#评测体系
共 21 篇相关文章
Cursor设计模式发布与OpenAI Codex更新:AI编程工具最新动态
·7 分钟
Cursor设计模式发布与OpenAI Codex更新:AI编程工具最新动态
Cursor推出设计模式实现可视化开发,OpenAI Codex多项改进及安全锁定模式发布,Anthropic限额翻倍,AI智能体排行榜出炉,Google DeepMind模型压缩突破,全面解读AI领域最新进展。
阅读全文 →

·7 分钟
AI基准测试:当前最被低估的技术创业机会
AI基准测试正成为巨大的创业机会。传统评测被刷爆、供需严重失衡,谁能构建高质量公共AI基准测试,谁就掌握行业话语权。本文解析为何AI评测基础设施是高回报的差异化路径。
阅读全文 →

·5 分钟
ViBench:专为AI应用构建能力设计的评测基准
深入解析ViBench评测基准,了解它如何弥补SWE-bench在应用构建能力评估上的不足,从端到端生成、视觉交互、功能完整性等维度全面衡量AI编程工具的实际表现。
阅读全文 →
 行业洞察
行业洞察·6 分钟
AI产品开发实战:模型选择、护城河构建与商业化路径
分享AI产品开发的实战策略,包括为什么不应从头训练模型、如何选择API调用与微调时机、构建产品护城河的关键要素,以及从评测体系搭建到商业化落地的完整执行路径。
阅读全文 →
 教程攻略
教程攻略·9 分钟
OpenRouter免费模型使用教程:28款免费AI模型接入与市场格局深度解析
详解OpenRouter平台28款免费AI模型的筛选、API接入配置方法,涵盖GPT-OSS 120B、DeepSeek V4 Flash等热门模型,并通过排行榜数据分析AI模型市场格局、Coding Agent竞争态势及免费与付费模型的效率差距。
阅读全文 →
 教程攻略
教程攻略·7 分钟
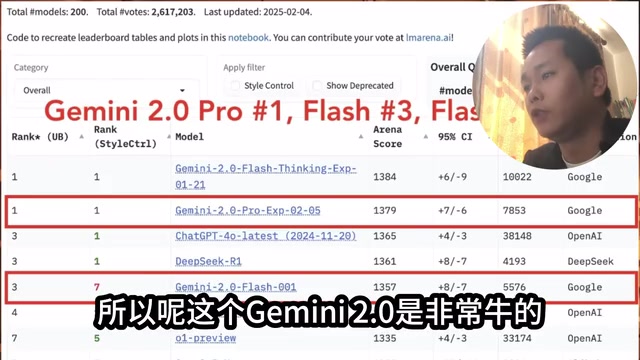
Bolt.diy+Gemini 2.0:免费零代码开发APP完整教程
详解如何用开源工具Bolt.diy搭配Gemini 2.0,通过OpenRouter免费调用顶级AI模型,零代码生成完整APP。涵盖环境配置、实战演示与优劣势分析,适合零编程基础用户快速上手。
阅读全文 →
 教程攻略
教程攻略·5 分钟
AI大模型应用开发进阶路径:从入门到40K月薪的四个阶段
系统梳理AI大模型应用开发的四阶段进阶路径,从RAG、Agent等基础知识体系搭建,到项目实战、性能优化、架构设计,帮助传统开发者规划AI转型路线,实现从入门到40K月薪的职业跃迁。
阅读全文 →
 产品体验
产品体验·7 分钟
Kimi K2.6开源实测:300个Agent协同的调度能力到底多强
深度解析月之暗面开源模型Kimi K2.6的Agent调度能力,300个子Agent协同执行4000步任务,编程实战超越GPT-5.4,2张4090即可LoRA微调,附部署方案与性能对比。
阅读全文 →
 产品体验
产品体验·8 分钟
Claude 4.5 vs Gemini 3 Pro:编程能力全面对决
基于ARC-AGI-V2、SWE-Bench、Terminal Bench 2.0等五大基准测试,深入对比Claude 4.5与Gemini 3 Pro在编程实战和知识推理上的真实表现,帮你找到最适合的AI编程助手。
阅读全文 →
 产品体验
产品体验·5 分钟
