What It Means That Claude Mythos Preview Outperforms Human Researchers in 64% of Research Decisions
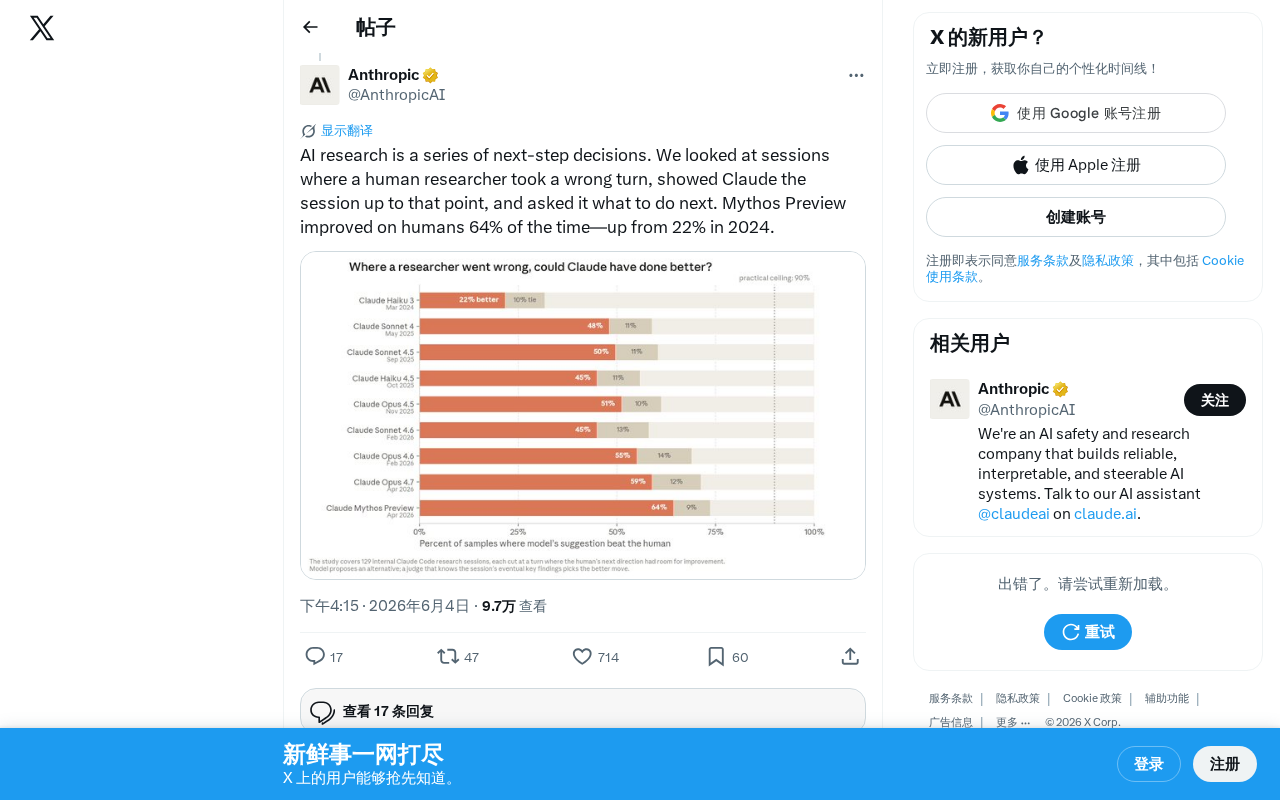
Claude Mythos Preview surpasses human researchers in 64% of research decisions, tripling last year's 22%.
Anthropic's Claude Mythos Preview model now makes better research decisions than human researchers 64% of the time, up from just 22% in 2024. This near-threefold improvement signals that AI has crossed a critical threshold from occasional reference tool to reliable strategic advisor in research. The result has implications for recursive self-improvement, human-AI collaboration frameworks, and the future organization of AI research teams.
AI Research Decision-Making: Outperforming Human Researchers 64% of the Time
Anthropic recently unveiled a striking research finding: in tests evaluating "next-step decisions" during the AI research process, the Claude Mythos Preview model made better judgments than human researchers 64% of the time. Compared to the 22% figure from 2024, this represents nearly a threefold leap.
The test design itself is highly illuminating — AI research is essentially a chain of "what should I do next" decisions. The research team identified real cases where human researchers had "gone in the wrong direction" during their work, presented the complete research log up to the point of error to Claude, and then asked what it would do next.
In machine learning research, a typical project may involve hundreds of micro-decision points. The quality of these decisions directly determines research efficiency — what the field commonly calls "research taste" is fundamentally the ability to make high-quality directional judgments under incomplete information. The gap between top-tier and average researchers often lies not in coding ability or mathematical foundations, but in this intuition for "choosing the right problem and the right approach." Anthropic's test is precisely an attempt to quantify this capability that was previously considered nearly impossible to measure.
Why the Evaluation Method Deserves Attention
The elegance of this evaluation method lies in the dimension it focuses on. Traditional AI capability benchmarks typically measure end results — whether a model can solve a particular problem or complete a specific task. But Anthropic's test focuses on judgment during the process, which much more closely mirrors real scientific research scenarios.
