Qwen3-Coder Deep Dive: A Coding Model Built for Long-Horizon Agent Loops
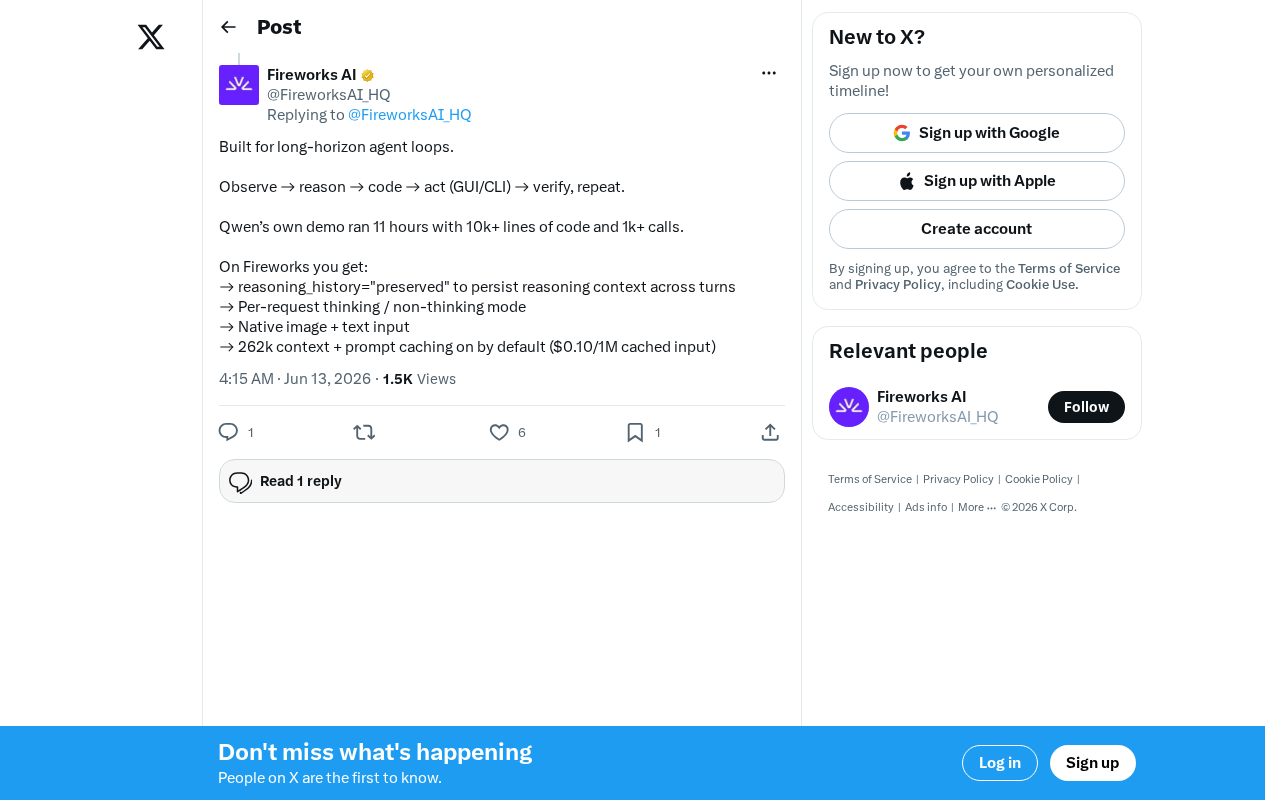
Qwen3-Coder is purpose-built for long-horizon agentic coding loops with 11-hour continuous operation capability.
Qwen3-Coder is designed for sustained agentic coding loops, demonstrated by 11 hours of continuous operation generating 10,000+ lines of code across 1,000+ calls. Deployed on Fireworks, it leverages reasoning context persistence, flexible thinking mode switching, multimodal input, a 262K context window, and prompt caching to make long-horizon autonomous coding both technically robust and economically viable.
