GLM 5.2 & Zcode Hands-On Review: A Deep Dive into the Free AI Coding Tool with 5 Million Tokens/Day
GLM 5.2 + Zcode offers frontier-level open-weight coding with 5M free tokens/day, but tool maturity lags behind Codex.
Zhipu AI's GLM 5.2 achieves the highest score among open-weight models on the Artificial Analysis Intelligence Index and shows dramatic coding improvements—scoring 81 on Terminal Bench and 62.1 on SWE-Bench Pro. Paired with Zcode (a free Codex-like tool offering 5M tokens/day), it provides strong value for daily coding. However, Zcode lacks file management and browser automation, and Opus still dominates the hardest engineering tasks.
Introduction: Zhipu's Double Launch
Zhipu AI recently released the GLM 5.2 model, generating significant buzz in the community. But on the side, they also quietly launched another product—Zcode. This is an AI coding tool similar to OpenAI Codex, specifically fine-tuned and optimized for GLM models. What makes it even more attractive is its free tier offering 5 million tokens per day, powered by the GLM 5.2 model.
So how does this combo actually perform? This article provides a comprehensive analysis across three dimensions: tool experience, model performance, and benchmark testing.
Zcode Tool Experience: Like Codex but with Notable Shortcomings
Interface & Basic Features
Using Zcode requires a GLM Coding Plan, an API Key, or simply the free tier. Its interface design is strikingly similar to OpenAI's Codex—the overall visual style and layout details are nearly identical. The sidebar allows creating new tasks, searching history, and features a marketplace-like Skills system where users can browse and install different skill extensions. The Skills system is essentially a collection of predefined prompt templates and toolchain combinations, similar to a plugin ecosystem in an IDE, allowing community contributors to create dedicated workflow configurations for specific development scenarios (such as React component generation, database migration, unit test writing, etc.).
In the settings page, you can also find options for MCP Servers, Plugins, as well as Indexing usage and quota information. MCP (Model Context Protocol) is an open protocol introduced by Anthropic in late 2024, designed to standardize interactions between AI models and external tools and data sources. It's like a USB-C port for the AI world, enabling different AI models to call file systems, databases, APIs, and other external resources in a unified way. Zcode's MCP support means users can seamlessly integrate various third-party tools into their programming environment. The top bar provides options to open the project in any editor, plus a panel toggle button that opens a full built-in browser for previewing.
Highlights & Shortcomings
On the highlights side, Zcode's Preview feature automatically switches to the right editor panel for convenient effect previewing. Users can reference elements from the Preview in the chat box to modify specific parts, and can also open developer tools to view console logs.
Another commendable feature is remote messaging platform integration, which can connect to platforms like WeChat, allowing users to send instructions anytime, anywhere to have the Agent start processing tasks. This asynchronous work mode is extremely practical in real development—developers can send an instruction via phone during their commute to have the Agent start handling code refactoring or bug fixes in the cloud, potentially completing the task by the time they reach the office.
But the shortcomings are also quite apparent:
- The built-in browser cannot be autonomously controlled by AI like Codex can (Codex's browser can be automatically clicked, scrolled, and form-filled by AI, enabling end-to-end UI testing and debugging)
- File change logs cannot be fully listed; only a div is visible at the bottom
- No built-in file manager for direct file browsing
- Missing WorkTree options and one-click Git initialization features (WorkTree is an advanced Git feature that allows checking out multiple branches to different directories simultaneously, which is very useful for AI Agents handling multiple task branches concurrently)
- Overall view management is rather rough
These gaps leave Zcode with a significant engineering experience deficit compared to Codex. However, considering its free quota and model capabilities, it still holds value as a supplementary option in your toolkit.
GLM 5.2 Model Performance: A New Benchmark for Open-Weight Models
Comprehensive Evaluation Results
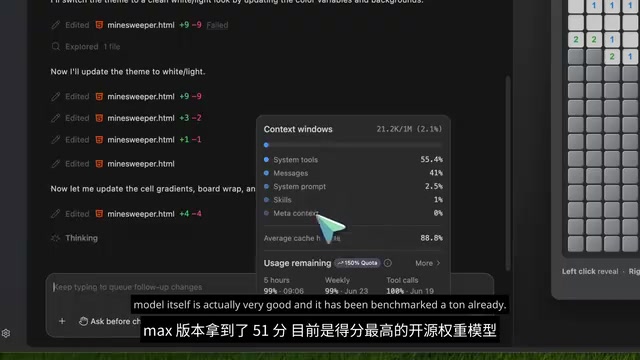
On the independent Artificial Analysis Intelligence Index, the GLM 5.2 MAX version scored 51 points, making it the highest-scoring open-weight model to date. Artificial Analysis is an independent AI model evaluation platform focused on standardized performance comparisons across major language models. Its Intelligence Index combines 9 core benchmarks including MMLU, HumanEval, and GPQA, covering coding, scientific knowledge, tool use, and long-context reasoning, aiming to provide an objective ranking free from vendor influence. GLM 5.2 is an MIT-licensed model, only a few points behind closed-source leaders.
