Harness Engineering in Practice: Integrating AI-Driven Development into Enterprise Workflows
Harness Engineering turns AI coding from ad-hoc prompts into a full enterprise development pipeline.
This article traces the evolution of AI-assisted programming through three paradigm shifts — Prompt Engineering, Context Engineering, and Harness Engineering — and shows how the latest paradigm integrates into enterprise workflows. Based on a real-world Java e-commerce project, it covers IDE and model setup, the multi-layered Skill system that drives pipeline-style automation, and practical advice for teams adopting this methodology.
From Prompt Engineering to Harness Engineering: Three Paradigm Shifts in AI Programming
If you've been following the AI programming space, you've likely come across the concept of "Harness Engineering." There's no shortage of videos and articles about it online, but most stay at the conceptual level — you finish reading a pile of terminology and still have no idea how to apply it in a real project.
This article is based on an enterprise-level e-commerce project walkthrough shared by a senior Java instructor on Bilibili. It distills the core methodology of Harness Engineering, covers technical environment setup, and highlights the fundamental differences from traditional AI-assisted programming — helping developers understand how this methodology can truly enter the development workflow and deliver real projects.
Three Stages of AI Engineering Paradigms
To understand Harness Engineering, we first need to review the evolution of AI-assisted programming. The instructor breaks it down into three distinct stages:
Stage 1: Prompt Engineering
When ChatGPT first launched, the hottest concept was "Prompt Engineering." The core idea was how to ask the right questions to a large model — articulate your requirements clearly, engage in a Q&A exchange, and get results. This stage was characterized by simple interactions and single-purpose tasks, suitable for handling well-defined, small problems.
As a practical discipline, Prompt Engineering originated during the mass adoption exploration period following ChatGPT's release in late 2022. Its core principle lies in the fact that large language models (LLMs) are essentially conditional probability generators — given an input sequence, the model predicts the most likely output sequence. Therefore, the wording, structure, examples, and even punctuation of the input can significantly affect output quality. Common prompting techniques include Role Prompting, Chain-of-Thought, Few-shot Learning, and more. However, the fundamental limitation of Prompt Engineering is that it's stateless — each interaction is independent, and the model cannot accumulate an understanding of the overall project. This directly gave rise to the next stage of evolution.
Stage 2: Context Engineering
As problem complexity increased, simple prompts were no longer sufficient. For example, if you ask an AI to "write a technical article mimicking a specific instructor's style," without providing that instructor's past articles as reference, the AI has no idea what the target style looks like.
Similarly, in programming scenarios, if you simply tell the AI to "build me a shopping cart CRUD feature," the resulting code will almost certainly not conform to your team's standards. A more reasonable approach is to first feed the AI some code references and coding conventions, letting it understand the project's style before it starts writing.
The rise of Context Engineering is closely tied to the expansion of large model context windows. Early GPT-3.5 supported only a 4K token context window, while Claude 3.5 expanded to 200K tokens, and Gemini reached the million-token level. Larger context windows allow developers to inject project documentation, coding standards, conversation history, API definitions, and other extensive information into the model all at once. RAG (Retrieval-Augmented Generation) technology was also widely adopted during this stage — using vector databases to retrieve the most relevant document fragments for the current task and dynamically construct context. However, the bottleneck of Context Engineering is that even with larger windows, the model's attention distribution across long texts is uneven (the "Lost in the Middle" problem), and it lacks active control mechanisms over the execution process.
The instructor estimates that over 95% of developers — whether using Claude Code, Cursor, or Codex — are still stuck at this stage.
Stage 3: Harness Engineering
This is the latest and what will be the dominant paradigm for the next 2–3 years. The English word "Harness" translates to equipment used to control horses — reins and tack. The analogy to AI is straightforward: the large model is a powerful stallion, and the Harness is the set of reins that lets you precisely control it.
The core characteristics of Harness Engineering are:
- It's not enough to simply pass in a bit of context — you need extensive constraints and specifications
- During AI task execution, you need continuous interaction, feedback, and correction
- More sophisticated control over the AI is required to accomplish Agent-level complex work
The Agent concept mentioned here originates from autonomous agent research in AI. A typical AI Agent consists of four core modules: a perception module (receiving environmental information), a planning module (task decomposition and path planning), an execution module (invoking tools to complete specific operations), and a memory module (short-term working memory and long-term knowledge storage). In programming scenarios, an Agent can not only generate code but also autonomously invoke terminal commands, read and write the file system, execute tests, analyze error logs, and self-correct. The ReAct (Reasoning + Acting) framework is the current mainstream Agent reasoning paradigm, enabling the model to progressively complete complex tasks through a "think-act-observe" loop rather than producing results in a single shot.