Core Positioning: Built for Long-Horizon Agentic Loops
The recently released Qwen3-Coder model has a very clear positioning — designed for long-running agentic loop tasks. Its core workflow can be summarized as a continuously iterating closed loop:
Observe → Reason → Code → Act (via GUI/CLI) → Verify → Repeat
The agentic loop is one of the core paradigms in current AI system design, drawing inspiration from the OODA loop (Observe-Orient-Decide-Act) in cognitive science. Unlike traditional single-turn inference, agentic loops require models to have sustained state management capabilities, error recovery mechanisms, and dynamic planning abilities. In software engineering, this pattern corresponds to a developer's real workflow in an IDE — constantly switching between editing, running, and debugging, where each decision depends on feedback from previous steps.
This is not a simple "Q&A-style" code generation model, but rather an intelligent agent engine capable of sustained autonomous operation on complex tasks. Qwen's official demo was impressive: the model ran continuously for 11 hours, generated over 10,000 lines of code, and made more than 1,000 API calls. These numbers clearly demonstrate Qwen3-Coder's stability and endurance in long-horizon tasks.
Why Long-Horizon Agent Capabilities Are the Key Breakthrough in AI Coding
The AI coding field is currently undergoing a critical shift: from "single-turn code completion" to "autonomously completing complex engineering tasks." In real-world software development, implementing a feature often requires dozens or even hundreds of steps — understanding requirements, designing architecture, writing code, debugging errors, running tests, fixing issues, and repeating the cycle.
Traditional code generation models perform well in single-turn conversations, but once the task chain extends, they face problems like context loss and reasoning chain fragmentation. Specifically, "context loss" refers to the model gradually forgetting critical early information (such as requirement constraints and architectural decisions) during multi-turn interactions, while "reasoning chain fragmentation" means the model cannot maintain a consistent logical reasoning path across multiple calls — the analytical conclusions from one step fail to effectively carry over to subsequent steps. Both problems deteriorate rapidly as task complexity and duration increase.
Qwen3-Coder's design philosophy directly targets this pain point: enabling the model to maintain coherent thinking and execution capabilities during extended development sessions, just like a real developer would.
Fireworks Platform Deployment: Key Technologies Supporting Long-Horizon Agents
