Nex-N2 Pro In-Depth Review: Impressive Code Generation, But How Inflated Are the Benchmarks?
Nex-N2 Pro delivers impressive code generation but its benchmark claims don't hold up under independent testing.
Nex-N2 Pro is an open-source agent model from NestG that integrates reasoning, coding, and tool use into a unified loop. Hands-on testing reveals strong code generation — from MacOS clones to tower defense games — but independent benchmarks rank it 12th, far below the claimed top-five. Clear GPT distillation traces and slow generation speed are notable drawbacks, though it remains a valuable free option for developers.
A Uniquely Positioned Open-Source Agent Model
While all eyes are fixed on closed-source top-tier models like GPT and Gemini, the Chinese lab NestG has quietly released an ambitious open-source model series — Nex-N2. Its core proposition is simple: not just thinking, but acting.
Unlike traditional large models that handle coding, search, and tool invocation as separate capabilities, Nex-N2 attempts to integrate everything into a unified reasoning loop — decomposing goals, tracking state, adjusting strategies, and verifying results to form a complete agent closed loop. This design philosophy draws from the OODA loop (Observe-Orient-Decide-Act) in cognitive science and the Agent-Environment interaction paradigm in reinforcement learning. Traditional large language models work in a "one question, one answer" fashion — receive input, generate output, end of interaction. Agent models, by contrast, introduce a continuous reasoning loop: perceive the environment → analyze state → formulate a plan → execute actions → observe results → adjust strategy. In practice, this means the model won't stop at the first error it encounters. Instead, like an experienced engineer, it will trace back to analyze the cause of a bug, modify the code, retest, and iterate until the task is complete. This adaptive iterative capability is the core characteristic that distinguishes Nex-N2 from ordinary conversational models.
This design targets the most complex real-world work scenarios: where you need to simultaneously retrieve background information, write code, invoke tools, debug errors, revise plans, and ultimately verify outputs.
Model Specifications: Two Products for Different Needs
The Nex-N2 series includes two models targeting different use cases:
- Nex-N2 Mini: Based on MoE architecture, with 35 billion total parameters and approximately 3 billion active parameters, suitable for local deployment and lightweight scenarios.
- Nex-N2 Pro: The flagship version, with 39.7 billion total parameters and 17 billion active parameters, built on the Qwen 2.5 architecture. It supports text and image inputs and is capable of reasoning, function calling, and structured output.
MoE Architecture: Leveraging Larger Models with Less Compute
MoE (Mixture of Experts) is an efficient model architecture design whose core idea is to divide the model into multiple "expert" sub-networks, activating only a subset of them for each input rather than having all parameters participate in computation simultaneously. This is why Nex-N2 Mini has 35 billion total parameters but only about 3 billion active parameters — at any given moment, less than one-tenth of the parameters are actually working. The advantage of this design is that the model can have the knowledge capacity of a large model while maintaining the inference speed and computational cost of a small one. Well-known models like DeepSeek and Mixtral also employ similar architectures. For local deployment scenarios, MoE architecture means users can run a "nominally" large model on consumer-grade hardware, with actual VRAM and compute requirements far lower than a dense model of equivalent parameter size.
Standing on the Shoulders of Qwen 2.5
Nex-N2 Pro's choice to build on the Qwen 2.5 architecture is a deliberate one. Qwen 2.5 is an open-source large language model series from Alibaba's Tongyi Qianwen team, highly regarded in the open-source community, particularly for its Chinese-English comprehension, long-context handling, and instruction-following capabilities. Building on a mature base model for secondary development is an extremely common practice in the open-source AI space — it allows R&D teams to focus their efforts on building differentiated capabilities (such as agent reasoning loops, tool invocation, etc.), significantly shortening development cycles and reducing training costs.
262K Context Window: Critical Support for Long-Horizon Tasks
In terms of context window, the Pro version supports an ultra-large context of 262K tokens, which is a key advantage for handling long-horizon agent workflows. The context window refers to the maximum text length a model can "remember" and process within a single conversation. 262K tokens is roughly equivalent to a medium-length book, or the combined content of dozens of code files. For agent workflows, an ultra-large context window is crucial: when a model needs to repeatedly retrieve information, write code, debug errors, and revise plans within a complex task, it must be able to "remember" the complete history and all intermediate states of the entire task. If the context window is too small, the model will "forget" critical early information during long-horizon tasks, causing the reasoning chain to break. By comparison, GPT-4 Turbo has a context window of 128K tokens and Claude 3.5 has 200K tokens — Nex-N2 Pro's 262K is among the leaders in the current market.
The NestG team also announced that Nex-N2 Pro is available for two weeks of free use, with unlimited access for users.
