#KV缓存
共 18 篇相关文章

·5 分钟
日本软件产业为何落后?AI时代的结构性困局与破局路径
深度分析日本软件产业长期落后的结构性原因,探讨终身雇佣制、多层外包体系等因素如何在AI时代放大竞争劣势,以及日本科技产业的破局方向。
阅读全文 →

·11 分钟
程序员合理摸鱼:从代码编译到AI生成的等待艺术
从经典XKCD编译等待梗到AI编程时代的新解读,探讨程序员等待编译、等待AI生成代码背后的工作方式变革,以及如何重新定义开发者生产力。
阅读全文 →
 科技前沿
科技前沿·5 分钟
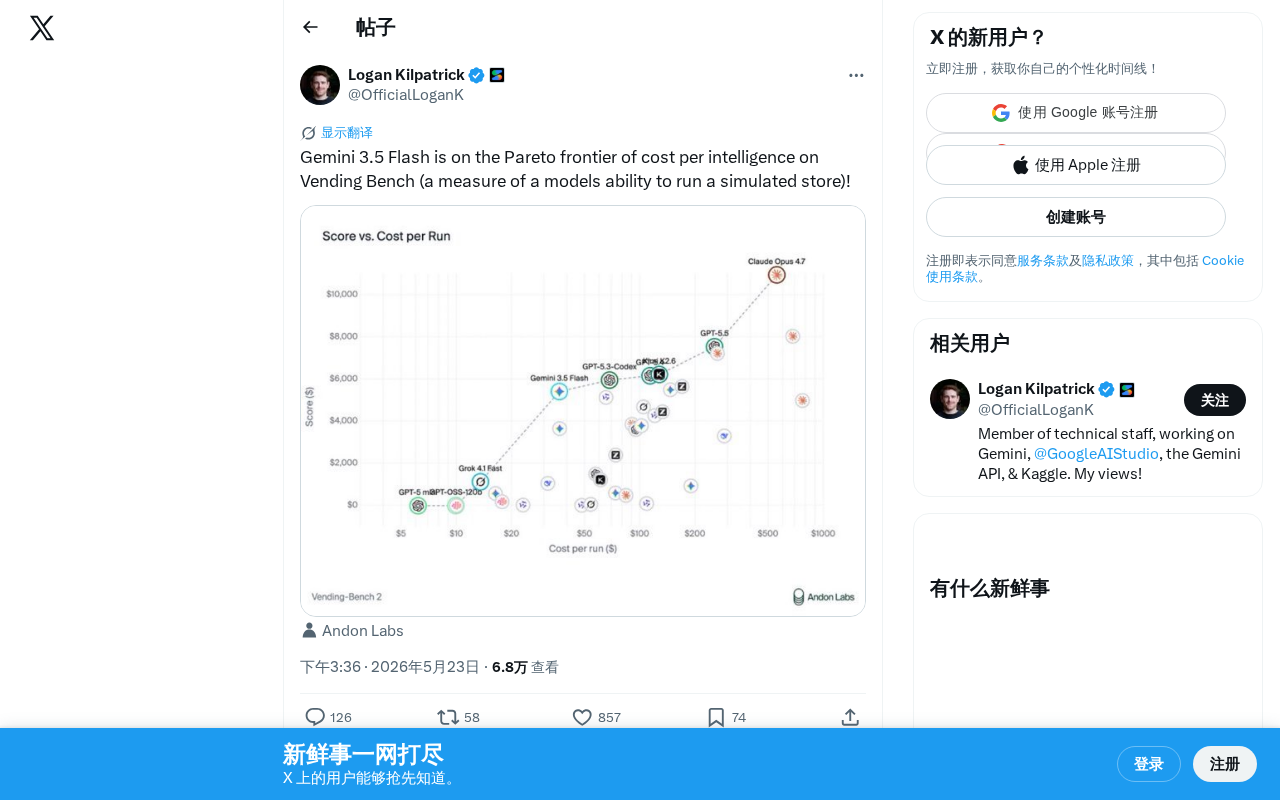
Gemini 3.5 Flash登顶Vending Bench性价比前沿
Google Gemini 3.5 Flash在Vending Bench基准测试中达到成本-智能帕累托最优,展现极强性价比。本文解析Vending Bench评测方法、帕累托前沿含义及对AI应用开发者的实际意义。
阅读全文 →
 行业洞察
行业洞察·10 分钟
Google I/O 2026深度解读:从超级App到生态内核之争
深度解析Google I/O 2026发布会战略信号:Gemini 3.5 Flash、Omni视频工具、Spark个人Agent等核心产品拆解,以及谷歌与OpenAI、Anthropic三巨头的AI生态竞争格局。
阅读全文 →
 产品体验
产品体验·5 分钟
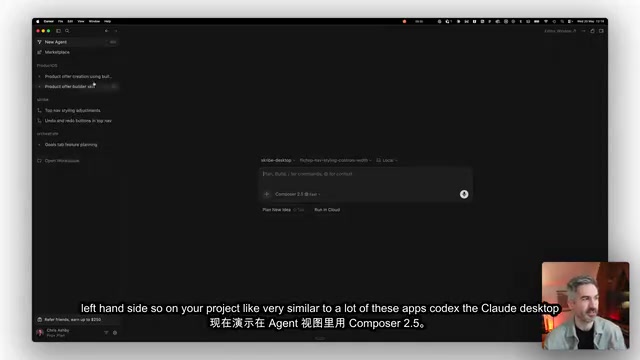
Cursor Composer 2.5实测:速度更快成本省10倍的AI编码模型
实测Cursor Composer 2.5的Agent视图、Plan模式和右侧面板功能,编码能力追平Claude和GPT顶级模型,成本最高降低10倍,速度显著提升,详解实操体验与使用建议。
阅读全文 →
 教程攻略
教程攻略·5 分钟
AI大模型应用开发进阶路径:从入门到40K月薪的四个阶段
系统梳理AI大模型应用开发的四阶段进阶路径,从RAG、Agent等基础知识体系搭建,到项目实战、性能优化、架构设计,帮助传统开发者规划AI转型路线,实现从入门到40K月薪的职业跃迁。
阅读全文 →
 产品体验
产品体验·5 分钟
DeepSeek V4 Pro深度评测:对比8款旗舰模型谁更值得用
DeepSeek V4 Pro全方位横评,对比GPT 5.5、Claude Opus 4.7、GLM 5.1等8款旗舰模型,覆盖价格、编程、推理、Agent、角色扮演等维度,附场景化选购建议。
阅读全文 →
 教程攻略
教程攻略·6 分钟
日均5亿Token:DeepSeek驱动UE5项目AI编程实战经验
一位UE5开发者分享日均消耗5亿Token的AI编程实战:DeepSeek V4 Pro多智能体架构设计、缓存命中率95%+的成本控制策略、文档先行的开发工作流,日均成本仅20-60元。
阅读全文 →
 产品体验
产品体验·4 分钟
Qwen3.6本地部署实战:35B模型逆向LTE调制解调器击败Claude
Qwen 3.6 35B MoE模型在MacBook本地运行,成功逆向工程LTE调制解调器Web门户,从混淆JS代码中提取登录逻辑和信号数据,代码质量超越Claude Sonnet,Gemma 4同一任务失败。详解三级测试体系与近4小时推理全过程。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Anima二次元大模型:6G显存本地部署与工作流配置教程