When deploying Qwen3-Coder on the Fireworks inference platform, several key technical capabilities make long-horizon agentic loops truly practical.
Reasoning Context Persistence
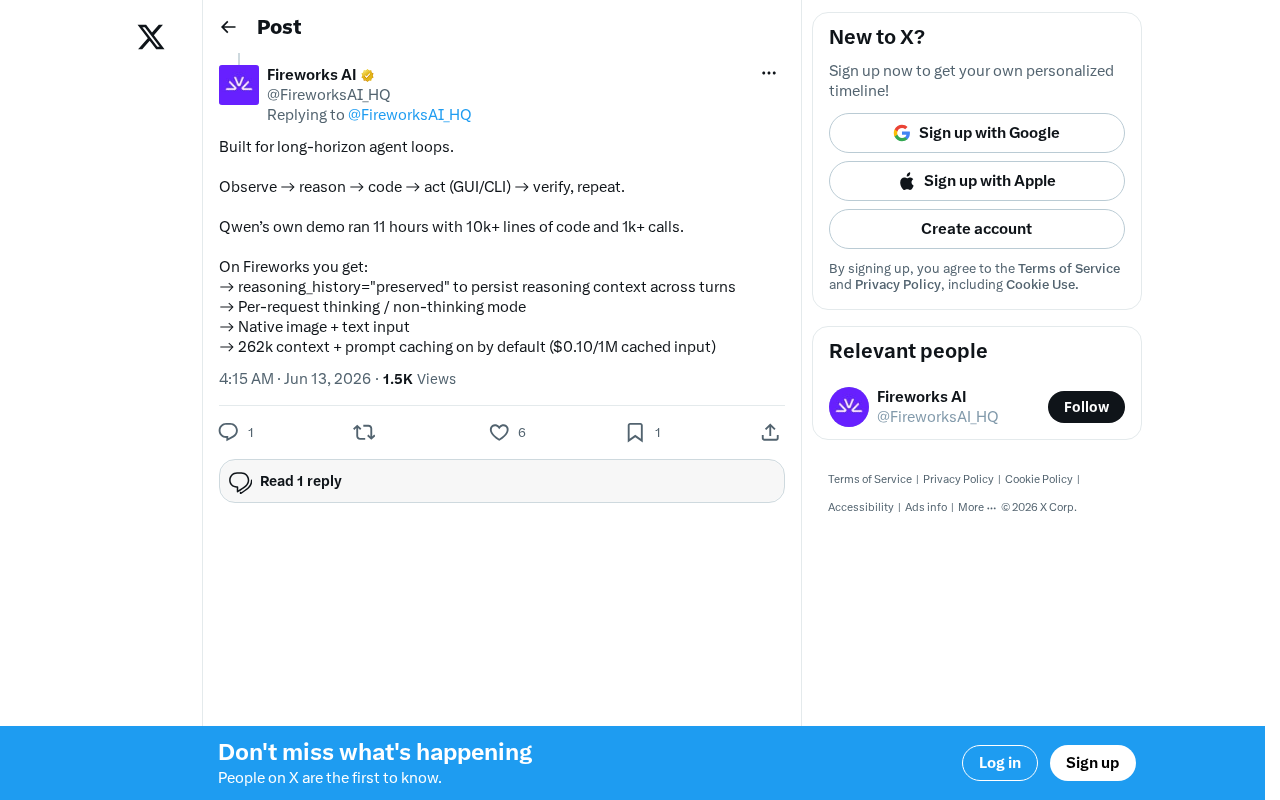
Through the reasoning_history="preserved" parameter, the model can maintain reasoning context across turns. This means that during an agent session lasting several hours, the model won't "forget" its previous reasoning processes and decision logic. This is the core technical foundation that supports coherence across 1,000+ calls.
From a technical perspective, reasoning context persistence solves the "chain-of-thought fragmentation" problem in multi-turn LLM interactions. In standard API call patterns, the model's internal reasoning process (Chain-of-Thought) is typically not preserved for the next conversation turn, forcing the model to re-"understand" the entire task context in subsequent calls. By persisting the reasoning history, the model's intermediate reasoning steps are explicitly saved and passed as context in subsequent calls, maintaining logical coherence across turns. This is similar to the "mental model" developers maintain while working — even when interrupted, they can quickly resume their previous train of thought.
Flexible Thinking Mode Switching
The platform supports per-request switching between thinking and non-thinking modes. At complex decision points requiring deep reasoning, thinking mode is enabled for in-depth analysis; during simple execution steps, thinking mode is disabled to save time and computational cost. This flexibility is crucial for efficiency optimization in long-horizon tasks.
This design draws from the "System 1/System 2" dual-process cognitive theory. Daniel Kahneman proposed in Thinking, Fast and Slow that human cognition is divided into fast, intuitive System 1 and slow, deliberative System 2. In an AI Agent's long-horizon tasks, not every step requires deep reasoning — for example, executing a predetermined file write operation only needs a quick response, whereas encountering a complex architectural decision or a hard-to-locate bug requires mobilizing more computational resources for in-depth analysis. This dynamic resource allocation strategy not only improves efficiency but also significantly reduces the overall computational cost of long-horizon tasks. During 11 hours of continuous operation, if every step involved deep reasoning, the computational overhead would be unacceptable.
Multimodal Input and Ultra-Long Context Window
The model natively supports image + text mixed input, meaning the agent can process not only code text but also understand GUI screenshots, error interfaces, and other visual information, achieving a true "observe → act" closed loop.
