#token generation
14 related articles
·3 min
Hands-On Testing of DS4 Engine by Redis Creator: How Does DeepSeek V4 Perform Locally on a 128GB Mac?
Redis creator Antirez's DS4 inference engine tested: running DeepSeek V4 Flash locally on a 128GB Mac via asymmetric structure-aware quantization, with real-world coding benchmarks.
Read more →

·4 min
Core Methodology of Prompt Engineering: A Systematic Deep Dive from Principles to Practice
A deep dive into prompt engineering principles and core methodology. Master three keys to high-quality prompts: specific, rich, and unambiguous. Learn tuning techniques and advanced programming integration.
Read more →
StepFun STEP3.7 Flash Tops AA Benchmar…
·3 min
StepFun STEP3.7 Flash Tops AA Benchmark — Multimodal Reasoning Speed Takes Off
StepFun STEP3.7 Flash tops Artificial Analysis benchmark in speed, cost-efficiency, and multimodal. AI safety leaders call for legislation, embodied AI gets 300K-home training ground, Huawei Cloud unveils Agentic Infra.
Read more →
Tutorials
Firebase AI Logic in Practice: Buildin…
·2 min
Firebase AI Logic in Practice: Building Intelligent Task Decomposition from Scratch with AI Agents
Learn how to add intelligent task decomposition to a cross-platform to-do app using Firebase AI Logic and Gemini, covering structured output, App Check security, and server-side Prompt templates.
Read more →
 Tutorials
Tutorials·3 min
Ollama + Gemma 4 Local Codex Setup: Complete Guide to Zero-Cost AI Programming
Learn how to run Codex locally with Ollama and Gemma 4 for zero-cost AI programming. Covers installation, model selection, and real demos as an alternative to $20-200/month paid plans.
Read more →
 Expert Opinions
Expert Opinions·2 min
Delete Your CLAUDE.md: Research Shows Agent Config Files Are Hurting AI Coding
Research shows CLAUDE.md and AGENTS.md config files reduce AI coding performance by 3% and increase costs by 20%. Learn why less is more for AgentMD.
Read more →
 Tutorials
Tutorials·4 min
Core Methodology of Prompt Engineering: Principles, Techniques, and Complete Practical Guide
Deep analysis of Prompt Engineering core methodology: from LLM principles to the three key principles of specific, rich, and unambiguous prompts, plus programming advantages in the AI era.
Read more →
 Tutorials
Tutorials·3 min
llama.cpp MTP Acceleration Deployment Guide: Configuration Steps & Real-World Benchmarks
Guide to enabling MTP multi-Token prediction acceleration in llama.cpp, covering CUDA setup, desktop configuration, model selection, and benchmarks showing ~60 Token/s with Qwen3 27B.
Read more →
 Product Reviews
Product Reviews·3 min
GPT-5.1 Deep Dive: 10 Core Features That Transform AI from Chat Tool to Work Partner
Deep dive into GPT-5.1's 10 core feature upgrades including dual-mode switching, project agents, coding assistance, tool orchestration, and 24-hour prompt caching to boost your productivity.
Read more →
 Tutorials
Tutorials·3 min
oMLX + MTP + Qwen3.6: Local AI Coding Speed Breaks New Records
Using oMLX with MTP and Qwen3.6 35B on Apple Silicon Mac to achieve 86.7 tokens/s local coding speed, building a full-stack app in under 5 minutes.
Read more →
 Research
Research·2 min
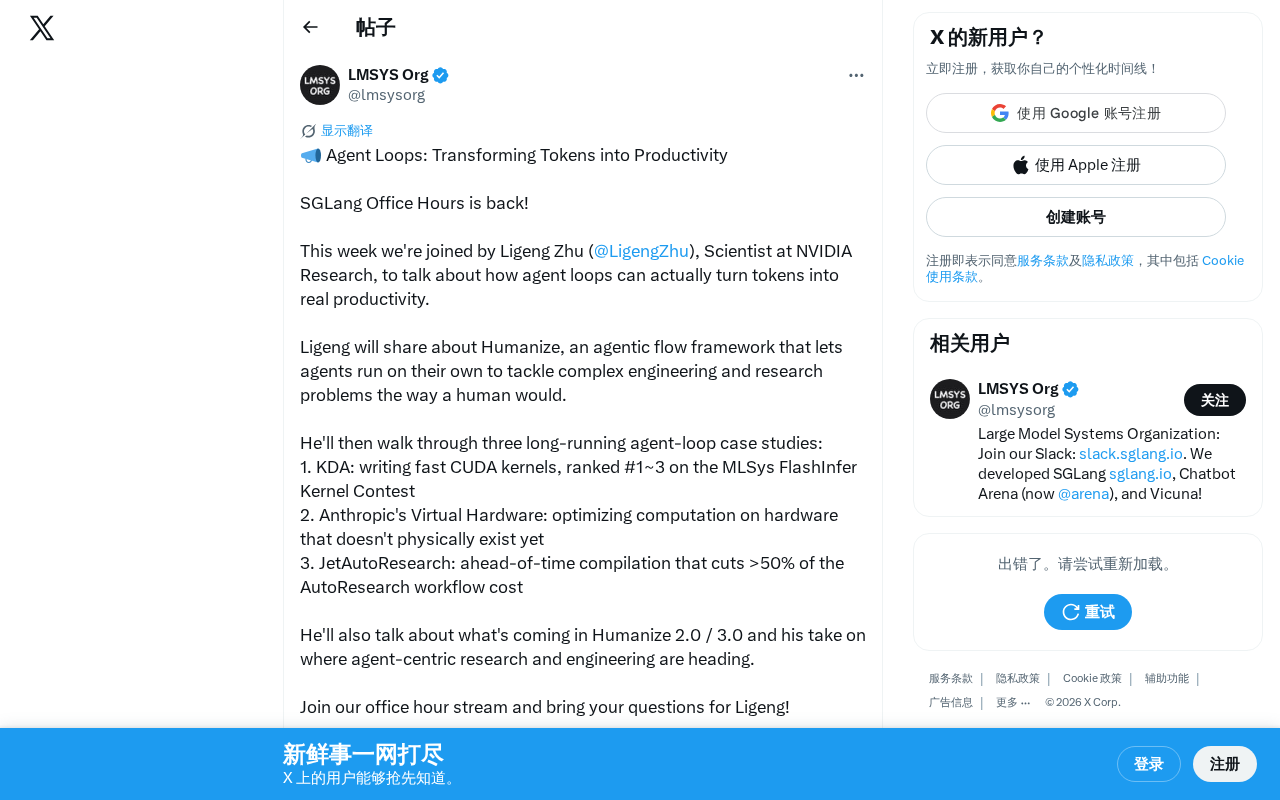
Agent Loops in Practice: Transforming Token Output into Productivity from CUDA Kernels to Automated Research
Deep dive into how the Humanize framework transforms LLM tokens into engineering productivity via Agent Loops. Covers KDA winning CUDA kernel contests, virtual hardware optimization, and 50% research cost reduction.
