GitHub AI Weekly Rankings: Agent Infrastructure Projects Dominate, Toolchain Ecosystem Taking Shape
Agent infrastructure projects dominate GitHub's AI weekly rankings as the toolchain ecosystem rapidly matures.
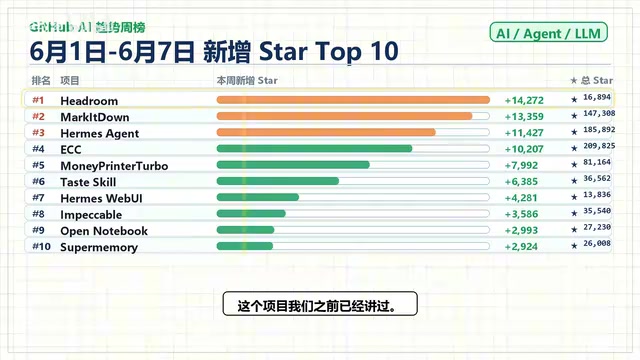
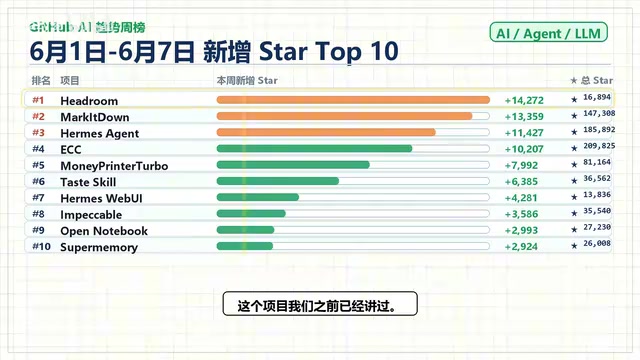
The first week of June 2026 GitHub AI trending rankings reveal a clear signal: Agent infrastructure projects are collectively surging. Hedron (context compression) and Microsoft's MarkItDown (document-to-Markdown conversion) lead with ~14,300 and ~13,400 new Stars respectively. The top 10 spans context management, document parsing, memory systems, and aesthetic enhancement — forming a complete Agent capability stack that signals the ecosystem's shift from framework competition to modular toolchain collaboration.
Weekly Overview: Agent Infrastructure Claims Half the Leaderboard
The GitHub AI trending weekly rankings for the first week of June 2026 (June 1–7) are out, and a clear signal has emerged — Agent infrastructure projects are experiencing a collective explosion. Among the top ten, projects related to the Agent toolchain claimed the majority of spots, spanning areas like context compression, document parsing, memory systems, and aesthetic enhancement.
The term "Agent" here refers to AI systems capable of autonomously perceiving their environment, formulating plans, and executing actions — distinct from traditional single-turn Q&A large language models. Agent Infrastructure encompasses the underlying toolchain and middleware ecosystem required to support these intelligent agents. Since 2024, as companies like OpenAI, Anthropic, and Google have successively released models with Tool Use and multi-step reasoning capabilities, Agents have moved from proof-of-concept to engineering deployment. But improved model capabilities are only the first step. The real bottleneck constraining large-scale Agent deployment lies in the maturity of surrounding infrastructure — including context management, data parsing, persistent memory, security auditing, and more. This is exactly the core signal reflected in this week's GitHub trends.
We're no longer in the era of "AI can chat." We've entered the stage of "AI is growing a complete toolchain." Context compression, document reading, memory formation, aesthetic improvement — these capabilities are rapidly materializing in the form of open-source projects.
Top 10 Leaderboard at a Glance
Here are this week's top ten projects and their approximate new Star counts:
| Rank | Project | Weekly New Stars (approx.) |
|---|---|---|
| 1 | Hedron | 14,300 |
| 2 | MarkItDown (Microsoft) | 13,400 |
| 3 | Hermes Agent | - |
| 4 | ECCM | - |
| 5 | Money Printable | - |
| 6 | Taste Skill | - |
| 7 | Hermes Weibo | - |
| 8 | Impackable | - |
| 9 | Open Notebook | - |
| 10 | Super Memory | - |
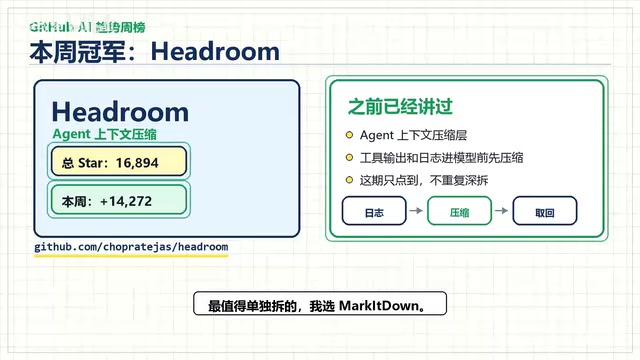
The champion, Hedron, continued its strong momentum, racking up approximately 14,300 Stars in a single week. It addresses a very practical pain point in Agent development: context windows that are too long and tool outputs that are too verbose, causing Token consumption to spiral out of control.
