The Complete Guide to Agentic RAG: Principles and Code Implementation
Agentic RAG upgrades traditional RAG's fixed retrieval pipeline with tool-based intelligent decision-making.
Traditional RAG follows a rigid "retrieve once, generate once" pipeline that breaks down with complex queries and retrieval failures. Agentic RAG wraps retrieval components into callable tools and gives the LLM autonomous planning, tool calling, and multi-step iteration capabilities. Through the ReAct loop, it dynamically adjusts retrieval strategies, trading time for higher-quality answers — a fundamental upgrade from passive execution to active decision-making.
Why Traditional RAG Is No Longer Enough
If you've ever built a RAG system, you've almost certainly encountered these pain points: the model gives irrelevant answers, retrieval returns a pile of seemingly related but utterly useless content, the system freezes when asked what documents are in the knowledge base, and when retrieval fails to find an answer, it simply gives up instead of retrying with a different approach.
RAG (Retrieval-Augmented Generation) was formally introduced by Meta AI in a 2020 paper. Its core idea is to combine external knowledge bases with large language models to address the problems of model knowledge cutoff dates and hallucination. Traditional RAG has been widely adopted in enterprise knowledge Q&A, intelligent customer service, document assistants, and similar scenarios. However, its rigid "retrieve once, generate once" pipeline shows clear fragility when dealing with complex queries, multi-hop reasoning, and ambiguous expressions.
The root cause of these problems is that traditional RAG is a fixed pipeline — retrieve once, generate once, done. It lacks flexibility and cannot handle retrieval failures or incomplete information. The emergence of Agentic RAG represents a fundamental upgrade to this paradigm.
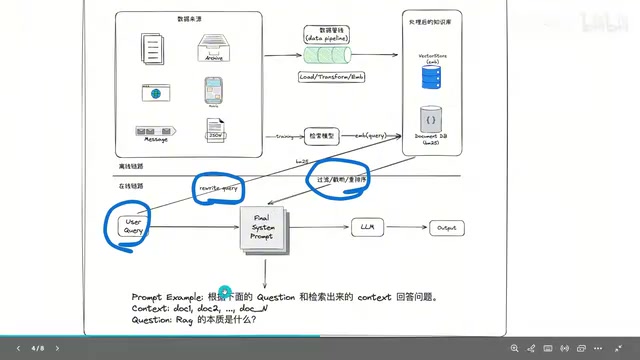
How Traditional RAG Works
Traditional RAG can be divided into two core processes: the offline pipeline and the online pipeline.
Offline Pipeline: Document Chunking → Vectorization → Storage
The offline pipeline is independent of users and serves as the data preparation stage:
- Document Loading: Load documents such as PDFs, Word files, and TXT files into memory.
- Text Chunking: Since documents can contain tens of thousands of words and cannot be fed to the LLM all at once (limited by the context window length), they need to be split into fixed-length segments (e.g., 256 characters) with some overlap between segments. Text chunking is a critical step in RAG systems that directly impacts retrieval quality. Common strategies include fixed-length splitting, semantic paragraph splitting, and recursive character splitting. The
chunk_overlapsetting prevents key information from being cut off at the boundary between two segments and is typically set to 10%-20% of thechunk_size. - Vectorization: Use an embedding model to convert each segment into a fixed-dimensional vector. Embedding models (such as OpenAI's text-embedding-ada-002, BAAI's BGE series, M3E, etc.) map text into a high-dimensional vector space (typically 768 or 1536 dimensions), so that semantically similar texts have smaller cosine distances in the vector space. This enables retrieval based on semantic similarity rather than simple keyword matching.
- Storage: Store the vectors in a vector database (such as ChromaDB, Milvus, Pinecone, Weaviate, etc.), which are specifically optimized for approximate nearest neighbor (ANN) search on high-dimensional vectors.
Online Pipeline: Retrieve → Assemble → Generate
When a user asks a question, the system executes the following steps:
- Query Rewriting: The user's original question may not be suitable for direct retrieval (e.g., colloquial phrasing, ambiguous pronoun references, etc.) and needs to be rewritten and optimized for vector retrieval.
