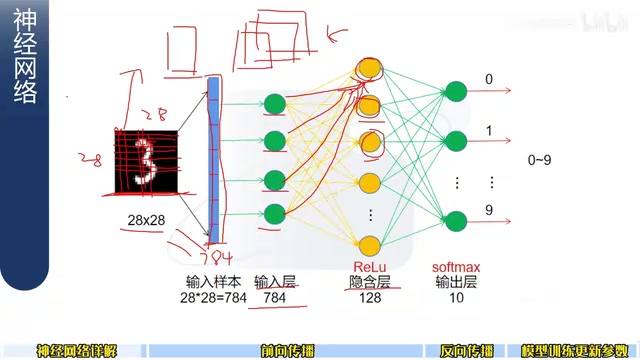
#前向传播
共 59 篇相关文章
Claude Code记不住进度?手搓一个进度Skill解决
·9 分钟
Claude Code记不住进度?手搓一个进度Skill解决
详解如何为Claude Code创建进度Skill,通过skill.md文件实现开发进度的保存与恢复,解决新对话丢失上下文的痛点。包含完整的Skill文件结构、元信息配置和实战演示。
阅读全文 →

·9 分钟
vLLM深度解析:PagedAttention如何实现高吞吐量LLM推理
深入解析vLLM高吞吐量LLM推理引擎的核心技术,包括PagedAttention内存管理、连续批处理机制、分布式部署方案,以及与TensorRT-LLM等方案的对比和适用场景建议。
阅读全文 →
 教程攻略
教程攻略·8 分钟
阿里云百炼平台实战:API调用到多轮对话完整教程
详细讲解阿里云百炼平台的使用方法,包括API Key获取、通义千问模型调用、流式输出实现、多轮对话原理及提示词工程四种角色设定,附完整代码示例,帮助开发者快速上手大模型应用开发。
阅读全文 →
 行业洞察
行业洞察·6 分钟
互联网大厂AI资本开支集体扩张,算力基建产业链六大受益方向解析
国内互联网巨头集体加码AI资本开支,算力基建从预期进入兑现阶段。深度解析AI数据中心、算力芯片、存储互联、国产替代等六大产业链受益方向及投资逻辑。
阅读全文 →
 教程攻略
教程攻略·9 分钟
零基础机器学习入门:从概述到实战的完整学习路径