Open weight means the model's parameter weight files are publicly available—users can download and run the model locally or on private cloud infrastructure without relying on the vendor's API service. The MIT license is one of the most permissive open-source licenses, allowing commercial use, modification, and redistribution with virtually no restrictions. This is hugely significant for enterprise applications: data stays on-premises, no API call latency, ability to fine-tune for specific domains, while avoiding vendor lock-in risks. In contrast, many "open-source" models actually come with license terms restricting commercial use—for example, Meta's Llama series requires additional authorization when monthly active users exceed 700 million.
Regarding inference speed, Artificial Analysis measured it at approximately 106 tokens per second, faster than the average for comparable open-source models. For reference, 106 tokens/s is roughly equivalent to generating 80 English words or 40 Chinese characters per second—sufficiently smooth for real-time coding assistance scenarios. However, it's worth noting that the MAX version has higher inference costs—approximately $1.40 per million input tokens and $4.40 per million output tokens, which is on the expensive side compared to other open-source models, though still competitive against closed-source frontier models.
The Leap in Coding Capability
Coding capability is GLM 5.2's most impressive area of improvement:
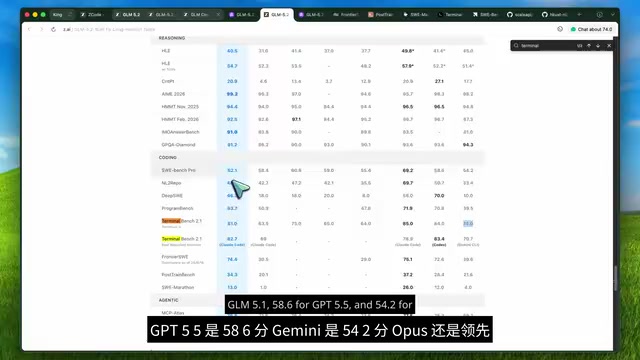
| Benchmark | GLM 5.1 | GLM 5.2 | GPT 5.5 | Opus 4.8 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| Terminal Bench 2.1 | 63.5 | 81 | 84 | 85 | 74 |
| SWE-Bench Pro | 58.4 | 62.1 | 58.6 | 69.2 | 54.2 |
| Diff | 18 | 46.2 | - | - | - |
Terminal Bench simulates developer operations in terminal environments, testing the model's ability to execute shell commands, debug programs, and configure environments. SWE-Bench is a software engineering benchmark developed by a Princeton University research team that requires AI models to solve real issues from GitHub repositories—including understanding codebases, locating bugs, and writing fix patches through the complete software engineering workflow. The Pro version adds more complex multi-file modifications and cross-module dependency scenarios. Both tests are much closer to real development scenarios than traditional code completion benchmarks like HumanEval.
On Terminal Bench, GLM 5.2 scored 81, with minimal gap to Opus's 85 and GPT's 84. On SWE-Bench Pro, it even surpassed GPT 5.5. The Diff score leaped from 18 to 46.2, indicating this isn't simply about expanding the context window—the model's core coding comprehension has genuinely undergone a qualitative improvement. The Diff test specifically evaluates the model's ability to understand and generate code differences (patch/diff format), which is a core skill in code review and version control.
Long-Horizon Agent Tests: The Most Impressive Breakthrough
Three long-horizon benchmarks that more closely simulate actual Coding Agent usage scenarios represent GLM 5.2's most stunning results. The key difference from traditional benchmarks is that these don't evaluate the model's ability to answer single questions—instead, they test the model's ability to work continuously as an autonomous Agent for hours or even tens of hours, managing state and recovering from errors.
Frontier Test
This test evaluates open-ended technical projects lasting hours or even over ten hours, including system optimization, large-scale code construction, and applied machine learning research. GLM 5.2 scored 74 points—Opus got 75, GPT got 72, while GLM 5.1 only managed 30. A single version update more than doubled the score, landing just 1 point behind Opus. This kind of leapfrog improvement is uncommon in AI model iterations and typically indicates fundamental changes in training methodology or data strategy.
Post Train Bench
Each Agent gets an H100 GPU and improves smaller models through Post Training. The H100 is one of NVIDIA's current top-tier data center GPUs, priced at over $30,000 per card with 80GB HBM3 memory, serving as the primary hardware for current AI training and inference. Post Training includes techniques like Supervised Fine-Tuning (SFT) and RLHF, used to further optimize specific model capabilities on top of pre-training. This test essentially has the AI Agent play the role of a machine learning engineer.
GLM 5.2 scored 34.3 points, leading GPT's 28.4 but trailing Opus's 37.2. This test examines whether the Agent can manage experiments and make sustained progress over longer periods—including designing training strategies, monitoring loss curves, adjusting hyperparameters, handling OOM errors, and other tasks requiring long-term planning capabilities.
Suite Bench
This includes ultra-long tasks such as compiler construction, kernel optimization, and production-grade service development. These tasks far exceed ordinary programming in complexity—compiler construction involves lexical analysis, parsing, intermediate representation optimization, and code generation across multiple stages; kernel optimization requires understanding low-level OS mechanisms and hardware characteristics; production-grade service development demands handling concurrency, fault tolerance, monitoring, and other engineering concerns.
