration Mode
When multiple agents need to work together, they form a multi-agent system. Each sub-agent has its own independent memory store and "brain," and they only exchange necessary interaction results without sharing all memories. It's like collaboration among colleagues at a company — you only need to know the results your colleague gives you, not their entire thought process.
Each sub-agent can even connect to different base LLMs: use a code-specialized model for coding tasks, a text-specialized model for writing tasks — leveraging each model's strengths.
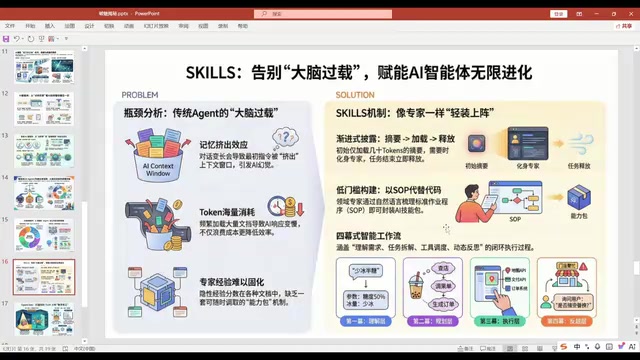
Scale: Lowering Development Barriers with Natural Language
Agent prompts are often extremely long, causing two problems: high Token consumption and the LLM losing focus on key points. Scale's solution is to write skills as independent text descriptions that the LLM loads on demand — reading only what it needs rather than loading all prompts at once.
More importantly, Scale's skill descriptions are written entirely in natural language, requiring no code, which dramatically lowers the barrier to agent development.
Token Economics: The Inescapable Cost Problem
Whether it's RAG, Function Call, memory systems, or agents, everything ultimately consumes Tokens. From the early days of a few thousand Tokens of context to today's 200K or even million-Token context windows, the growth has been rapid.
But two things are worth noting:
- Token length ≠ comprehension quality: Supporting long Token contexts doesn't mean the model understands them well — just like being fast at arithmetic doesn't mean being accurate
- Cost is the key to real-world deployment: Agent Token consumption grows exponentially — continuous reasoning loops can easily burn through hundreds of thousands of Tokens
When choosing a model, don't blindly trust parameter specs and leaderboard rankings. Testing against your actual business scenarios is the only reliable approach.
Conclusion: A Clear AI Technology Evolution Chain
Looking back at the full picture, the evolutionary path of AI technology is actually very clear:
Conversation (base model) → Memory (multi-turn dialogue) → RAG (external knowledge) → Function Call (tool invocation) → MCP (standardization) → Workflow (pre-defined paths) → Agent (autonomous planning) → Multi-Agent (team collaboration) → Scale (modular skills) → Full-permission Agent (software control)
The foundation of all these concepts is "conversation" — you ask a question, it gives an answer. Building on that, injecting conversation history enables memory, injecting documents enables RAG, outputting tool calls enables Function Call, and combining planning with execution enables agents.
The next time you encounter any new AI concept, there's no need to panic — its underlying principles can always find their place on this evolution chain.
Related articles

Five Common Claude Code Mistakes — How Many Are You Making?
Five common Claude Code mistakes developers make: copy-pasting code, skipping CLAUDE.md, inefficient prompting, ignoring docs, and poor context management — with fixes.

Andrew Ng's New Course Explained: A Practical Guide to Using OpenAI's O1 Reasoning Model
Deep dive into Andrew Ng and OpenAI's Reasoning with O1 course covering test-time scaling, new prompting paradigms, multi-model orchestration, and practical applications for developers.

Learning AI After College Entrance Exams: A Complete Path from Zero to Freelancing
How to efficiently learn AI skills during summer break after exams? A complete path from mastering prompts and hands-on projects to freelancing on platforms.