零基础机器学习入门教程,涵盖AI概述、NumPy、Pandas、Matplotlib三大Python库及实战案例。通过五大模块系统学习,三天掌握机器学习基础知识体系,适合完全没有编程背景的初学者。
阅读全文 →
 产品体验
产品体验·9 分钟
Google Gemma 4实测:手机离线运行+Ollama部署教程
实测Google Gemma 4开源模型在三台手机上的离线运行表现,详解Dense与MOE架构区别,附Ollama + Claude Code完整部署教程。从1B到31B四款模型覆盖手机到工作站全场景,4GB显存即可运行。
阅读全文 →
 教程攻略
教程攻略·10 分钟
llama.cpp MTP加速部署指南:配置步骤与性能实测
详解llama.cpp如何启用MTP多Token预测加速技术,涵盖CUDA环境配置、桌面端设置、模型选择及实测性能数据,Qwen3 27B实测近60 Token/s。
阅读全文 →
 教程攻略
教程攻略·4 分钟
AI大模型学习路线:从零到工程师的六个阶段
系统梳理AI大模型工程师学习路线,涵盖Transformer基础、提示词工程、RAG检索增强生成、Agent智能体开发、API调用、微调部署到项目实战六大阶段,帮助开发者高效掌握大模型核心技能。
阅读全文 →
 深度解读
深度解读·10 分钟
Transformer架构核心原理:自注意力机制与工程优化深度解析
深度解析Transformer架构核心原理,涵盖自注意力机制QKV本质、Encoder-Decoder结构、Flash Attention显存优化、RoPE位置编码、GQA推理加速等工程落地方案,助你从面试到实战全面掌握大模型底层架构。
阅读全文 →
 教程攻略
教程攻略·9 分钟