A 262K context window combined with Prompt Caching enabled by default (cached input at just $0.10/million tokens) provides ample "memory space" for long-horizon tasks while keeping the cost of repeated context extremely low.
A 262K token context window is roughly equivalent to the information content of a medium-length technical book, or the complete code of dozens of core files in a mid-sized software project. In practical agent coding scenarios, the context window needs to simultaneously accommodate: system prompts and tool definitions, accumulated conversation history, the code file content currently being processed, and test outputs and error logs. Traditional 4K-32K windows quickly "overflow" in complex projects, forcing the system to truncate or summarize information, leading to critical context loss. The 262K window provides ample "working memory" space for long-horizon tasks, enabling the agent to run continuously for hours without losing critical information.
Cost and Practicality: Economic Viability of Long-Horizon Agents
Using the official demo's 11 hours and 1,000+ calls as a reference, enabling Prompt Caching by default is a very pragmatic design decision. In long-horizon agentic loops, large amounts of system prompts and historical context are repeatedly passed in with each call. The caching mechanism compresses this portion of the cost to extremely low levels ($0.10/million tokens), making long-running coding agents economically viable.
The core principle of Prompt Caching is: when multiple API calls share the same prefix content (such as system prompts, tool definitions, and conversation history), the platform caches the KV Cache (key-value cache) corresponding to these prefixes, avoiding redundant computation of intermediate states in the attention mechanism. In long-horizon agent scenarios, system prompts and accumulated conversation history may occupy tens or even hundreds of thousands of tokens. If recalculated with every call, both latency and cost would grow linearly. The caching mechanism reduces this overhead from "compute every time" to "compute once + reuse many times," serving as critical infrastructure for supporting the economic viability of high-frequency calls.
For enterprise application scenarios, this means you can confidently let Qwen3-Coder execute time-consuming development tasks without worrying excessively about inference costs spiraling out of control. Consider a typical long-horizon coding task: assuming each call averages 50K tokens of repeated prefix, 1,000 calls means 50 million tokens of redundant computation — without caching, this would generate significant costs; with the caching mechanism, this portion costs only about $5, making "letting AI run overnight" an entirely economically viable option.
Industry Significance: Evolution from Assistive Tool to Autonomous Coding Agent
The release of Qwen3-Coder marks the evolution of AI coding tools from "assistive tools" to "autonomous agents." The ability to run continuously for 11 hours means we're one step closer to a workflow where you hand off a complete development task to AI and collect the results the next morning.
This evolutionary path can be clearly divided into several stages: The first stage is code completion (like early GitHub Copilot), where the model predicts the next code segment at the cursor position. The second stage is conversational coding assistants, where developers describe requirements in natural language and the model generates code snippets. The third stage is autonomous coding agents, where the model can independently complete the entire process from requirement understanding to code delivery, including autonomous debugging and testing. Qwen3-Coder sits at the critical transition point from the second to the third stage, and its long-horizon running capability is one of the necessary conditions for achieving truly autonomous programming.
Of course, the reliability of long-horizon agents, their error recovery capabilities, and their performance in real-world complex projects still require validation across more practical scenarios. The core challenges the industry currently faces include: error accumulation effects (an early wrong decision may be amplified in subsequent steps), dead loop detection (the agent may get stuck repeatedly attempting the same failed approach), and defining human-AI collaboration boundaries (when should the agent pause and request human intervention). However, from a technical roadmap perspective, Qwen3-Coder demonstrates a clear and exciting direction — AI coding is moving from "conversational assistance" toward "autonomous execution."
Related articles
Frontend to AI Agent Architect: A Complete 3-Month Learning Roadmap
How can frontend engineers transition to AI Agent development? A systematic 3-month roadmap covering AI concepts, model selection, team productivity, and Agent architecture.

