#AI评测
共 11 篇相关文章
AI编程为何进步最快?四大结构性优势深度解析
·5 分钟
AI编程为何进步最快?四大结构性优势深度解析
AI编程能力的进步速度远超文案写作和图像生成,背后有四大结构性原因:反馈即时明确、GitHub提供天然优质数据、评判标准统一可量化、完美适配强化学习。本文深度拆解代码任务的独特优势,解释为何编程成为AI发展最快的赛道。
阅读全文 →
Cursor设计模式发布与OpenAI Codex更新:AI编程工具最新动态
·7 分钟
Cursor设计模式发布与OpenAI Codex更新:AI编程工具最新动态
Cursor推出设计模式实现可视化开发,OpenAI Codex多项改进及安全锁定模式发布,Anthropic限额翻倍,AI智能体排行榜出炉,Google DeepMind模型压缩突破,全面解读AI领域最新进展。
阅读全文 →

·7 分钟
AI基准测试:当前最被低估的技术创业机会
AI基准测试正成为巨大的创业机会。传统评测被刷爆、供需严重失衡,谁能构建高质量公共AI基准测试,谁就掌握行业话语权。本文解析为何AI评测基础设施是高回报的差异化路径。
阅读全文 →
 产品体验
产品体验·8 分钟
AI编码助手深度评测:Copilot垫底,谁才是真正王者?
对主流AI编码助手进行系统性评测,涵盖Claude Code、GitHub Copilot、Cursor、RooCode等工具在三个模型下的表现对比,揭示综合排名与最佳使用场景选择建议。
阅读全文 →
 前沿研究
前沿研究·7 分钟
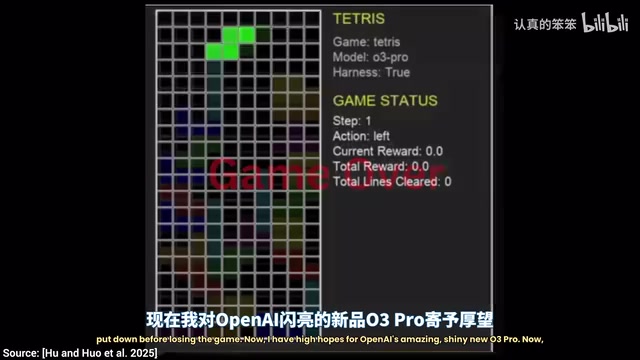
AI玩游戏实力大比拼:O3 Pro展现惊人规划能力
研究者用俄罗斯方块、超级马里奥、推箱子等经典游戏测试各大AI模型,O3 Pro展现出前所未有的规划能力,成为唯一通关全部关卡的模型。游戏测试揭示AI正从模式匹配向真正的战略思维演进。
阅读全文 →
 科技前沿
科技前沿·5 分钟
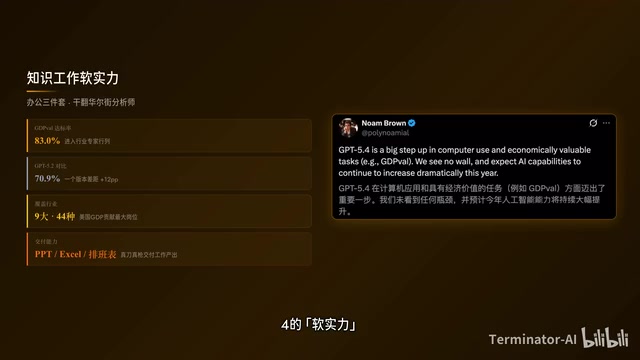
GPT-5.4深度评测:原生计算机使用、推理编程合体,OpenAI重回王座
GPT-5.4全面评测:OSWorld超越Claude Opus 4.6,原生计算机使用能力炸裂,推理编程合体Token效率提升50%,幻觉率暴降33%,搜索能力刷新纪录。OpenAI首个全能通用模型深度解析。
阅读全文 →
 产品体验
产品体验·9 分钟
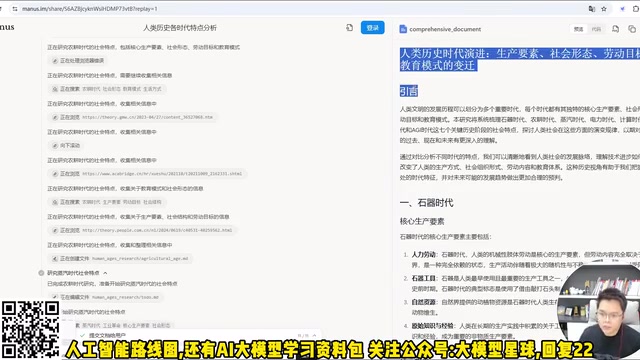
Manus实测:三大真实场景验证通用AI Agent到底行不行
深度实测Manus通用AI Agent在历史报告生成、特斯拉股票分析及GAIA基准测试中的真实表现。对比垂直智能体核心差异,附GAIA三级评分数据与局限性分析,看清AI从对话助手到任务执行者的进化之路。
阅读全文 →
 产品体验
产品体验·9 分钟
Kimi K2 Thinking实测:Claude Code中能否平替Sonnet 4.5?
在Claude Code中实测Kimi K2 Thinking模型,从文本创作、编程开发、智能体构建到全栈应用多维度评测,对比Claude Sonnet 4.5和DeepSeek,分析其作为高性价比AI编程替代方案的真实表现。
阅读全文 →
 产品体验
产品体验·8 分钟
Claude 4.5 Haiku实测翻车:编码能力全面溃败,性价比被竞品碾压
独立测试者对Claude 4.5 Haiku进行全面实测,发现其在SVG生成、3D渲染、代理编码等任务中表现远低于预期。与GPT-5 Mini、GLM 4.6对比,性价比严重不足。深度分析Anthropic产品线困境与基准测试刷分隐忧。
阅读全文 →
 教程攻略
教程攻略·7 分钟
AI项目评测体系:5大层级30项指标实战指南
基于实战经验总结的AI项目评测框架,涵盖模型质量、用户体验、系统效率、业务价值、数据闭环5大层级30项核心指标,帮助产品团队科学评估大模型Agent项目表现,驱动持续优化。
阅读全文 →
 深度解读
深度解读·9 分钟
GPT-5.5「哥布林」事件深度解析:从搞笑Bug到AI对齐的终极命题
OpenAI GPT-5.5模型集体输出「哥布林」词汇,官方技术博客揭示强化学习奖励信号泛化的根本原因。
阅读全文 →