#测试工具
共 44 篇相关文章
产品体验
Fabraix:1000+对抗策略,找出AI Agent隐藏缺陷
·6 分钟
Fabraix:1000+对抗策略,找出AI Agent隐藏缺陷
Fabraix是一款由前Meta工程师打造的AI Agent对抗性测试工具,通过1000+自适应攻击策略,以纯黑盒方式零集成发现Agent的幻觉、安全漏洞和逻辑错误,帮助开发者在用户之前定位问题。
阅读全文 →
 观点碰撞
观点碰撞·6 分钟
AI时代测试工程师如何避免被替代?三层核心认知决定职业天花板
AI能写用例、跑自动化,测试工程师会被替代吗?本文从能力边界、人机协作、核心竞争力三个层次,解析AI时代测试工程师的生存法则与转型方向,助你从执行者升级为质量核心。
阅读全文 →
 产品体验
产品体验·6 分钟
Dogra:开源自托管语音AI平台,告别VAPI天价账单
Dogra是一款开源自托管语音AI平台,提供可视化工作流构建器、多服务商自由切换和完整调用追踪能力。对比VAPI、Bland等托管平台,Dogra帮助开发者大幅降低语音Agent成本,摆脱供应商锁定,实现完全可控的语音AI部署。
阅读全文 →
 产品体验
产品体验·4 分钟
Runbook:AI Agent开发环境CLI检测工具,告别盲猜提升编程效率
Runbook是一款用Rust编写的CLI环境检测工具,通过扫描本地已安装的CLI工具并设定使用偏好,让Claude Code等AI Agent准确识别开发环境,避免npm/pnpm误判等常见问题,大幅减少Token浪费和试错成本。
阅读全文 →
 科技前沿
科技前沿·4 分钟
Anthropic捐赠AI对齐工具Petri给Meridian Labs:开源安全评估新格局
Anthropic将AI对齐测试工具Petri正式捐赠给Meridian Labs,并发布重大更新提升适应性、真实性和深度。本文解析这一事件对AI安全领域的深远影响及行业趋势。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Postman接口测试入门教程:请求发送与响应解读实战指南
Postman接口测试入门教程,详解请求方法、URL、鉴权、请求体等核心配置,以及状态码和响应体的解读技巧。从界面布局到实战调试,帮助零基础用户快速掌握API接口测试的完整流程。
阅读全文 →
 深度解读
深度解读·6 分钟
AITS智能测试平台:AI Agent如何让测试工程师从写脚本到驾驭AI
深入解析AITS智能测试平台如何借助AI Agent实现测试用例自动生成、脚本自我修复和探索式测试,帮助测试工程师从脚本编写者升级为AI测试策略决策者,全面提升软件测试效率与质量。