- Dual-Path Retrieval: Use both BM25 keyword retrieval and vector similarity retrieval to obtain two sets of candidate segments. BM25 is a classic information retrieval algorithm based on term frequency statistics (an improved version of TF-IDF) and belongs to the sparse retrieval category — it excels at exact matching of keywords and proper nouns. Vector retrieval belongs to the dense retrieval category and excels at capturing semantic similarity and synonym paraphrasing. The two complement each other: BM25 handles "exact matching" while vector retrieval handles "semantic understanding."
- Merging and Reranking: After merging the results from both paths, a reranker model (such as Cohere Rerank, BGE-Reranker, bce-reranker, etc.) performs fine-grained ranking to select the most relevant Top-K segments. Unlike initial retrieval, a reranker considers the interaction information between the query and the document simultaneously, achieving higher ranking accuracy at a greater computational cost.
- Prompt Assembly: Inject the retrieved segments as context into the prompt template.
- LLM Generation: The model generates the final answer based on the context and the user's question.
The entire process is unidirectional, fixed, and one-shot. If the first round of retrieval fails to find useful information, the system cannot automatically retry or try a different retrieval approach.
What Is Agentic RAG?
Agentic RAG is a fundamental upgrade to traditional RAG. Its core idea is: wrap every component of RAG (query rewriting, vector retrieval, keyword search, file reading, etc.) into callable tools, and give the LLM the ability to make autonomous decisions.
The word "Agentic" comes from the concept of AI Agents — AI systems capable of autonomously perceiving their environment, making decisions, and taking actions. Bringing the autonomous decision-making capability of agents into RAG creates Agentic RAG: the model is no longer passively receiving retrieval results but actively planning retrieval strategies, evaluating result quality, and deciding whether further retrieval is needed.
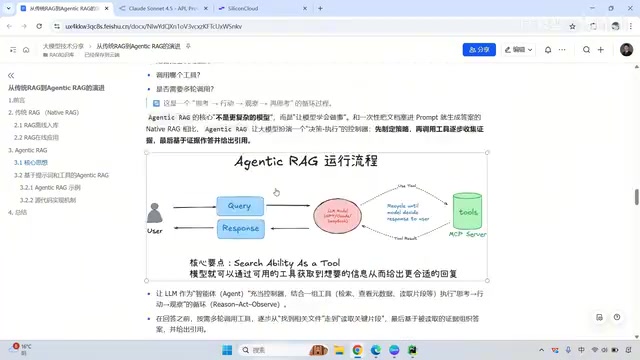
Key Differences Between Agentic RAG and Traditional RAG
| Dimension | Traditional RAG | Agentic RAG |
|---|---|---|
| Pipeline | Fixed, unidirectional | Iterative loop |
| Retrieval Count | Once | Multiple, dynamically adjusted |
| Decision Maker | Predefined rules | LLM's autonomous judgment |
| Failure Handling | Returns "I don't know" | Rewrites query and retries |
| Complex Questions | Struggles with multi-hop reasoning | Can decompose into multi-step subtasks |
| Tool Usage | Fixed pipeline | Dynamic, on-demand selection |
Three Core Capabilities of Agentic RAG
Agentic RAG relies on the model having the following capabilities:
-
Planning: Through Chain-of-Thought (CoT) reasoning, the model plans the steps to solve a problem. CoT is a prompting technique proposed by the Google Brain team in 2022 that significantly improves model performance on complex reasoning tasks by guiding the model to reason step by step rather than giving a direct answer. In Agentic RAG, CoT enables the model to analyze the complexity of the user's question, judge whether current information is sufficient, and plan which tool to call next. This planning capability is the key to an agent transitioning from "passive execution" to "active decision-making."
-
Tool Use: The ability to identify and call appropriate tools to obtain information. Modern LLMs (such as GPT-4, Claude, Qwen, etc.) can output structured tool call requests (including tool names and parameters) during generation through the Function Calling mechanism. An external system executes the call and returns the result to the model for continued reasoning.
-
Multi-Step Iteration (ReAct Loop): Before giving a final answer, the model can perform multiple rounds of tool calls, forming a closed loop of Think → Act → Observe → Think again. ReAct (Reasoning + Acting) is an agent reasoning framework proposed by Yao et al. in 2022. Its core idea is to have the model alternate between reasoning (Thought) and acting (Action), adjusting its next strategy based on environmental feedback (Observation). This loop enables the agent to handle complex tasks requiring multi-step reasoning, rather than attempting a one-shot answer that may be incorrect.