详解Anima二次元动漫AI绘图大模型的本地部署方法,仅需6G显存即可流畅运行。涵盖ComfyUI工作流配置、文生图参数设置、高清放大技巧及低显存优化建议,适合中低端显卡用户。
阅读全文 →
 教程攻略
教程攻略·8 分钟
语法约束解码:让小模型生成可靠Bash代码的实战指南
深入解析语法约束解码(Grammar-Constrained Decoding)技术,探讨如何在推理阶段为小型语言模型施加Bash语法约束,大幅提升代码生成的正确率与可执行性,助力AI Agent边缘部署与自动化运维场景。
阅读全文 →
 教程攻略
教程攻略·9 分钟
OpenAI开源GPT-OSS:16G显存跑O4级模型,部署教程全解析
OpenAI正式开源GPT-OSS系列模型(20B/120B),采用MOE架构+FP4混合精度,单卡4090即可运行O3级推理模型。本文详解核心技术、性能评测及Ollama/vLLM等四种本地部署方案。
阅读全文 →
 教程攻略
教程攻略·10 分钟
Codex+Ollama本地部署教程:零成本搭建AI编程助手
手把手教你用Codex搭配Ollama在本地部署免费AI编程助手,涵盖硬件检测、Ollama安装、Gemma/Qwen模型下载与接入配置全流程,轻松实现隐私安全的本地AI编程工作流。
阅读全文 →
 产品体验
产品体验·9 分钟
Claude Haiku 4.5实测:速度虽快,性价比不敌GPT-5 Mini
实测对比Claude Haiku 4.5与GPT-5 Mini、GLM 4.6的速度、代码质量和价格。Haiku 4.5速度领先Sonnet 4一分钟,但输入价格是GPT-5 Mini的4倍,第三方评测编码得分落后9个点,性价比优势不明显。
阅读全文 →
 深度解读
深度解读·9 分钟
SRP单一职责原则如何革新Prompt工程?模块化AI叙事架构解析
深入解析Singulari-Tea Codex开源项目,探讨如何将软件工程的单一职责原则(SRP)应用于Prompt架构设计,构建面向Gemini 2.5 Pro的模块化叙事模拟系统,以及这种范式转变对AI应用开发的深远启示。
阅读全文 →
 观点碰撞
观点碰撞·7 分钟
Sam Altman对话Garry Tan:OpenAI与YC如何共塑AI创业生态
Sam Altman与Y Combinator总裁Garry Tan展开深度对话,探讨OpenAI基础模型与YC创业生态的融合趋势。本文解读这场对话背后的行业信号,分析AI创业下一阶段的发展方向与硅谷权力网络的运作逻辑。
阅读全文 →
 深度解读
深度解读·7 分钟
Augment Code架构揭秘:专用子代理替代KV缓存,成本降90%
深度解析Augment Code如何用Mercury 2专用子代理替代传统KV缓存架构,实现上下文压缩速度提升82%、摘要成本降低90%、整体LLM支出降低30%的多模型协作方案。
阅读全文 →
 科技前沿
科技前沿·6 分钟
DeepSeek V3.2发布:自研稀疏注意力DSA+API降价50%全解析
DeepSeek发布V3.2-Exp实验版模型,首次引入自研DeepSeek Sparse Attention(DSA)稀疏注意力技术,大幅提升长上下文训练与推理效率,同时API价格下调超50%。本文详解DSA技术原理、模型架构演进及商业策略。
阅读全文 →