阅读全文 →
 教程攻略
教程攻略·8 分钟
用AI从零开发全栈网站:Cursor+DeepSeek实战教程
详细记录如何用Cursor和DeepSeek从零开发全栈网站的完整流程,涵盖MySQL数据库设计、Node.js后端开发、Vue前端界面搭建到宝塔面板部署上线,零基础也能跟着做。
阅读全文 →
 产品体验
产品体验·4 分钟
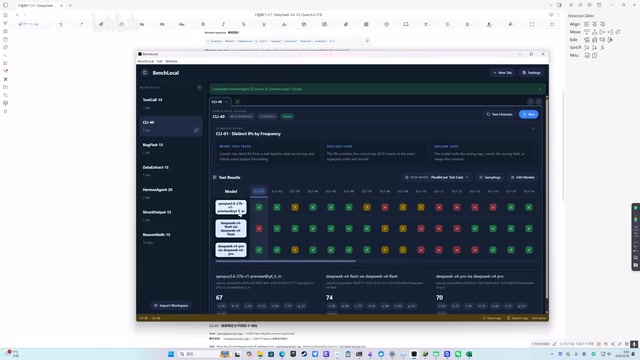
DeepSeek V4 vs Qwen3.6实测:8大类150场景深度对比评测
使用BenchLocal工具对DeepSeek V4 Pro、V4 Flash与Qwen3.6 27B进行8大类85场景实测对比,涵盖工具调用、代码调试、推理数学等维度,V4 Pro总分领先6%但数学推理意外翻车,Qwen3.6 Q6在智能体场景媲美V4 Pro。
阅读全文 →
 产品体验
产品体验·4 分钟
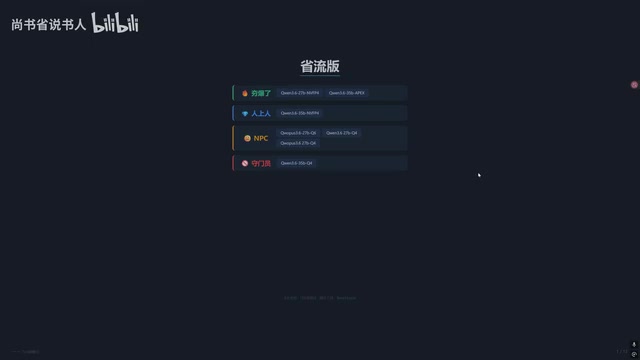
Qwen3.6量化版本地部署实测:NVFP4、APEX、Q4、Q6哪个最值得选
实测Qwen3.6系列7-8个量化模型在工具调用、命令行操作、Bug修复、数学推理等8大维度的表现,对比NVFP4、APEX、Q4、Q6量化方案,附总分排名与选购建议,帮你找到最适合本地部署的量化版本。
阅读全文 →
 产品体验
产品体验·5 分钟
GitHub Copilot CLI深度评测:免费用Claude Sonnet的终端编程代理
GitHub Copilot CLI公开预览版深度体验,默认搭载Claude Sonnet模型,预览期完全免费无限量。本文通过四项实测任务,对比Claude Code等竞品,详解其功能特性、使用体验与不足之处。
阅读全文 →
 教程攻略
教程攻略·7 分钟
VS Code Claude Code接入DeepSeek V4 Pro配置教程(5步完成)
详细图文教程:通过CCSwitch工具将VS Code中的Claude Code插件接入DeepSeek V4 Pro模型,绕过认证限制,以2.5折成本享受AI编程助手。含API Key获取、格式选择及常见问题解答。
阅读全文 →
 深度解读
深度解读·5 分钟
LLM每秒10个Token有多快?直观感受Token生成速度的开源工具
通过开源工具直观体验LLM不同Token生成速度(5-800 TPS)的实际效果,帮助开发者理性选择模型、优化推理性能,告别对TPS数字的盲目追求。
阅读全文 →
 产品体验
产品体验·5 分钟