Deconstructing the Agentic RAG Implementation in ChatPDF/ChatBoss
Taking the open-source product ChatBoss as an example, its Agentic RAG implementation logic is highly instructive.
Decision Routing Mechanism
When a user question enters the system, it first determines whether the model supports Function Calling:
- Does not support Function Calling: A prompt is used to determine whether the question requires retrieval. If not, it responds directly; if so, it performs semantic search before generating an answer. This approach is suitable for older models or open-source models that don't support Function Calling.
- Supports Function Calling: All tools are registered with the model, and the model autonomously decides which tools to call.
This approach is superior to instructing the model via prompt to ignore irrelevant context, because it uses two models for decision-making (one to judge whether retrieval is needed, another to generate the answer), which theoretically yields better results. This also reflects the "Router" design pattern — performing intent classification at the system entry point and routing different types of requests to different processing pipelines.
Four Core Tools Explained
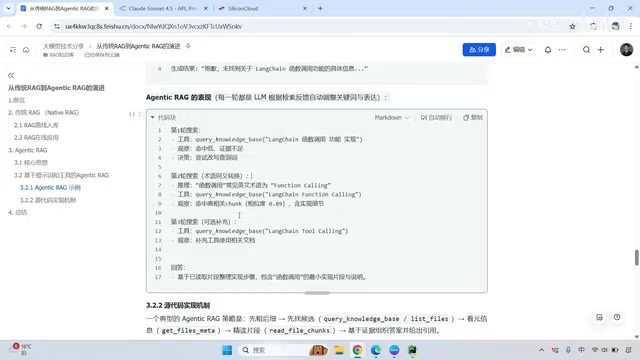
- Search Query: A basic semantic retrieval tool that performs vector similarity matching. The model can autonomously decide the search terms rather than simply using the user's original question, which itself achieves implicit query rewriting.
- List Files: Lists the files in the knowledge base, solving questions like "What documents do you have?" that traditional RAG cannot answer. Traditional RAG can only retrieve document content and is completely helpless when it comes to metadata about the knowledge base itself (what files exist, file structure, etc.).
- Read File: Reads specific segments precisely by document ID. When information is incomplete, it can proactively read adjacent segments to supplement context. This solves the information fragmentation problem caused by chunking — when an answer spans multiple chunks, the model can proactively fetch more context.
- Gather File Meta: Retrieves file metadata (such as filename, creation time, page count, author, etc.), helping the model make more precise retrieval decisions in multi-document scenarios.
Practical Comparison: Traditional RAG vs. Agentic RAG
Traditional RAG: User query → Vector retrieval → Retrieval results → Generate answer (one shot)
Agentic RAG:
- First search: Retrieves using the original query, finds that the hit rate is very low (similarity scores below threshold)
- Observe and rewrite: The model judges that retrieval quality is poor, analyzes that the cause may be improper query phrasing, and decides to rewrite the query
- Second search: Retrieves again with the rewritten query, hitting relevant segments
- Third round supplement: Discovers that the retrieved segments contain incomplete information, calls Read File to get more context from the relevant document
- Final generation: Generates a complete answer based on the consolidated information
This process may involve 3-5 tool calls. While latency increases, answer quality improves significantly. This is the core philosophy of "trading time for intelligence."
Agentic RAG Code Implementation in Detail
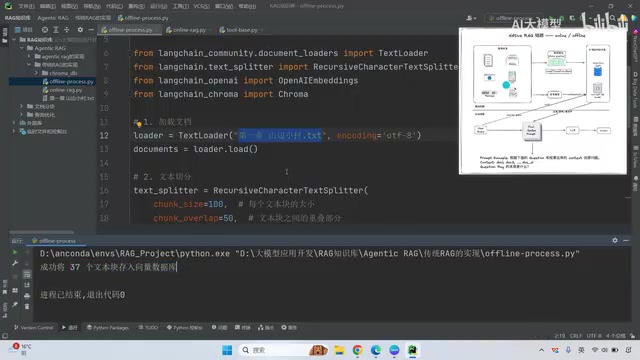
Traditional RAG Implementation (Based on LangChain)
Core steps of the offline pipeline:
# 1. Load documents
loader = TextLoader("your_file.txt")
# 2. Text splitting
splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=50)
# 3. Vectorize + Store in ChromaDB
Chroma.from_documents(documents=splits, embedding=embedding_model, persist_directory="./db")
RecursiveCharacterTextSplitter is a recursive character splitter provided by LangChain. It prioritizes splitting at natural boundaries such as paragraphs and sentences, and only falls back to character-level splitting when the chunk_size constraint cannot be met. This preserves semantic integrity better than simple fixed-length splitting.