oMLX+MTP+Qwen3.6:本地AI编程速度突破新极限
使用oMLX推理引擎结合MTP多令牌预测技术和Qwen3.6 35B模型,在Apple Silicon Mac上实现86.7 tokens/s的本地编程速度,5分钟内完成全栈应用开发的完整实战解析。
阅读全文 →
 行业洞察
行业洞察·8 分钟
AI账号轮换工具的风险揭秘:灰产背后的安全隐患
深度解析AI额度破解工具的运作模式,揭示账号轮换灰产背后的法律合规风险、数据泄露隐患,并提供API付费、订阅升级等正当替代方案。
阅读全文 →
 行业洞察
行业洞察·7 分钟
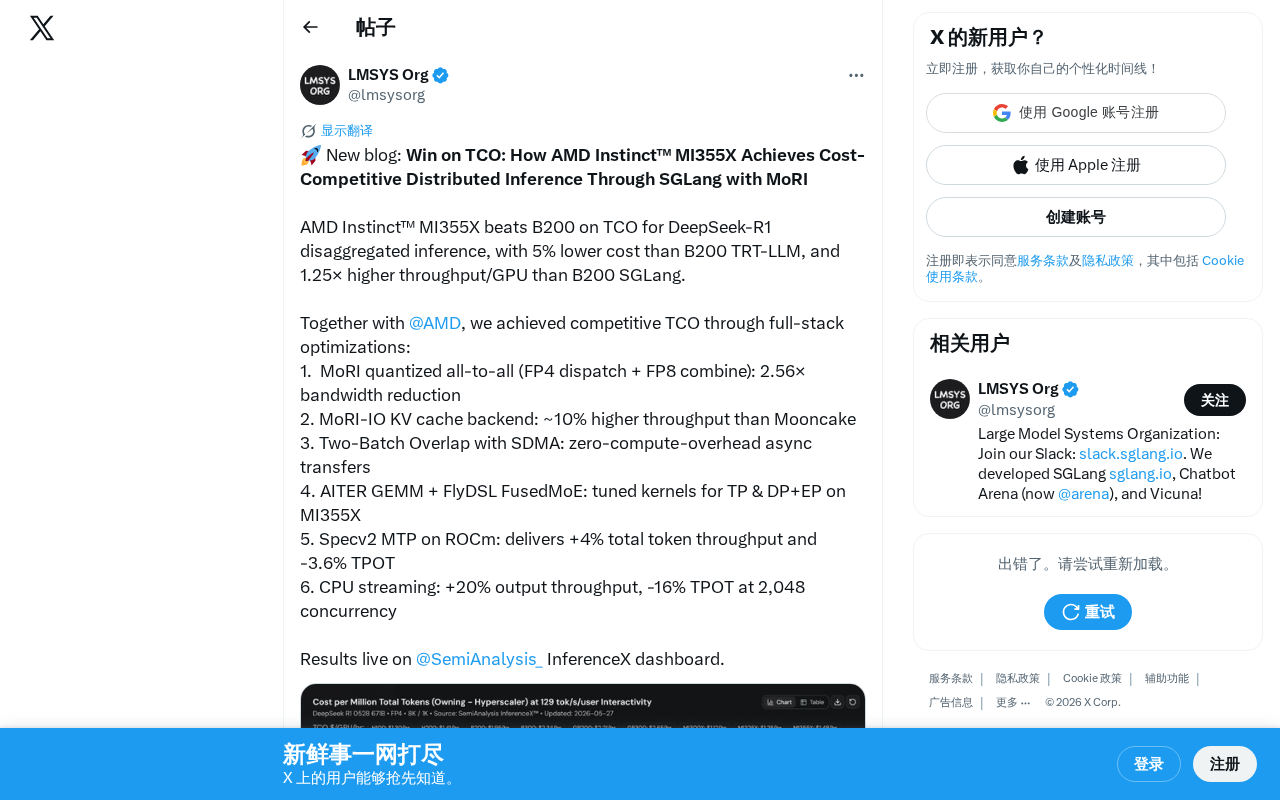
AMD MI355X击败B200:DeepSeek-R1推理TCO低5%的全栈优化解析
AMD Instinct MI355X通过SGLang+MoRI全栈优化,在DeepSeek-R1分离式推理中实现TCO比NVIDIA B200低5%,每GPU吞吐量高1.25倍。深度解析MoRI量化通信、KV Cache优化及推测解码等核心技术突破。
阅读全文 →
 科技前沿
科技前沿·6 分钟
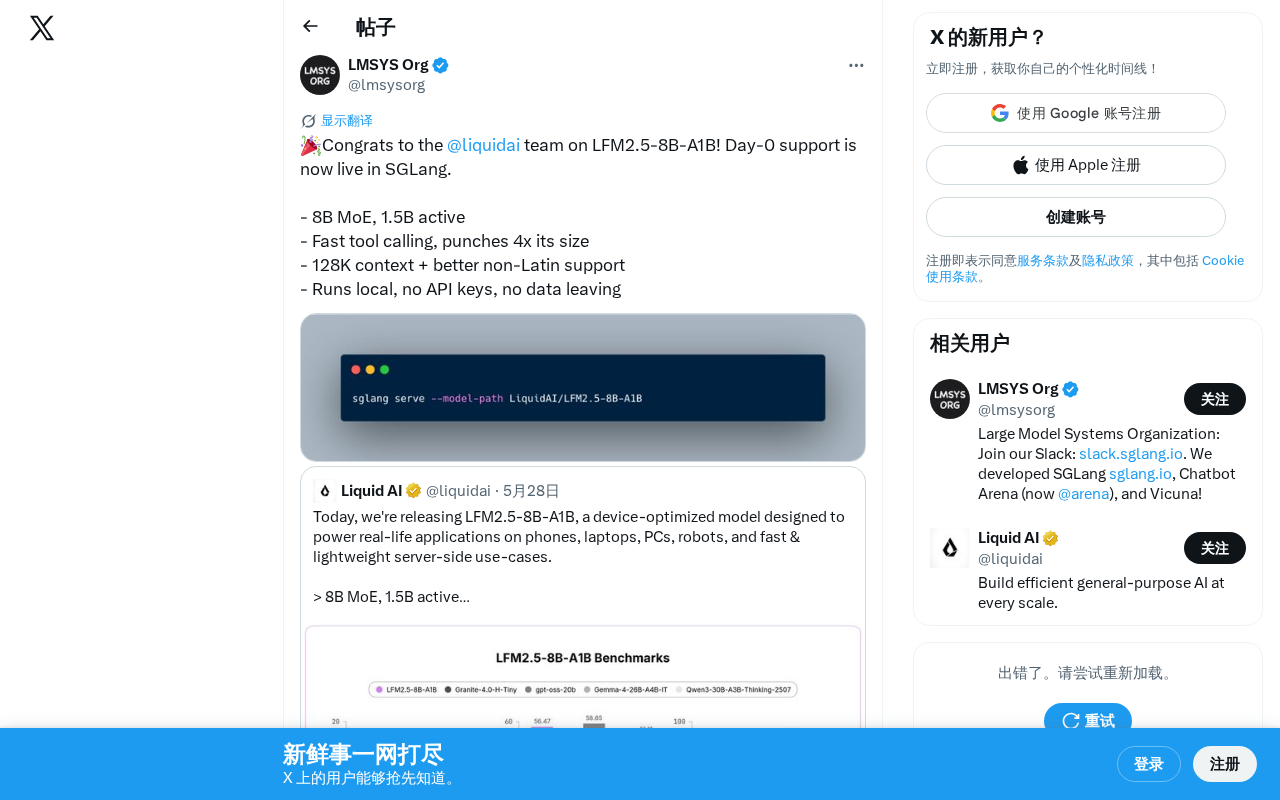
LFM2.5-8B-A1B:1.5B激活参数实现4倍体量效果的MoE模型
Liquid AI发布LFM2.5-8B-A1B模型,采用MoE架构,8B总参数仅激活1.5B,在工具调用场景中媲美6B级模型表现。支持128K上下文、本地部署、多语言,SGLang即时支持。
阅读全文 →
 产品体验
产品体验·8 分钟
13大AI模型编程能力实测:谁才是最强编程助手?