To understand the severity of this pain point, you need to grasp the basics of context windows and Token economics. A Context Window is the maximum text length a large language model can process in a single inference pass, measured in Tokens. One Token corresponds to roughly 3/4 of an English word or 1–2 Chinese characters. Although the latest models have expanded context windows to 128K or even million-level Tokens, longer contexts mean higher API call costs and slower inference speeds. Take GPT-4o as an example: input Token pricing is approximately $2.5–5 per million Tokens. When an Agent frequently calls tools during complex tasks and accumulates large volumes of intermediate output, Token consumption for a single task can reach hundreds of thousands, causing costs to quickly spiral out of control. Context compression technology uses intelligent summarization, redundant information removal, and hierarchical caching to dramatically reduce the actual number of Tokens fed to the model — without losing critical information — making it one of the highest-ROI optimization strategies in Agent engineering.
As Agents grow increasingly complex, context management has become a core engineering bottleneck. Hedron's sustained popularity demonstrates that community demand for this type of infrastructure is extremely strong.
Most Noteworthy: Microsoft's MarkItDown
The project most deserving of a deep dive this week is Microsoft's MarkItDown, which gained approximately 13,400 Stars, hot on the champion's heels.
MarkItDown's functionality hits the nail on the head: converting PDFs, Office documents, and other file types into Markdown format. This might seem like a "small utility," but its value in real-world AI workflows is seriously underestimated.
Why Is MarkItDown So Important?
-
A critical link in knowledge base construction: When building a RAG (Retrieval-Augmented Generation) system, the first step is converting unstructured documents into an indexable format. Markdown, as a lightweight markup language, is naturally suited as an intermediate format.
The technical background of RAG deserves further explanation. RAG (Retrieval-Augmented Generation) is one of the most mainstream architectural patterns in enterprise AI applications today. Its core idea is: rather than relying on the model's parametric memory to answer questions, it retrieves relevant document fragments from an external knowledge base in real-time during inference, injecting them as context into the prompt so the model can generate answers based on the most current and accurate information. A typical RAG pipeline includes four stages: document collection → document parsing and chunking → vector storage → retrieval and generation. Document parsing is the first critical gate in this entire pipeline. Enterprise knowledge assets largely exist in formats like PDF, Word, PPT, and Excel. These files contain complex layouts, tables, images, and nested structures. Extracting plain text directly often loses structural information, severely degrading downstream retrieval quality. Markdown, as a lightweight markup language, can preserve heading hierarchies, lists, tables, code blocks, and other structural information in plain text form while being very friendly to vectorization and chunking operations. This is why it has become the de facto standard intermediate format in RAG systems.
-
A standardized pipeline for feeding Agents: When you need an Agent to read and understand internal enterprise documents, MarkItDown provides a standardized path from "raw documents" to "Agent-consumable content."
-
Microsoft-backed engineering quality: As an official Microsoft open-source project, its maturity in format compatibility and edge case handling far exceeds what individual community projects can offer.
For developers building enterprise-grade AI applications, MarkItDown is practically a must-have tool.
This Week's Dark Horse: Taste Skill
If MarkItDown is "predictably practical," then Taste Skill is "unexpectedly delightful."
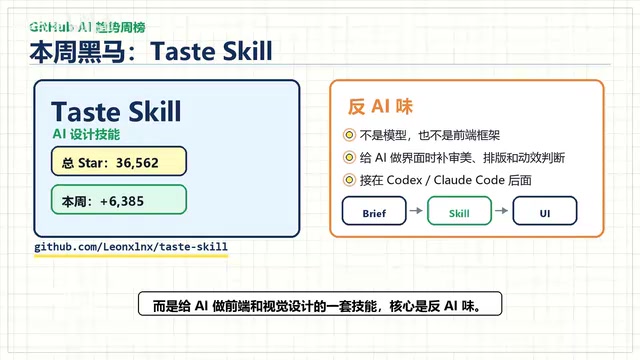
Taste Skill is neither a model nor a framework — it's a skill system for AI frontend and visual design. Its core philosophy is "anti-AI aesthetic" — helping AI-generated interfaces and visual work break free from that cookie-cutter "AI look" and achieve higher aesthetic quality.
Why Does This Deserve Attention?
There's a widely acknowledged problem with AI-generated frontend code and design solutions: they're functional, but aesthetically screaming "AI." Whether it's color schemes, layouts, or interaction details, everything carries a mechanical feel.
The root cause of this "AI aesthetic" problem is worth understanding in depth. In frontend development, AI-generated interfaces often exhibit highly homogenized characteristics: overuse of gradients and rounded card components, lack of visual hierarchy, mechanically uniform spacing and whitespace, and color palettes that default to conservative blue-purple tones. The root cause is that LLM training data contains vast amounts of templated UI code and design specification documents, causing models to gravitate toward generating "statistically safest" design solutions rather than work with personality and taste. Taste Skill represents a new approach: rather than solving the aesthetic problem at the model level, it injects design principles, aesthetic rules, and anti-pattern recognition capabilities at the prompt engineering and skill framework level. The advantage of this approach is that it can work with any underlying model and can be customized for different brand identities and design languages.