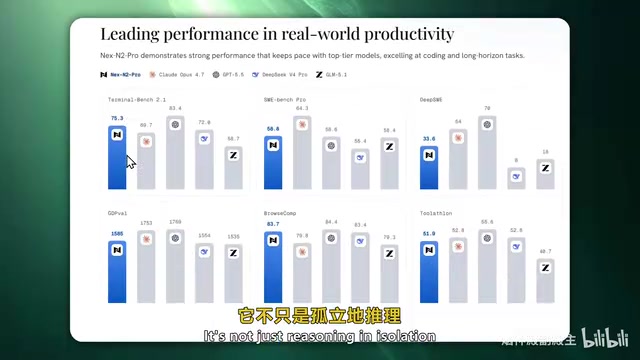
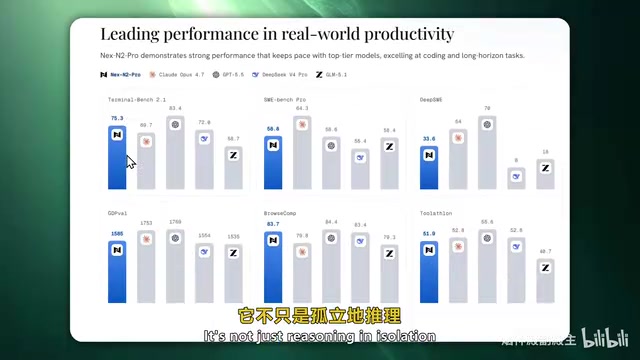
Official Benchmarks: Impressive Numbers That Warrant Scrutiny
According to the official benchmark data published by the NestG team, Nex-N2 Pro's performance is indeed noteworthy:
- Terminal Bench: 75.3 points
- SWE Bench Pro: 58.8 points
- GPT-EVAL: 1500 points
- Browser Benchmark: Close to 1600 points, even outperforming OP4.7
- Deep Search Tasks: Surpassing Timmy K2.6
Understanding What These Benchmarks Mean
These benchmarks each have different focuses, and together they can provide a relatively comprehensive picture of an agent model's actual capability boundaries. Among them, SWE Bench is a software engineering benchmark created by a Princeton University research team. It extracts real bug-fix tasks from actual GitHub open-source projects, requiring models to understand codebases, locate issues, and generate correct fix patches. It is widely regarded as the gold standard for measuring AI's practical programming ability. SWE Bench Pro is its higher-difficulty variant. Terminal Bench focuses on evaluating a model's ability to execute complex command-line operations in terminal environments, including file management, system configuration, script writing, and more. GPT-EVAL is an automated evaluation framework that uses GPT models as judges, quantifying quality by having a strong model score the outputs of the model being tested.
The official claim is that it ranks in the top five overall, capable of going head-to-head with closed-source giants like DeepSeek V4 Pro and Gemini. If true, this would indeed be a milestone breakthrough for an open-source model. However, subsequent independent testing revealed different conclusions.
Hands-On Testing: Code Generation Capabilities Are Impressive
Frontend Interface Generation
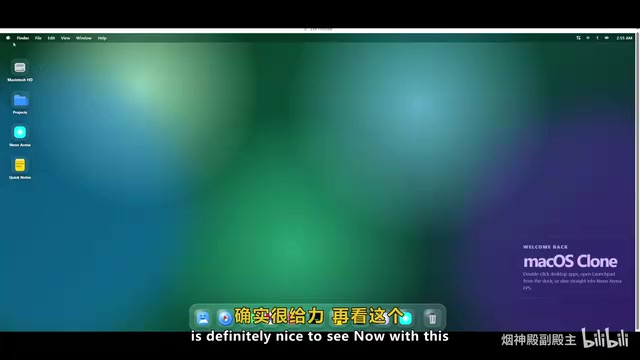
In practical testing, Nex-N2 Pro demonstrated remarkably strong code generation capabilities. When asked to generate a MacOS clone interface, the results showed quite good frontend output quality — beautiful SVG icons with most application components properly in place. While some interactive features (like the top menu) couldn't be fully implemented, the overall visual effect had already reached GPT-level quality.
Game and Complex Application Development
In a tower defense game generation test, Nex-N2 Pro not only produced a fully functional game but one that ran smoothly with excellent overall performance. One notable detail, however: the UI style of its control panel bore obvious GPT hallmarks — the color scheme, fonts, and overall look and feel were virtually identical to GPT model outputs.

Windows 95 Operating System Recreation
One of the most impressive tests was the recreation of the Windows 95 operating system. Nex-N2 Pro did an outstanding job with detail reproduction: icon code, Start menu, Paint, Minesweeper, Internet Explorer, Calculator, MS-DOS Prompt — all the classic components were present and accounted for, with most features actually interactive. This level of code generation capability in such a complex scenario fully demonstrates its comprehensive strength as an agent model.
SVG Graphics Generation
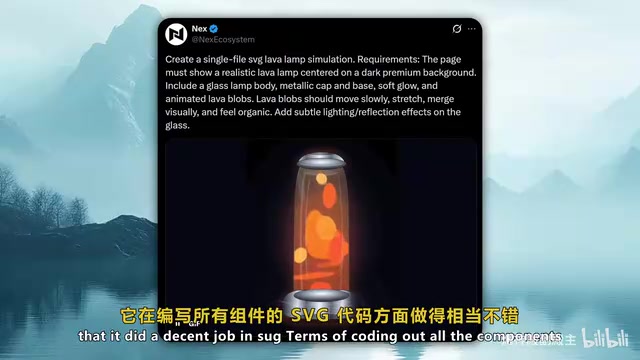
In an SVG lava lamp simulation test, Nex-N2 Pro generated lava ball animations with reasonable physics effects, including slow movement and glow effects. The quality of the SVG code output was quite good.