GLM 5.2 scored 13 points (GLM 5.1 only got 1), GPT scored 12, Gemini scored 4. But Opus scored 26, literally doubling the next best. This shows that on the hardest, most chaotic engineering tasks, Opus still leads by a wide margin. Opus's advantage in these tasks likely stems from its stronger long-horizon planning capabilities and error recovery mechanisms.
Tool Calling Capability
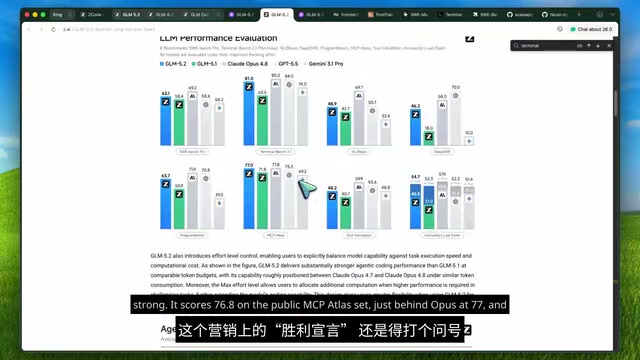
In tool calling, GLM 5.2's performance is mixed. On the public MCP Atlas test set, it scored 76.8 points, closely following Opus's 77 and leading GPT's 75. The MCP Atlas test set specifically evaluates model performance in standardized tool-calling scenarios, including parameter parsing accuracy, multi-step toolchain orchestration, and error recovery. However, on the 2D Castle test, it only scored 48, while Opus got 59 and GPT got 55. 2D Castle is a test scenario more focused on spatial reasoning and multi-tool coordination. It's fair to say that in certain Agent configurations it has reached frontier level, but it's not comprehensively leading.
Key Caveats When Using These Test Results
It's worth emphasizing that these long-horizon tests all used the full 1 million token context, maximum Effort settings, and up to 128K output tokens. SWE-Bench Pro used 400K token context, and Terminal Bench used a 256K context window. These are high-compute evaluations, and different Effort settings or Agent Harnesses can significantly change the scores.
Effort settings (also called compute budget or thinking budget) control the amount of reasoning computation the model invests when generating responses. High Effort means the model performs more internal reasoning steps, similar to a human "thinking longer," which typically significantly improves performance on complex tasks but also means higher latency and cost. A 1 million token context means the model can simultaneously process approximately 750,000 English words of content—crucial for understanding large codebases but also significantly increasing computational overhead per inference. Agent Harness refers to the framework and configuration running the Agent—different prompting strategies, tool-calling methods, and retry mechanisms can all significantly impact final scores.
So the "leading" claims in official marketing deserve some skepticism—it's genuinely strong under specific configurations, but real-world performance may vary by scenario. When choosing models, developers should focus more on test results that match their actual use cases rather than a single composite ranking.
Summary: Who Is GLM 5.2 + Zcode For?
The GLM 5.2 + Zcode combination offers three core value propositions:
- Open weights + MIT license: This is currently one of the strongest open-weight models, with major significance for scenarios requiring private deployment. Enterprises can run the model on their own servers, ensuring code and data never leave the internal network, while fine-tuning against internal codebases for better completion results.
- 5 million free tokens per day: Exceptional cost-effectiveness for daily coding assistance. 5 million tokens is roughly equivalent to handling 3,000-4,000 medium-complexity programming conversations—more than enough for individual developers' daily use.
- Substantial leap in coding capability: The jump from GLM 5.1 to 5.2 isn't incremental—it's a comprehensive capability upgrade, especially in long-horizon tasks and software engineering scenarios where performance now approaches top international closed-source models.
But it's important to be clear-eyed: Zcode as a tool isn't mature enough yet, lacking basic features like file management and version control; and on the most complex engineering tasks, Opus remains the undisputed champion.
For developers, the most pragmatic strategy is probably to add GLM 5.2 + Zcode to your toolkit as a high-value daily coding assistant while continuing to use Opus or GPT for complex projects. For Chinese developers specifically, GLM 5.2 has an additional implicit advantage—as a domestically developed model, its understanding of Chinese programming scenarios (such as Chinese comments, Chinese documentation generation, and Chinese technical discussions) may be more natural and accurate.
Key Takeaways
Related articles
Nobel Laureate John Jumper Leaves DeepMind to Join Anthropic
Nobel Chemistry laureate and AlphaFold lead John Jumper leaves Google DeepMind for Anthropic, signaling an intensifying AI talent war and reshaping the AI for Science landscape.

6 Must-Have MCPs for Claude Code: Upgrade It to a Full AI Development Workstation
6 essential MCPs for Claude Code: Playwright, File System, Sequential Thinking, Context7, GitHub, and Memos — upgrade your AI coding assistant into a complete development workstation.
DeepSeek++ Plugin: Adding Memory and Automation to the DeepSeek Web Interface
DeepSeek++ browser plugin adds long-term memory, Skill automation, and sidebar chat to the DeepSeek web interface — no API setup required. Full feature guide and installation tutorial.