DeepSeek V4 Pro深度评测:对比8款旗舰模型谁更值得用
DeepSeek V4 Pro全方位横评,对比GPT 5.5、Claude Opus 4.7、GLM 5.1等8款旗舰模型,覆盖价格、编程、推理、Agent、角色扮演等维度,附场景化选购建议。
阅读全文 →
 产品体验
产品体验·3 分钟
Cursor Composer 2.5深度测评:成本仅Opus十分之一的编程模型
深度实测Cursor自研编程模型Composer 2.5,基于Kimi K2.5训练,每次任务仅7美分,速度是Opus 4.7的两倍。涵盖前端开发、SVG生成、3D场景等多场景评估,分析其性价比优势与设计短板。
阅读全文 →
 科技前沿
科技前沿·3 分钟
Qwen3.5-Omni发布:215项任务SOTA,阿里全模态大模型硬刚Gemini
阿里发布Qwen3.5-Omni全模态大模型,基于1亿小时音视频数据原生多模态预训练,215项任务拿下SOTA,多项指标超越Gemini 3.1 Pro。支持音视频Web Coding、长音频分析、113种语言语音识别等能力。
阅读全文 →
 科技前沿
科技前沿·4 分钟
武汉破获AI换脸盗号案:40万非法获利背后的深度伪造安全隐患
武汉警方破获一起利用AI换脸技术盗取公众号账号案件,犯罪嫌疑人通过深度伪造突破人脸识别验证非法获利40万元。本文详解作案手法、技术漏洞及防范建议。
阅读全文 →
 产品体验
产品体验·8 分钟
小米MiMo V2.5 Pro深度实测:代码、3D、SVG生成能力全面评测
深度实测小米MiMo V2.5 Pro开源大模型,1.2万亿参数MoE架构,覆盖macOS克隆、前端UI、Three.js 3D场景、SVG图形生成等实际任务,对比GPT-5.4、Claude Opus 4.6、DeepSeek V4,附详细测试结果与成本分析。
阅读全文 →
 教程攻略
教程攻略·10 分钟
智谱GLM-4.5免费使用教程:全栈开发+PPT生成+Claude Code实战
详解智谱GLM-4.5免费使用方法,涵盖网页版全栈开发、一句话生成PPT、API搭配Claude Code编程工作流等实战教程,附详细配置步骤与实测效果对比。
阅读全文 →
 教程攻略
教程攻略·9 分钟
Agent Skill维护避坑:Perplexity「超距作用」防御与评测实战指南
深入解析Perplexity提出的Agent Skill维护中的「超距作用」风险,涵盖三类失败的精准修法、Gotcha飞轮机制、四层评测体系搭建,帮助AI工程师避免修了A崩了C的连锁反应,构建稳定可靠的Skill系统。
阅读全文 →
 产品体验
产品体验·8 分钟
Claude 4.5 Haiku实测翻车:编码能力全面溃败,性价比被竞品碾压
独立测试者对Claude 4.5 Haiku进行全面实测,发现其在SVG生成、3D渲染、代理编码等任务中表现远低于预期。与GPT-5 Mini、GLM 4.6对比,性价比严重不足。深度分析Anthropic产品线困境与基准测试刷分隐忧。
阅读全文 →
 科技前沿
科技前沿·7 分钟
SWE-bench官方博客上线:AI编程评测标准进入新阶段
SWE-bench官方博客正式上线,将持续发布AI编程评测、AI Agent及工具链深度内容。本文详解SWE-bench基准测试的核心价值、博客上线的行业意义,以及AI代码生成评测的未来趋势。
阅读全文 →