Points of Controversy: Benchmark Inflation and Distillation Traces
Independent Test Rankings Far Below Official Claims
Despite the impressive official numbers, independent benchmark testing revealed an inconvenient truth: Nex-N2 Pro's actual performance shows a significant gap from official claims. In independent testing, the model ranked only 12th — far from the "top five" level the team claimed.
Testers explicitly noted: "Its benchmark performance is indeed somewhat inflated. The official claim is a top-five ranking, but I don't think that's the case." This reminds us that when evaluating any model, we should reference multiple independent test results. It's worth noting that benchmark "inflation" is not an isolated case in the AI industry — model developers may embellish their scores through optimization training on specific test sets, selective reporting of favorable data, or using non-standard test configurations. This is precisely why independent third-party evaluations are becoming increasingly valued in the AI field.
Obvious GPT Distillation Traces
Another issue that has sparked widespread discussion is that Nex-N2 Pro's output style is highly similar to GPT models. From the generated frontend interfaces and code structures to UI design elements, clear GPT-style fingerprints are visible throughout. This strongly suggests that the model distilled GPT output data during post-training.
Knowledge Distillation is a classic model compression and knowledge transfer technique in machine learning, first proposed by Geoffrey Hinton and colleagues in 2015. Its basic principle is to have a smaller "student model" learn to mimic the output distribution of a larger "teacher model." In the era of large models, the meaning of distillation has expanded: many teams collect output data from top closed-source models like GPT-4 and Claude, using it as training data to fine-tune their own open-source models. This approach is technically effective — the student model can indeed learn the teacher model's output style and some reasoning capabilities — but it also raises controversies about intellectual property, model independence, and capability ceilings. Distilled models often perform well on tasks where the teacher model excels, but may show obvious capability gaps in areas the teacher model doesn't cover.
From a user perspective, this isn't necessarily a bad thing — it means you can get generation quality close to GPT level for free. But it also explains why it performs amazingly in certain specific demos while still falling short in more comprehensive and rigorous evaluations.
Generation Speed Bottleneck
Due to its adaptive thinking approach, Nex-N2 is very slow when generating output. It engages in planning, logical reasoning, and iterative verification — an ideal closed-loop design for agent workflows, but if you're looking for fast responses, the user experience takes a significant hit. This trade-off between speed and quality fundamentally reflects a core tension in the current AI field: OpenAI's o1/o3 series models face the same issue — deeper "thinking" inevitably requires more computation time. For scenarios requiring real-time interaction (like chat conversations), this is a clear disadvantage; but for complex tasks that allow longer wait times (like code project development or in-depth research reports), the extra reasoning time often translates to significantly higher output quality.
Objective Assessment: Underrated but Shouldn't Be Overhyped
Overall, Nex-N2 Pro is an impressive, practically valuable open-source agent model. Its core strengths include:
- Unified agent framework: Integrates coding, search, and tool invocation into the same reasoning loop
- Excellent code generation capabilities: Solid generation quality for frontend interfaces, games, and complex applications
- Fully open-source and free: Lowers the barrier to entry, allowing the community to freely deploy and fine-tune
- Local deployment friendly: The Mini version runs reliably even on older Mac devices
However, it's important to soberly recognize its shortcomings: official benchmark data is inflated, actual comprehensive performance hasn't reached the very top tier; output style is heavily dependent on GPT distillation; and generation speed is slow.
From a broader perspective, the emergence of Nex-N2 reflects an important trend in the open-source AI ecosystem: more and more teams are no longer content with building pure conversational models, instead turning their attention toward the more practically valuable agent direction. With the rise of agent frameworks like Manus, OpenHands, and AutoGPT, base models that natively support tool invocation and multi-step reasoning will become increasingly important. While Nex-N2 still has shortcomings in certain areas, it represents the open-source community's active exploration in the cutting-edge direction of agent models.
For developers and AI enthusiasts, Nex-N2 Pro is absolutely worth trying — after all, getting this level of agent capability for free is inherently valuable. But when assessing its true capabilities, it's advisable to reference multiple independent test results rather than blindly trusting official data.
Related articles

Codex VS Claude Code: The Token Economics Behind a 10x Price Gap
Same coding task: Codex costs $15, Claude Code costs $155. Deep dive into the real reasons behind the 10x gap — it's not pricing, it's token volume, output style, and context strategy.
Gemma 4 Open-Source Model Local Deployment Guide: Ollama Installation & Mobile Setup
Step-by-step guide to deploying Google's Gemma 4 open-source model locally with Ollama and running the lightweight version on mobile with tool calling support.
The Decline of Tokenmaxxing: Why Selling Outcomes Matters More Than Selling Tokens
The Tokenmaxxing craze is fading as enterprise AI procurement shifts from chasing Token counts to focusing on actual business outcomes. Learn why outcome-based AI evaluation is the right approach.