20年老程序员用Claude Code重构祖传代码:从一周到一小时的实战记录
一位20年经验的车载软件开发者分享Claude Code两个月实战经历,包括车控接口测试工具开发从一周缩短到一小时、2500行祖传空调模块两周彻底重构等真实案例,揭示AI编程时代程序员经验价值的重新定义。
阅读全文 →
 教程攻略
教程攻略·10 分钟
Webman资源路由:一行代码生成8个RESTful接口
详解Webman框架资源路由用法,通过Route::resource一行代码自动注册8个RESTful标准路由,覆盖CRUD增删改查、软删除与恢复操作,附控制器定义、路由清单及Postman接口调试全流程。
阅读全文 →
 科技前沿
科技前沿·5 分钟
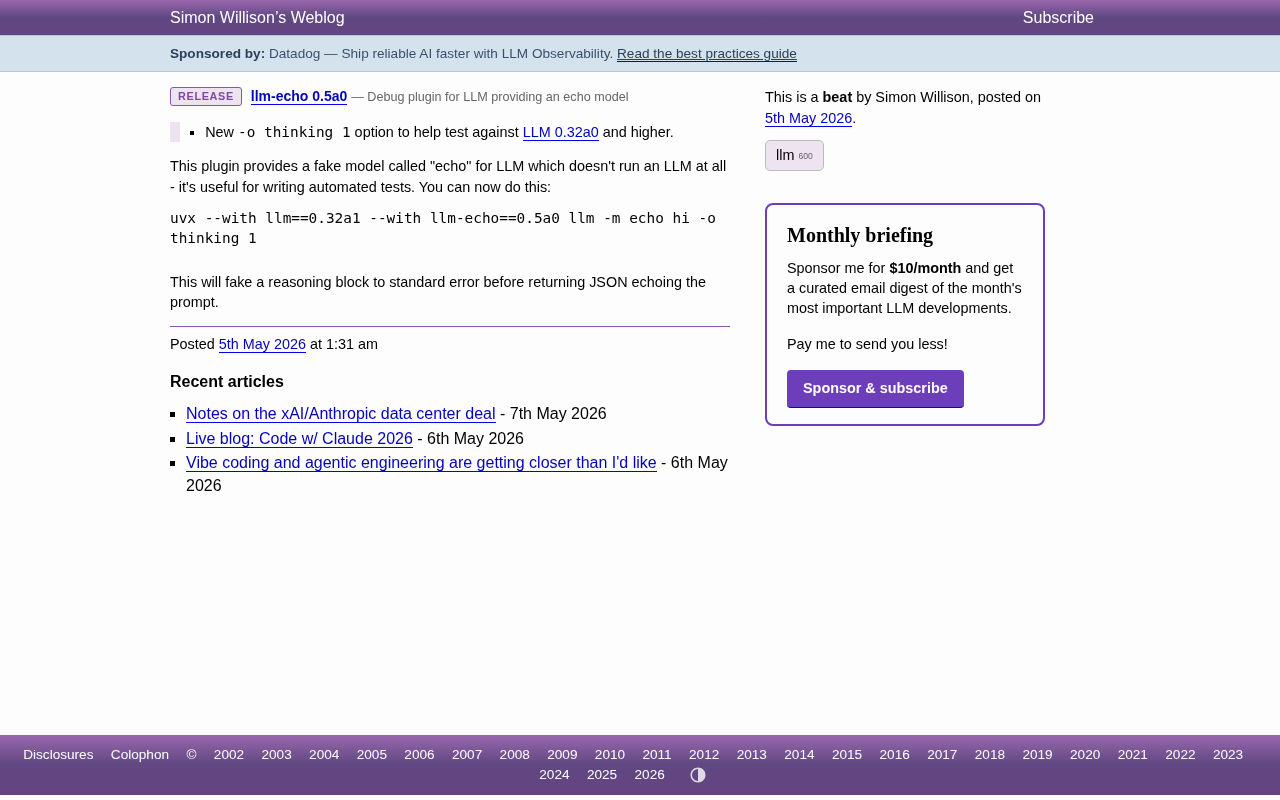
llm-echo 0.5a0:模拟思维链输出的LLM测试利器
Simon Willison发布llm-echo 0.5a0,新增thinking选项模拟大语言模型思维链输出。本文介绍该LLM测试插件的用法、设计理念及其在AI开发工作流自动化测试中的实际价值。
阅读全文 →
 教程攻略
教程攻略·8 分钟
8个AI测试Skill搭建指南:让AI变身专属QA助手
详解8个测试人必备的AI Skill搭建方法,涵盖需求转用例、接口脚本生成、Bug报告、日志分析等场景,帮助QA团队用工程化方式驾驭AI,实现测试效率翻倍提升。
阅读全文 →
 科技前沿
科技前沿·6 分钟
DeadEnd-CLI:开源AI渗透测试工具黑盒基准达81%通过率
DeadEnd-CLI是一款开源AI代理式渗透测试工具,在XBOW基准测试中以KIMI K2.5模型实现81%全黑盒通过率。支持多模型兼容、完全自托管部署,为安全团队提供低成本自动化渗透测试方案。
阅读全文 →
 科技前沿
科技前沿·6 分钟
Kimi K2官方验证工具K2-Vendor-Verifier:一键检测API供应商模型精度
Moonshot AI开源K2-Vendor-Verifier工具,专门验证第三方Kimi K2 API供应商的推理精度。本文详解该工具的核心功能、技术实现思路及对开发者选型的实际价值,帮助你避开过度量化、模型替换等API市场隐患。
阅读全文 →
 科技前沿
科技前沿·7 分钟
Datasette 1.0a29发布:用GPT-5.5修复棘手的段错误竞态条件
Datasette 1.0a29预览版发布,修复了一个由测试优化引入的段错误竞态条件Bug。开发者Simon Willison借助GPT-5.5 xhigh模型辅助复现问题,展示了AI调试的实战价值。本文深度解析修复过程及新增功能。
阅读全文 →