Read more →
 Tutorials
Tutorials·2 min
Tutorial: Deploying a PD-Disaggregated SGLang Multi-Node Inference Cluster on AMD GPUs
Learn how to deploy a PD-disaggregated SGLang inference cluster on AMD GPUs using a single config file, boosting LLM throughput and latency performance.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
SGLang Hosts Agent Loops Office Hour, Focusing on Agentic Loop Architecture Optimization
SGLang team hosts an Agent Loops Office Hour exploring inference optimization for agentic loops, covering KV Cache reuse, low-latency multi-turn dialogue, and tool calling techniques.
Read more →
 Product Reviews
Product Reviews·3 min
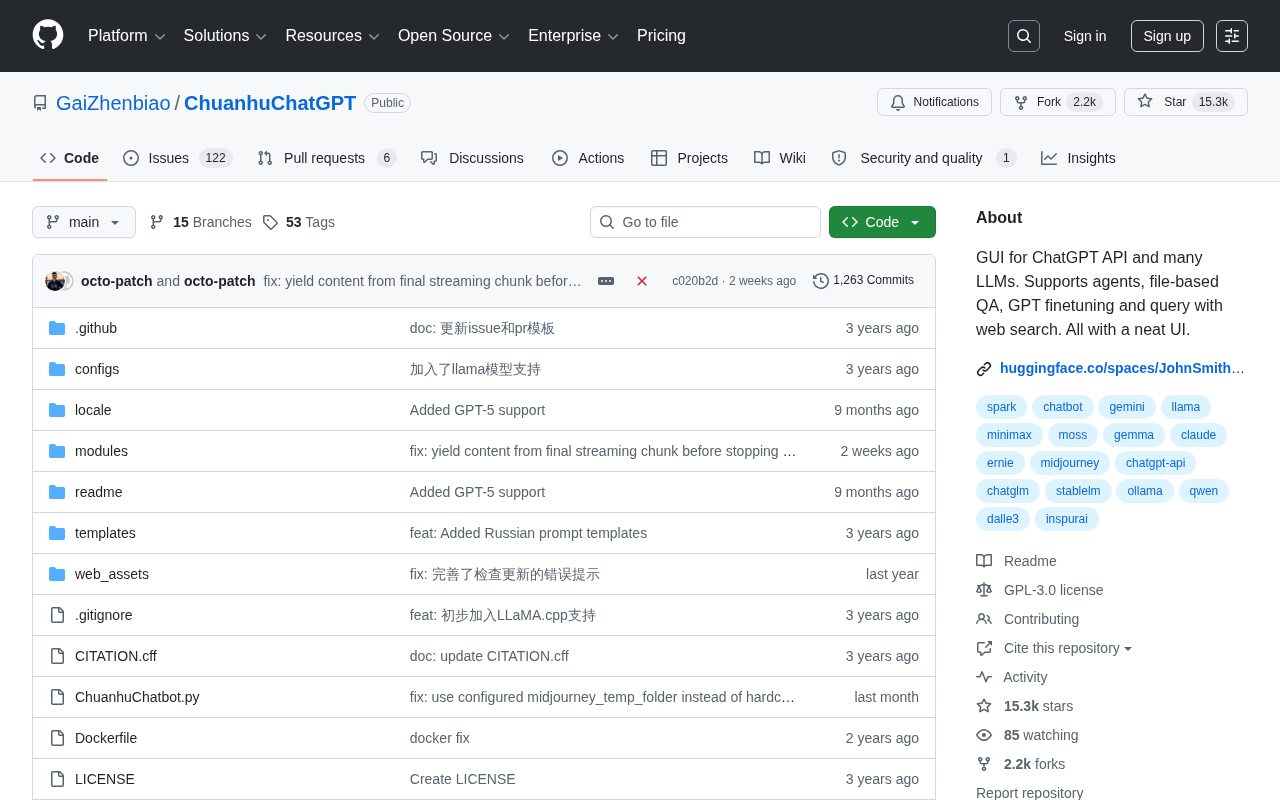
ChuanhuChatGPT: A Comprehensive Analysis of the 15K-Star Open-Source Multi-Model Chat Interface
Deep dive into ChuanhuChatGPT, a 15K-star open-source project with multi-model access, Agent support, RAG file Q&A, GPT fine-tuning, and web search.
Read more →