Feedback Loops in Coding Agents: How Failure Becomes Fuel for Fixes

How coding Agents turn errors into fuel through feedback loops — and the four hard problems that make or break them.
This article explores how feedback loops transform coding Agents from one-shot code generators into iterative problem solvers. It breaks down the observe-act-observe cycle, explains the ReAct paradigm, and examines four critical challenges: context explosion, distinguishing symptoms from root causes, escaping oscillation death loops, and knowing when to stop. Practical advice on improving project observability and setting safety boundaries rounds out the discussion.
The Most Underrated Core Capability of Agents
If you were evaluating an AI coding tool, what would your criteria be? Most people look at whether it can get the code right on the first try. But that's actually the wrong question.
What truly separates the good from the great isn't the probability of getting it right the first time — it's whether the tool can see its own mistakes, locate them, and fix them on its own. This single capability determines whether what you're holding is a code generator or a true coding Agent.


Breaking the Misconception: Failure Isn't an Accident — It's Nutrition
The One-Shot Kill Illusion
We tend to think a good AI should get it right on the first try. But think about real development — even senior engineers write, rewrite, run, and re-run before getting things working. A rigid code generator chases the one-shot kill. For it, failure is a product incident: it spits out broken code, you take one look, and walk away. There's no second chance.
But real development has never been a one-shot game.
Errors Are Here to Guide You
What does a real development environment look like? Errors everywhere: failing tests, type-check warnings, lint errors, compilation failures, runtime exceptions, mismatched API fields, white-screen crashes, dependency version conflicts… These happen every single day.
For human engineers, this is just Tuesday. The key insight is: every failure message is actually telling you — there's a gap between your assumption in the last step and the actual state of the environment, and here's exactly where that gap is.
In other words, errors aren't here to yell at you — they're here to point the way. The only question is whether your Agent can understand what they're saying.
The Fundamental Difference in Perspective
Given the same error message:
- A code generator sees it as garbage — the one-time delivery failed, it's a product bug, throw it away
- A coding Agent sees it as nutrition — the task isn't done yet, failure is just an intermediate state, a valuable signal for deciding where to go next
This difference in perspective is where everything begins.
The Structure of Feedback Loops: Observe → Act → Observe Again
The core structure of a feedback loop can be summarized in three words: Observe → Act → Observe Again.
Expanded, it's five steps: Perceive → Decide → Act → Get Feedback → Perceive Again, forming a continuous loop. This corresponds to the ReAct pattern in general Agent theory (also called Observe-Reflect). The name doesn't matter — the core is always the same: after every step, pull the feedback from that step back in as input for the next step.
ReAct (Reasoning + Acting) is an Agent reasoning paradigm proposed jointly by Princeton University and Google Brain in 2022. Its core breakthrough is enabling large language models to alternate between "thinking" and "acting": first reasoning about the current state and planning the next step in natural language (Thought), then executing a concrete action (Action), then observing the result (Observation), forming a complete closed loop. Before this, the mainstream Chain-of-Thought approach focused only on the reasoning chain itself, lacking the ability to interact with the external environment, which made it prone to "hallucination"-style reasoning drift. By introducing external feedback, ReAct allows models to stop producing one-shot final answers and instead think while doing and adjust while thinking — just like humans — effectively mitigating the drift problem of pure reasoning.
It's not about charging forward blindly — it's about taking one step, looking around, and then deciding the next step. That "looking around" is the soul of the entire feedback loop.
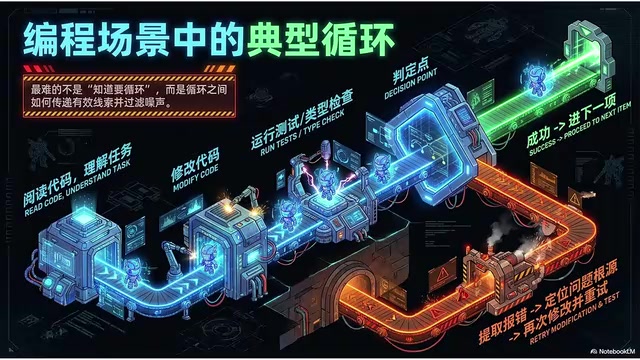
The Concrete Flow in a Coding Scenario
- Read relevant code, understand the task
- Make a code change
- Run tests or type checks
- Decision point: examine the output — if it passes, move on; if it fails, read the error
- Trace the error back to the code, locate the problem
- Make another change
- Run again
This loop continues until everything passes or a limit is reached and the Agent deliberately gives up. Failure isn't the end — it's a return track that sends the Agent back for another round.