Expressed as a formula: Harness (governance specifications) + LLM (Large Language Model) = Agent (intelligent agent) — an AI system capable of handling more complex tasks.
Enterprise-Level Environment Setup
With the concepts covered, what matters more is seeing how the actual tech stack and engineering environment are set up. The instructor shared the complete technical solution used in his enterprise projects:
IDE and Plugin Selection
The development environment uses the VS Code + Claude Code plugin combination. The instructor specifically emphasized that Claude Code's engineering capabilities are among the best in current tools and recommended it as the first choice for professional programmers. Of course, Cursor or other domestic IDE tools can serve as alternatives — the core lies in the methodology, not the specific tool.
Claude Code is a command-line AI programming tool released by Anthropic in 2025. Unlike IDE-embedded solutions like Cursor, it runs directly in the terminal environment with full access to the file system, Git, and Shell commands. Its core advantages include: support for CLAUDE.md project-level configuration files (a natural carrier for Harness specifications), autonomous multi-step task execution capabilities, and the ability to proactively read project structure during execution to make context-aware decisions. Claude Code's /compact command can compress conversation history to save tokens, and its permission management system allows developers to granularly control which operations the AI can perform (such as whether it can directly modify files or execute Shell commands). This controllability is precisely the technical implementation of the "reins" philosophy emphasized by Harness Engineering.
Model Selection Strategy
The backend model uses Volcano Engine's Coding Plan, costing approximately 200 RMB per month, with support for calling various mainstream large models. For specific model selection, after comparative testing, the instructor recommends Zhipu AI's GLM series models, considering them to be in the top tier among domestic large models.
Volcano Engine is ByteDance's enterprise-level cloud service platform. Its Coding Plan product is essentially a Model Gateway, allowing developers to call services from multiple model providers through a unified API interface, avoiding the tedious work of integrating with different model APIs one by one. Zhipu AI's GLM series models are based on research from Tsinghua University's KEG Lab, employing a unique Autoregressive Blank Infilling pre-training paradigm. In domestic large model benchmarks, the GLM-4 series performs exceptionally well in code generation, logical reasoning, and other dimensions.
Other options include Alibaba's Qwen, Doubao, MiniMax, DeepSeek, Kimi, and others — the gaps aren't huge. It's worth mentioning that Xiaomi's MiMo model has also been performing quite well recently.
The instructor made a compelling point: if enterprise-level project delivery can be achieved using domestic models (like GLM) combined with Harness Engineering, then switching to the latest versions of Claude or GPT will only make things better — after all, it's an industry consensus that top international models are an order of magnitude more capable than domestic ones. It should be noted that this gap is primarily evident in complex reasoning, long-chain task planning, and multilingual code generation scenarios. For routine CRUD development tasks, the gap between domestic and top international models has narrowed significantly, which is an important prerequisite for Harness Engineering to work with domestic models.
Core Differences of Harness Engineering
The instructor demonstrated the fundamental difference between Harness-based programming and ordinary AI programming through a live operation. He entered a seemingly simple command in Claude Code:
"Strictly follow the Turing SHOP project's Harness specifications to add an order logistics tracking feature to this project."
On the surface, this command looks no different from an ordinary AI programming instruction. But the instructor emphasized: the execution flow behind this single command is worlds apart from a regular instruction.
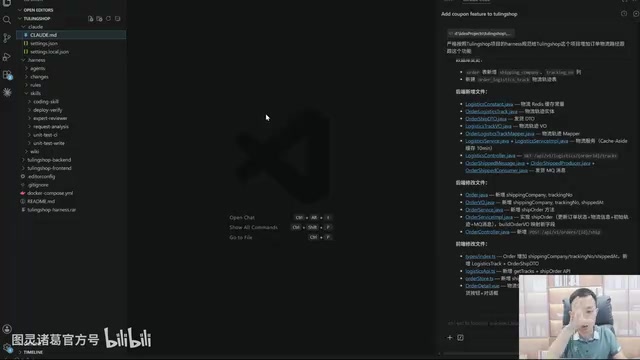
The Underlying Skill System
Behind this command lies a complete Harness Engineering specification system and a team-developed set of enterprise-level full-lifecycle development Skills, including:
- Coding Skill: Coding standards and code generation
- Requirements Analysis Skill: Automated requirement decomposition and understanding
- Unit Testing Skill: Automatic test case generation and execution
- Continuous Integration Skill: CI/CD pipeline automation
- Deployment Skill: Complete deployment workflow automation
In total, there are approximately 6–7 core Skills spanning the entire development lifecycle, achieving pipeline-style automated programming. This means a single command triggers not just simple code generation, but a complete engineering workflow from requirements analysis to deployment.