Replit CEO on the Rise of AI-Native Developers: Future Companies Will Have Only Builders and Sellers
Replit closes $400M Series D at $9B valuation. CEO Amjad shares insights on vibe coding, Agent 4 parallel agents, cross-platform deployment, and how AI is reshaping companies and software development.
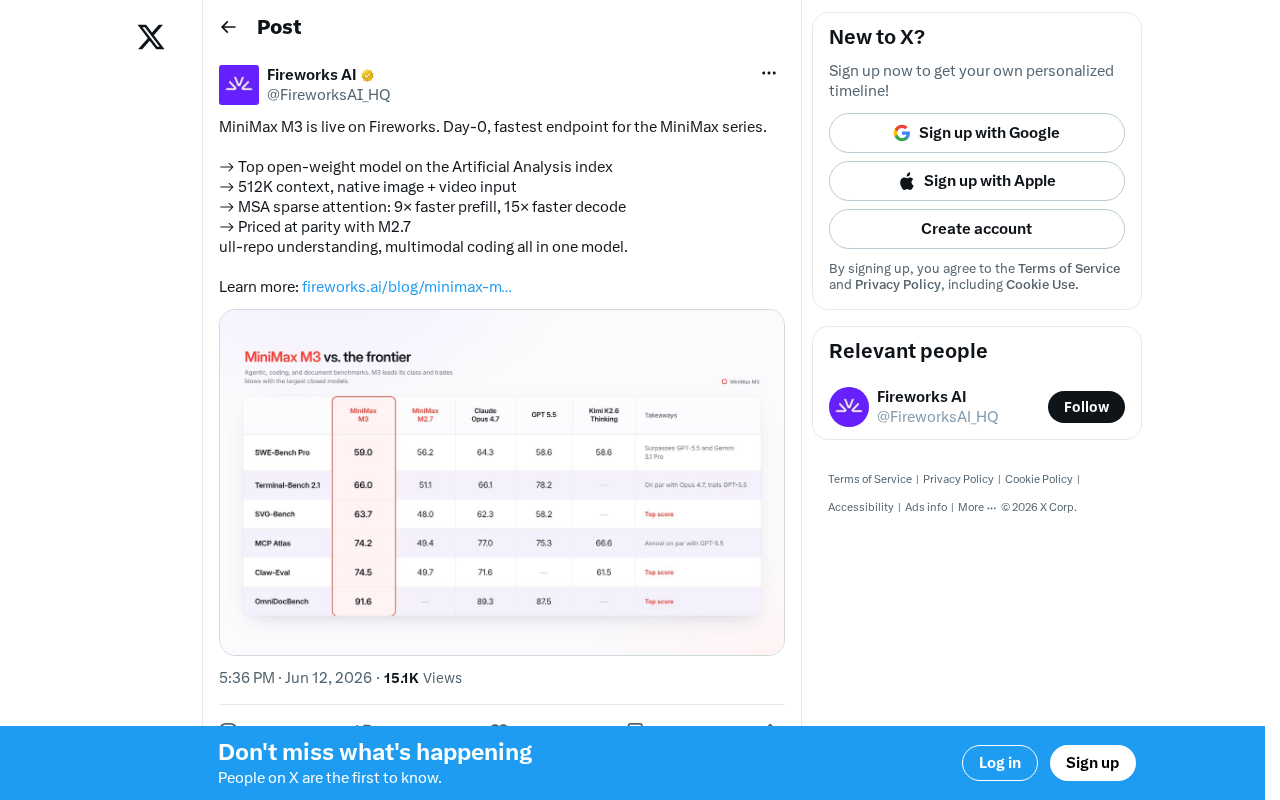
MiniMax M3 Launches on Fireworks: 512K Context and MSA Sparse Attention Explained
MiniMax M3 launches on Fireworks with 512K context and multimodal input. MSA sparse attention delivers 9x prefill and 15x decode speedups. Deep dive into architecture, pricing, and open-model competition.