Four Major Challenges: The Real Hard Parts of Feedback Loops
A feedback loop is far from just wrapping a while loop around "try again if it fails." It's a highly engineered subsystem with four major challenges standing in the way, each capable of making an otherwise smart-looking Agent crash and burn on the spot.
Challenge #1: Context Explosion
A single test run might produce thousands or tens of thousands of lines of log output. If the Agent stuffs all of that back into the model verbatim, the context blows up instantly — tokens are burned through, and the important information drowns in noise.
This relates to a core limitation of large language models: the context window. It refers to the maximum text length a model can process in a single inference, measured in tokens — GPT-4 Turbo supports 128K tokens, Claude 3.5 supports 200K tokens. But bigger isn't always better. On one hand, token consumption directly correlates with API call costs — stuffing massive logs into the context means real money spent. On the other hand, research has shown that models exhibit a "Lost in the Middle" phenomenon when processing very long contexts — information located in the middle of the input tends to be ignored by the model. This means even if the context window can technically fit all the logs, critical error messages might be buried in the middle and effectively "invisible" to the model.
So the Agent must be able to do one thing well: precisely extract the key lines from a flood of logs. Which specific test case failed? What file and line number is at the top of the error stack? What are the critical variable values? Keep those few lines, and ruthlessly discard the rest as noise.
The gap between an Agent that can extract key points and one that blindly stuffs everything back in is enormous.
Challenge #2: Symptom vs. Root Cause
This challenge tests real skill. The location pointed to by the error stack trace is often just the symptom, not the root cause.
Here's an analogy: the error is thrown in some utility function — that's where the red light is flashing — but the actual bug is that an upstream caller passed the wrong parameters. A poor Agent will fixate on where the red light is flashing and hack away at it, fixing the symptom while the root cause remains, making things worse with each attempt. A good Agent knows to trace back along the error stack, following the traceback layer by layer, to find the place that actually needs to be changed.
This capability corresponds to a mature methodology in software engineering — Root Cause Analysis (RCA). A classic RCA method is the "5 Whys": for each surface-level cause, ask "why did this happen," and keep asking through five layers — this usually gets you to the true root cause. In debugging scenarios, the stack trace is the most important source of clues: the top of the stack shows where the exception was thrown, but the real bug is often hidden in the middle or lower layers — the upstream parts of the call chain. For AI Agents, this requires the model to not only understand code in a single file but also possess cross-file, cross-module call chain tracing capabilities, understanding how data flows through the entire system, in order to upgrade from "seeing the symptom" to "finding the root cause."
Being able to distinguish symptoms from root causes is the dividing line between "can edit code" and "can fix bugs."
Challenge #3: Breaking Out of Death Loops
This is the most classic failure mode in feedback loops: fixing one thing breaks another; reverting that breaks a third thing. Back and forth like robbing Peter to pay Paul, never converging. This state is called oscillation.
Oscillation has deep theoretical roots in cybernetics. In classic PID controller design, if the feedback gain is set improperly, the system oscillates around the target value and never converges to a steady state. Similarly, in reinforcement learning, the phenomenon where an Agent repeatedly switches strategies between similar states is called "policy oscillation." The oscillation of coding Agents is fundamentally the same class of problem: each local fix changes the system state, causing previous fixes to break, forming circular dependencies. Understanding this is important — oscillation doesn't mean the Agent is "dumb"; it means the Agent lacks awareness of global state changes and only sees local cause-and-effect relationships.
A poor Agent gets trapped in this loop and can't escape, burning through your budget painfully. A good Agent needs self-awareness — the ability to recognize "I seem to be going in circles" — and then proactively break out of the loop, return to a higher level of planning, and reconsider whether its entire understanding of the problem was wrong from the start. This kind of "metacognition" mechanism requires the Agent to not only focus on the current error but also maintain a memory of its modification history, detecting whether it's repeating the same modification patterns.
Being able to break out matters far more than stubbornly grinding away.
Challenge #4: Knowing When to Stop
An Agent with a feedback loop that stubbornly believes "if I just keep retrying, I'll eventually fix it" is dangerous. It might run dozens of shell commands and rewrite code dozens of times without your knowledge, burning money while the problem remains unsolved.