The Skill system in Harness Engineering is essentially a standardized operating protocol (SOP) designed for AI Agents. Each Skill defines the input specifications, execution steps, quality check criteria, and output format for a specific task. This aligns closely with the CI/CD (Continuous Integration/Continuous Deployment) philosophy in software engineering. Traditional CI/CD pipelines (such as Jenkins, GitHub Actions, GitLab CI) use YAML configuration files to define automated steps for building, testing, and deploying. The Skills in Harness Engineering extend this concept to the entire AI-driven development lifecycle — from automated PRD (Product Requirements Document) parsing during requirements analysis, to architecture pattern matching during code generation, to automatic unit test generation with coverage checks, and finally to automated container deployment orchestration. This "AI-native DevOps" model ensures that every stage of the development process has clear Quality Gates, significantly reducing the uncontrollable risks of AI-generated code.
Comparison with Traditional AI Programming
| Dimension | Traditional AI Programming | Harness Engineering |
|---|---|---|
| Input | Simple prompts + minimal context | Complete specification system + multi-layered Skills |
| Execution | One-shot generation | Full-lifecycle automated pipeline |
| Control | Passively accepting results | Continuous interaction, feedback, and correction |
| Output | Code snippets | Complete features conforming to enterprise standards |
| Reproducibility | Low | High — specifications can be shared across teams |
Practical Recommendations and Reflections
The instructor mentioned that a partner enterprise has already successfully implemented multiple Harness Engineering projects with significant results. For developers looking to adopt this methodology within their teams, several points are worth noting:
First, establish specifications before writing code. The core of Harness isn't any particular tool — it's a complete system of constraints and specifications. The instructor's project comes with dozens of pages of specification documents: the first twenty or thirty pages cover theoretical concepts, followed by hands-on project content. Without a specification system, Harness is a castle in the air.
Second, Skills are reusable assets. Once a team develops a Skill system suited to their business scenarios, all subsequent projects can reuse it, with marginal costs decreasing over time. This aligns with the "componentization" and "platformization" philosophy in software engineering — the upfront investment is significant, but as reuse increases, ROI (Return on Investment) grows exponentially.
Third, model selection isn't the most critical factor. Even with domestic models paired with a well-designed Harness system, enterprise-level projects can be delivered. The value of the methodology far exceeds the capability differences between models.
Fourth, practice takes priority over theory. As the instructor noted, the abundance of Harness concept explanations online often leaves people "remembering the terms but unable to apply them." The recommendation is to learn by doing in real projects, using practice to build understanding of the theory.
Conclusion
Harness Engineering represents a qualitative shift in AI-assisted programming — from "tool" to "engineering discipline." It's no longer about simply having AI write a few lines of code for you. Instead, it's about building a complete specification system and automated pipeline that makes AI a controllable, predictable, and reusable engineering productivity force. From a technical evolution perspective, the underlying logic of this paradigm shift is clear: Prompt Engineering solved the problem of "how to talk to AI," Context Engineering solved the problem of "how to give AI the right background," and Harness Engineering ultimately solves the problem of "how to make AI deliver continuously according to engineering standards." For enterprise development scenarios like Java, this methodology is especially valuable — after all, what enterprise projects need most isn't flashy tricks, but deliverable, maintainable, and scalable engineering capabilities.
Related articles
The Ultimate Guide to Squeezing Every Drop from Mythos/Fable: Burning Through $8,000 in Inference Credits in 10 Days
Deep dive into maximizing Anthropic's Fable/Mythos model: 5-hour limit workarounds, dual account rotation, multi-Agent orchestration, and Mac Mini remote deployment to get $8,000 of inference from a $200 subscription.
Building a Travel Route Planning Mini-Program with AI in One Day: A Full Workflow from Design to Launch
Learn how to build a complete travel route planning WeChat Mini-Program in one day using AI tools like Modao AI and Cursor, covering UI design, code generation, debugging, and deployment.

How to Fix WeChat Mini Program Errors: A 3-Step AI Auto-Fix Method
Fix WeChat Mini Program errors without coding. Learn a practical 3-step method: save error logs, let AI IDE auto-analyze and fix, then recompile to verify.