横向评测GPT-4.1、Claude 3.7 Sonnet、Gemini 2.5 Pro等13大AI模型的编程能力,通过同一道高难度算法题从代码正确性、解题思路、多语言转换等8个维度打分,揭晓最强AI编程助手排名。
阅读全文 →
 教程攻略
教程攻略·7 分钟
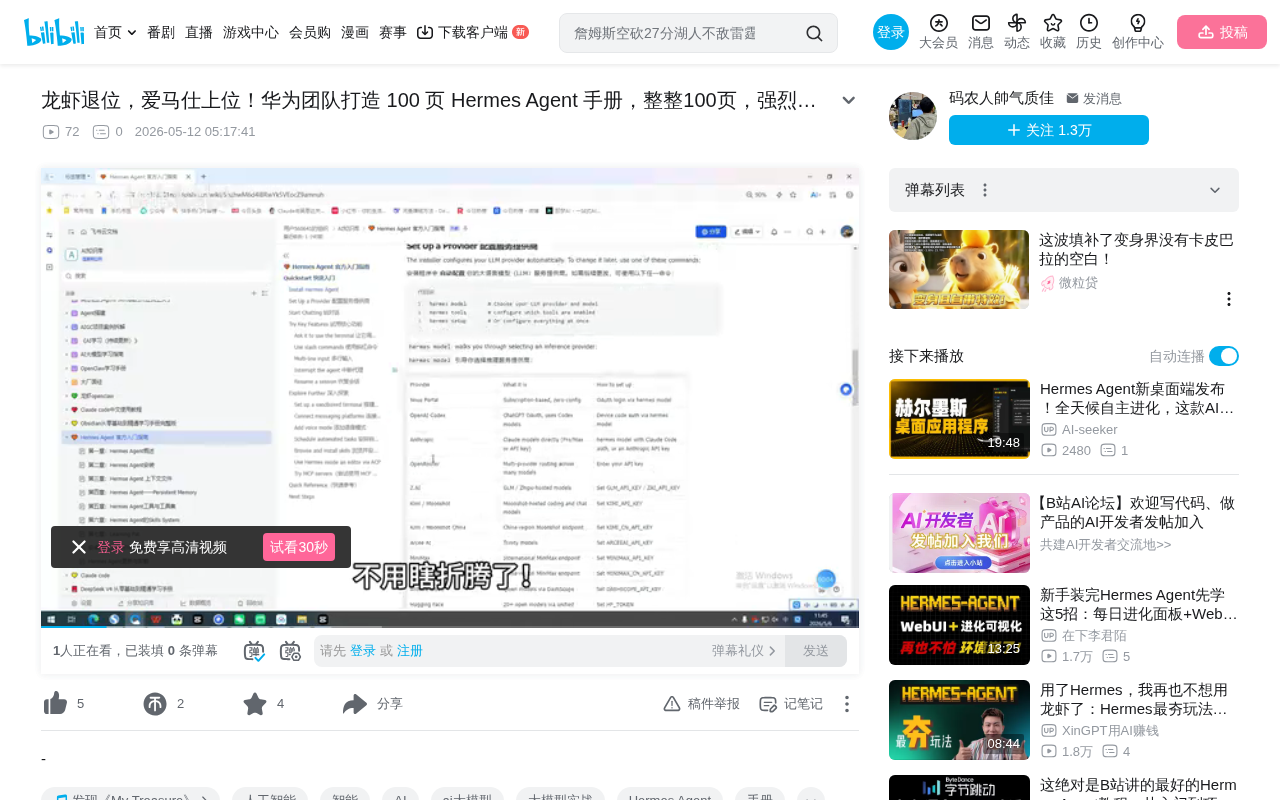
华为Hermes Agent手册解读:五层记忆架构与多智能体协同实战
深度解读华为Hermes Agent百页手册,详解五层记忆架构如何解决AI健忘症、自进化闭环机制让Agent持续优化、多智能体协同的工程化落地方案,为不同水平开发者提供系统化学习路径。
阅读全文 →
 产品体验
产品体验·7 分钟
4×3080Ti本地部署千问3.6 27B跑OpenCode编程实测
使用4张3080Ti 16G魔改显卡本地部署千问3.6 27B FP8模型,配合OpenCode完成系统管理工具开发的完整实测。涵盖硬件配置、推理速度、上下文管理经验及开发效率对比。
阅读全文 →
 教程攻略
教程攻略·6 分钟
P106矿卡跑AI大模型:几十块搭建本地AI工作站
用几十块钱的P106矿卡搭建本地AI工作站,运行Live Portrait等AI模型实现照片动态化。详解硬件成本、部署流程、隐私优势与性能局限,低成本体验AI创作的极致性价比方案。
阅读全文 →
 教程攻略
教程攻略·7 分钟
PyTorch高效入门:源码驱动的学习方法论
分享一套经过验证的PyTorch高效学习方法:用2-3天速览基础概念,再通过逐行阅读U-Net、ViT等开源项目源码快速进阶。告别低效刷文档和冗长教程,用源码驱动的方式真正掌握PyTorch核心能力。
阅读全文 →