So it must have brakes: loop count limits, cost caps, time budgets — the moment any of these three thresholds is hit, it stops and honestly asks the human for help.
A truly mature Agent isn't one that never gives up — it's one that knows when to hand the steering wheel back to you. Knowing when to stop is a capability in itself.
Real-World Example: Good vs. Bad Feedback Loops Compared
Suppose the task is to fix a consistently failing test: test_login_redirect.
A Bad Feedback Loop
Run test, it fails → model takes a wild guess: "maybe the redirect URL is wrong" → changes one line → runs again, still fails → "maybe the token isn't being passed" → changes another line → after several rounds, each change introduces a new problem → finally throws up its hands: "I tried a few approaches and none worked, you figure it out."
This is the classic guess → try → guess again → try again pattern.
A Good Feedback Loop
Run test, it fails → doesn't rush to change anything, first pinpoints the error stack to a specific file and line number → reads and understands who calls that code → examines what the test actually expects → discovers the expected redirect is /dashboard but it's actually going to /home → searches for where the redirect is configured → finds a constant that was recently changed → fixes it → runs again → passes → then runs related tests as well to confirm nothing else was broken.
One approach is "guessing." The other is read → locate → understand → fix → verify → cross-verify. The difference is night and day.
Engineering Takeaways: Two Practical Recommendations
Feedback Quality Determines Loop Quality
The quality of a feedback loop is heavily dependent on the quality of the tool feedback itself. If your project has terrible error messages, messy logs, and error codes that explain nothing, then no matter how smart the Agent's feedback loop is, it can't be saved — it simply can't read any useful clues.
So conversely, if you want your coding Agent to perform better, one extremely practical approach is to improve your project's own observability: clearer error messages, more informative logs, more standardized failure output. This benefits both humans and Agents alike.
Observability is a core concept that has emerged from the distributed systems operations field in recent years, built on three pillars: Logs, Metrics, and Traces. Google's SRE practices and CNCF's OpenTelemetry project are both driving the standardization of observability. For coding Agents, a project's observability level directly determines the ceiling of its feedback loop. Specifically: structured logs (e.g., JSON format) are much easier for Agents to parse and extract key information from than free-text logs; a clear error code system (with clear semantics like HTTP status codes) provides far more diagnostic information than a vague "Something went wrong"; comprehensive test coverage means more automated verification points, giving the Agent immediate feedback every time it changes code. This also explains why coding Agents typically perform better on mature open-source projects than on internal legacy systems — the former tend to have better engineering standards and richer feedback signals.
Feedback Loops Must Be Tightly Bound to Permission Boundaries
An Agent that can automatically retry might think "just a few more runs and it'll work," potentially running shell commands and rewriting code frantically without your knowledge. So it needs boundaries: loop count limits, cost caps, and mandatory human confirmation for critical operations. The stronger the automation capability, the more important the safety boundaries become.
Conclusion: From One-Shot Kills to Grinding It Out
The structure of a feedback loop is simple — observe, act, observe again. Its challenges are very real — context management, error localization, avoiding oscillation, knowing when to stop. But its value is immense: it enables an Agent to make progress on tasks in uncertain, real-world environments for the first time, rather than gambling everything on a single output.
Put simply, the feedback loop upgrades a coding Agent from "can only win with a one-shot kill" to "can grind it out." And once it can grind, the scope of problems it can handle expands dramatically:
- Simple tasks: done in one shot
- Medium tasks: completed in a few feedback rounds
- Complex tasks: multiple rounds of trial and error, multiple rollbacks, but still able to grind toward a deliverable state
This is the essential difference between a true coding Agent and a code generator.
Related articles
Claude Code Installation Guide & The Five Stages of AI Programming Tools Explained
Complete Claude Code installation guide with the five stages of AI programming tools, from manual coding to agents. Learn 0-to-1 project building and 1-to-100 iteration challenges.

Enterprise-Level AI Project Rules Files: 5 Hard Rules + 6 Writing Techniques
AI keeps messing up your code? Learn 5 hard rules and 6 writing techniques for enterprise-level Rules files in Claude Code, Cursor & more, with templates.
Building Cloud Computing Clusters from Old Phones: Google and UCSD Explore a New Path to Sustainable Computing
Google and UCSD explore building cloud clusters from old phones, leveraging ARM chip efficiency to cut e-waste and data center carbon footprints.