Online pipeline: Load vector database → Similarity retrieval (Top-K) → Assemble prompt → LLM generation.
In practice, when the retrieved segments don't contain the answer, the model can only respond with "I don't know" — this is precisely the limitation of traditional RAG.
Agentic RAG Implementation (Based on LangGraph)
LangGraph is a framework developed by the LangChain team for building stateful, multi-step AI Agents. Unlike LangChain's linear chains, LangGraph is based on the concept of directed acyclic graphs (DAGs), allowing you to define nodes (processing logic) and edges (transition conditions), with support for loops, conditional branching, and state persistence. This makes it naturally suited for implementing ReAct-style agent patterns that require iterative loops.
The core uses LangGraph's create_react_agent:
# Define tool set
tools = [search_query, list_files, read_file, reason_file]
# Create React Agent
agent = create_react_agent(
llm=model, # LLM
tools=tools, # Tool list
system_prompt=prompt # System prompt
)
# Run
result = agent.invoke({"input": user_query})
create_react_agent internally implements the complete ReAct loop: the model generates a tool call request → LangGraph executes the corresponding tool → the tool's return value is appended to the conversation history → the model decides whether to continue calling tools or generate the final answer based on the new information. This loop continues until the model determines it has sufficient information and outputs a final response, or the preset maximum iteration count is reached.
The code looks concise, but it gives the model the ability to make autonomous decisions and dynamically adjust. The model continuously thinks → calls tools → observes results within the ReAct loop until it has gathered enough information to generate the final answer.
Summary and Reflections
Traditional RAG follows a linear "retrieve and answer" process — simple and direct but lacking adaptability. Agentic RAG turns retrieval capabilities into tools and makes the LLM the decision-making hub, capable of planning, calling, reflecting, and iterating.
Key takeaways:
- Tools provide capability; intelligence lies in the choices — True Agentic RAG starts with retrieval but succeeds through decision-making. Tools themselves are static; the model's decision-making ability is the source of system intelligence.
- The core logic isn't complicated. Many "wrapper" applications are essentially this same implementation under the hood. Once you understand the ReAct + Tool Use paradigm, you've grasped the technical core of most current AI applications.
- The heavy lifting is still in the offline pipeline: how to chunk documents, choose embedding models, and design retrieval strategies — these determine the quality of the context. Even with Agentic capabilities, if the underlying retrieval quality is poor, the model can't make something from nothing.
- Agentic RAG trades time for intelligence, achieving more accurate answers through multi-round iteration. But this also means higher latency and token consumption. In production environments, you need to balance response speed against answer quality.
- Future trends: Agentic RAG is evolving toward multi-agent collaboration, adaptive retrieval strategies, and knowledge graph integration. The boundary between it and traditional RAG will continue to blur.
For LLM engineers, mastering Agentic RAG has shifted from a "nice-to-have" to a "must-have" skill. It's not just a technical upgrade — it's a shift in mindset, from fixed pipelines to intelligent decision-making.
Related articles
 Deep Dives
Deep DivesDeep Dive into How OpenClaw (Open-Source Crayfish) AI Agent Works
Deep analysis of OpenClaw AI Agent internals: System Prompt, tool calling, SubAgents, Skill system, memory, and Context Engineering explained.
 Deep Dives
Deep DivesDemystifying Transformer: A Word-Continuation Function, Deconstructed
Understand Transformer through the lens of word continuation. Breaking down language generation into Embedding, Transformer Block, and Probability output modules for intuitive understanding.
 Deep Dives
Deep DivesFive Core Differences Between Claude Code and Regular AI Chat
A detailed comparison of Claude Code vs regular AI chat across five dimensions: interaction, context understanding, execution, memory, and tool integration.