Claude Mythos Preview is a model variant specifically optimized by Anthropic for AI research tasks. Unlike general-purpose conversational models, these specialized models typically feature targeted adjustments in training data composition, reasoning chain length, and domain-specific fine-tuning strategies. The "Preview" label indicates this is still an experimental version; Anthropic's decision to publish these interim results both showcases technical progress and sets community expectations for a subsequent official release.
In day-to-day AI research, researchers face a constant stream of branching choices:
- Which hyperparameter should I tune?
- What architecture should I switch to?
- Which paper should I read next?
- Is the current direction still worth pursuing?
The decision complexity behind these choices runs far deeper than it appears. Take hyperparameter tuning as an example: the combinatorial space of learning rate, batch size, regularization strength, and other parameters grows exponentially, and traditional methods like grid search or Bayesian optimization can only explore a limited number of dimensions. Architecture selection presents an even broader decision space — from the number of Transformer layers and attention heads to whether to introduce a Mixture of Experts (MoE) structure, each choice can lead to dramatically different training outcomes. A senior researcher's core value lies largely in the ability to rapidly narrow this search space through experience.
A single wrong directional decision can waste days or even weeks. The capabilities demonstrated by Claude Mythos Preview suggest that AI can now provide substantive assistance in these high-level strategic judgments.
From 22% to 64%: What Happened in One Year
In 2024, Claude outperformed humans in only 22% of cases in similar tests. This meant that at the time, human researchers' intuition and experience were still more reliable in the vast majority of situations. But in just one year, that figure jumped to 64% — AI has gone from being an "occasionally useful reference" to a "superior advisor in most cases" when it comes to research decision-making.
The pace of this improvement is itself a significant signal, revealing several key trends:
The practical value of AI-assisted research has crossed a critical threshold. When AI can offer better advice in more than half of all cases, incorporating it into the research workflow is no longer optional — it's a necessary component of competitiveness.
The self-acceleration effect of AI research may be emerging. Stronger AI helps researchers make better decisions, which in turn accelerates the iterative evolution of AI itself, creating a positive feedback loop. This effect is known in academia as "recursive self-improvement" and is one of the central concerns in AI safety research. The basic logic is: if AI system A can help create a stronger AI system B, and B can create an even stronger C, this could produce exponential capability growth. Anthropic, as a leading institution in AI safety research, maintains high vigilance regarding this phenomenon. Part of the reason the 64% figure has attracted widespread attention is that it hints this self-acceleration loop may have already begun — though it currently remains within the range of human oversight.
The role of human researchers is undergoing a transformation. Shifting from independent decision-makers to collaborative decision-makers working alongside AI, the ability to judge "when to adopt AI's advice" is itself becoming a core competency.
Practical Implications for the AI Research Paradigm
The deeper significance of this result is that AI is evolving from an "execution tool" into a "strategic advisor." In the past, when we discussed AI-assisted coding or AI-assisted writing, the focus was on efficiency gains at the execution level. Research decision-making, however, belongs to a higher tier of cognitive activity, involving understanding of the problem space, evaluation of viable paths, and weighing of risks against rewards.
You might not have noticed, but the 64% advantage rate also means that human judgment is still superior in 36% of cases. This data points toward a best practice of human-AI collaboration rather than complete reliance on AI:
- Let AI provide decision recommendations and alternative scenario analyses
- Have experienced researchers make the final call
- Pay special attention to critical junctures that require deep domain intuition
Beyond AI research, human-AI collaborative decision-making already has mature applications in fields like medical diagnostics and financial risk management. Studies show that the optimal collaboration model is often not a simple "AI suggests + human approves" workflow, but rather requires carefully designed complementary mechanisms. For example, in radiology AI-assisted diagnosis, when AI confidence is extremely high or extremely low, its judgment can be adopted directly, while the interval where human doctors add the most value is the "uncertain" middle ground. Similar frameworks are being introduced into AI research workflows: letting AI handle the pattern-matching decisions it excels at, while reserving decisions that require cross-domain analogical reasoning or counterintuitive innovation for humans.
Where This Trend Is Heading
The leap from 22% to 64% happened within a single year. If this trend continues, AI comprehensively surpassing humans in research decision-making may not be far off. This would profoundly reshape how AI research is organized — team sizes, decision-making processes, and resource allocation may all need to be redesigned.
At the same time, this raises important questions about the boundaries of AI's autonomous research capabilities: when AI can not only execute research tasks but also consistently make superior judgments at the strategic level, where exactly does human irreplaceability in the research process lie? The answer to this question may well define the direction of AI research for years to come.
Related articles
Complete Guide to Codex Installation & DeepSeek Integration Troubleshooting
Complete troubleshooting guide for Codex installation and DeepSeek API integration, covering 401/402/502 errors, model display issues, startup failures, and a universal fix.

Anthropic Sales Rep Builds AI Tools with Claude, Transforms from Account Executive to GTM Architect
Anthropic account exec Jared built Clasps, an AI email tool using Claude and RAG architecture, saving 2-3 hours daily and transforming into a GTM Architect.
v0 Snowflake Integration Enters Public Preview: Generate Data Dashboards with Natural Language
Vercel's v0 announces public preview of Snowflake integration, enabling users to connect data sources and auto-generate professional dashboards using natural language prompts.