Taste Skill attempts to solve this problem at the skill level, enabling AI to not only "get things done" but "make things look good."
This reflects a deeper trend: competition in the AI toolchain is shifting from "can it do it" to "how well does it do it." When foundational capabilities become homogenized, aesthetics and quality become the key differentiators.
Trend Analysis: The Agent Toolchain Is Taking Shape
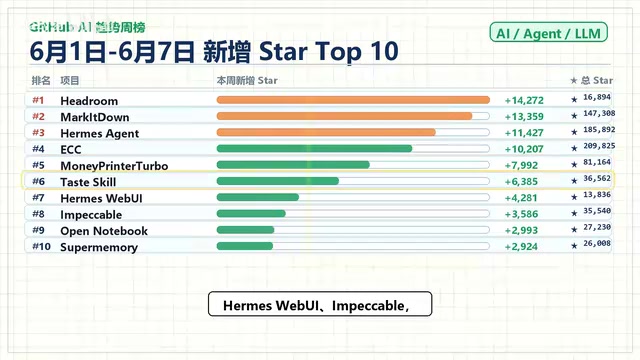
Looking across this week's leaderboard, a clear thread emerges:
- Context management: Hedron solves the Token consumption problem
- Document parsing: MarkItDown opens the gateway to unstructured data
- Memory systems: Super Memory gives Agents long-term memory
- Aesthetic enhancement: Taste Skill elevates AI output quality
- Social connectivity: Projects like Hermes Weibo connect Agents to the real world
The memory system component deserves special attention. Memory systems are the core capability that enables Agents to evolve from one-off tools into persistent assistants. Drawing from cognitive science classifications, Agent memory is typically divided into three levels: Working Memory corresponds to the context window of the current conversation — limited in capacity and lost when the session ends; Short-term Memory maintains coherence across multiple interaction turns through session summarization and key information extraction; Long-term Memory persistently stores user preferences, historical decisions, and learned knowledge in external databases, enabling Agents to accumulate experience across sessions and tasks. Technical approaches for implementing long-term memory include vector database retrieval, knowledge graph storage, and structured database records. Projects like Super Memory are exploring this direction, attempting to provide Agents with out-of-the-box memory infrastructure that solves the fundamental problem of "starting from scratch with every conversation."
These projects are independent of each other, but when assembled together, they form a complete Agent capability stack. An Agent is no longer just a "chat box" — it's a complete system with perception, memory, tool use, and aesthetic capabilities.
From a more macro perspective, the open-source ecosystem for Agent development is currently undergoing a transition from "framework competition" to "toolchain collaboration." In 2024, competition among Agent frameworks like LangChain, CrewAI, and AutoGen was the dominant theme. By mid-2025, community attention has clearly shifted toward more fine-grained, specialized tools. The logic behind this shift is: frameworks provide the skeleton of an Agent, but what truly determines an Agent's capability ceiling is the quality of specialized tools at each stage. An analogy is the evolution of the web development ecosystem — after frameworks like React/Vue were established, ecosystem prosperity came from the maturation of specialized modules like routing, state management, UI component libraries, and build tools. The Agent ecosystem is following the same path, with context compression, document parsing, memory management, security protection, and every other stage spawning dedicated open-source projects that ultimately form a modular, freely composable toolchain.
Implications for Developers
If you're working on Agent-related development, this week's leaderboard offers clear directional guidance:
- Context compression is a hard requirement — don't wait until your Token bill explodes before thinking about optimization
- Document parsing capabilities define your Agent's knowledge boundaries — tools like MarkItDown should be integrated early
- Memory systems are the key to Agents evolving from "tools" to "assistants"
- Aesthetics and quality will become the competitive focus in the next phase
Conclusion
This week's GitHub AI leaderboard is essentially telling one story: Agent infrastructure is being rapidly filled in through open source. From context compression to document parsing, from memory systems to aesthetic capabilities, every component has dedicated projects working to solve it.
This means the barrier to building a fully functional Agent system is dropping fast. For developers, the most important thing right now isn't reinventing the wheel from scratch — it's learning to combine these open-source tools to build Agent applications that truly solve problems.
What surprises will next week's leaderboard bring? Let's wait and see.
Related articles

PilotDeck: A Local Console That Tames Multi-Task Agent Chaos
PilotDeck is an open-source local Agent console from a Tsinghua-affiliated team that solves multi-task chaos with workspace isolation, white-box memory management, and smart model routing.
Fusion Startup Funding Landscape: A Deep Dive into the $7.1 Billion Flow and Industry Dynamics
Global fusion startups have raised $7.1B, heavily concentrated in top players. A deep analysis of funding patterns, tech pathways, commercialization challenges, and the investment logic behind this ultimate energy bet.

Codex and Claude Code Dual-Engine: A Practical Guide to AI-Powered Engineering
A deep dive into AI engineering with Codex and Claude Code: Vibe Coding limitations, Chinese LLM rankings, Skill-driven development, and enterprise project practices.